前端性能优化-基础知识
我们访问一个页面的时候都做了什么
问题1:当我们访问一个站点,浏览器背后做了什么?
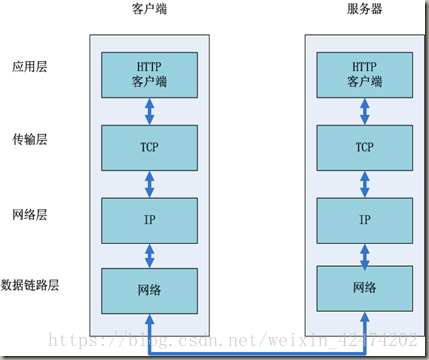
互联网内各网络设备间的通信都遵循TCP/IP协议,利用TCP/IP协议族进行网络通信时,会通过分层顺序与对方进行通信。TCP/IP四层模型由高到低分别为:应用层、传输层、网络层、数据链路层。发送端从应用层往下走,接收端从数据链路层网上走。如图所示:
以访问 www.baidu.com 为例分析:
第一步:浏览器接收url
这一步没什么说的
第二步:查看 Cache
接收url后:
浏览器按如下顺序 浏览器缓存=>系统缓存=>路由器缓存查看页面是否存在有效缓存,如果存在,会直接调用缓存内容显示。若没有,则下一步。
第三步:应用层 DNS 域名解析
操作系统会先检查本地hosts文件是否有这个网址映射关系,如果有就调用这个IP地址映射,完成域名解析。
否则,查找本地DNS服务器,如果查找到则返回。
否则:
1)未用转发模式:按根域服务器 => 顶级域.com(顶级域又名一级域名) => 二级域example.com => 三级域www.example.com的顺序找到IP地址。
2)已用转发模式:按上一级DNS服务器 =>上上级 => 逐级向上查询找到IP地址。
基础补充-------------------------------------
什么叫作本地DNS服务器?本地是一个相对概念,并不是你自己的计算机
DNS是计算机域名系统 (Domain Name System 或Domain Name Service) 的缩写,它是由域名解析器和域名服务器组成的。域名服务器是指保存有该网络中所有主机的域名和对应IP地址,并具有将域名转换为IP地址功能的服务器。其中域名必须对应一个IP地址,一个域名可以有多个IP地址,而IP地址不一定有域名。域名系统采用类似目录树的等级结构。域名服务器为客户机/服务器模式中的服务器方,它主要有两种形式:主服务器和转发服务器。将域名映射为IP地址的过程就称为“域名解析”。
DNS服务器在域名解析过程中的查询顺序为:本地缓存记录、区域记录、转发域名服务器、根域名服务器。本地是一个相对的概念,因为DNS服务是有很多级的,所以更靠近用户的那级服务器就叫做本地DNS服务器。比如114和8.8.8.8这样的DNS服务器处于根服务器之下所以可以算作是本地DNS服务,很多运营商都会在当地架设自己的DNS服务器储存着常用的域名映射,用来为用户提供更快的域名解析服务。
----------摘自百度百科
第四步:建立TCP连接 (三次握手)
TCP连接是发生在TCP/IP 四层模型的传输层,浏览器向服务器发起tcp连接,与浏览器建立tcp三次握手。
第五步:应用层发送 HTTP Request
握手成功后,浏览器通过应用层向服务器发送 HTTP 请求报文
HTTP请求报文构成
一个HTTP请求报文由
请求行(request line)、请求头部(header)、空行和请求主体4个部分组成,下图给出了请求报文的一般格式。
<request-line> 请求行
<headers> 请求头
<blank line> 空行
<request-body> 请求数据
GET /search?hl=zh-CN&source=hp&q=domety&aq=f&oq= HTTP/1.1 Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-silverlight, application/x-shockwave-flash, / Referer: http://www.google.cn/ Accept-Language: zh-cn Accept-Encoding: gzip, deflate User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; TheWorld) Host: www.google.cn Connection: Keep-Alive Cookie: PREF=ID=80a06da87be9ae3c:U=f7167333e2c3b714:NW=1:TM=1261551909:LM=1261551917:S=ybYcq2wpfefs4V9g; NID=31=ojj8d-IygaEtSxLgaJmqSjVhCspkviJrB6omjamNrSm8lZhKy_yMfO2M4QMRKcH1g0iQv9u-2hfBW7bUFwVh7pGaRUb0RnHcJU37y- FxlRugatx63JLv7CWMD6UB_O_r
后端从在固定的端口接收到TCP报文开始,它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。
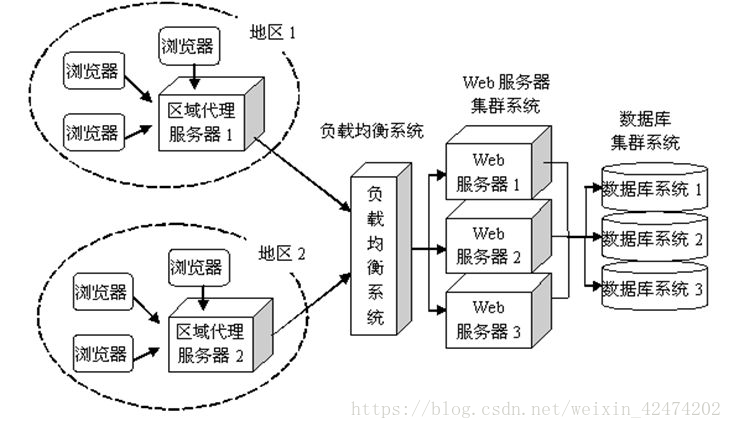
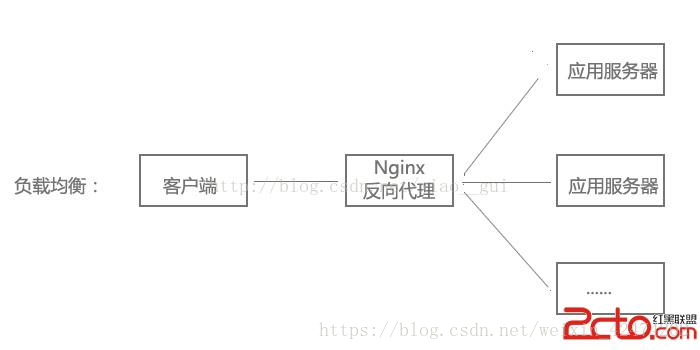
一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过HTTP协议访问某网站应用服务器,而是先请求到Nginx,Nginx再请求应用服务器,然后将结果返回给客户端,这里Nginx的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
通过Nginx的反向代理,我们到达了web服务器,服务端脚本处理我们的请求,访问我们的数据库,获取需要获取的内容等等,当然,这个过程涉及很多后端脚本的复杂操作。
扩展阅读:
1)什么是反向代理?
客户端本来可以直接通过HTTP协议访问某网站应用服务器,网站管理员可以在中间加上一个Nginx,客户端请求Nginx,Nginx请求应用服务器,然后将结果返回给客户端,此时Nginx就是反向代理服务器。
第六步:服务器返回一个Response
经过前面的几个步骤,服务器收到了我们的请求,也处理我们的请求,到这一步,它会把它的处理结果返回,也就是返回一个HTPP响应。
HTTP响应与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
- 状态行 (首行)
- 响应头 (Response Header)
- 响应正文
HTTP/1.1 200 OK Date: Sat, 31 Dec 2005 23:59:59 GMT Content-Type: text/html;charset=ISO-8859-1 Content-Length: 122 <html> <head> <title>http</title> </head> <body> <!-- body goes here --> </body> </html>
状态行
状态行由:协议版本(http/1.1)、三位数的状态码(Status Code:200)、及相应的状态描述(OK),这三者之间空格分割,
状态行结尾必须换行。
响应头
响应头部:由关键字/值对组成,每行一对,关键字和值用英文冒号”:”分隔,典型的响应头有:
IwMg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
响应正文
包含着我们需要的一些具体信息,比如cookie,html,image,后端返回的请求数据等等。这里需要注意,响应正文和响应头之间有一空行,表示响应头的信息到空行为止。
第七步:浏览器解析渲染页面并显示
服务器返回的是静态的 html 文件,然后浏览器再通过 html 的内容,判断需要哪些
外部媒体资源、css资源(外部js比较突入特殊:默认是同步加载),浏览器再向服务器发起异步请求,然后对返回的内容进行解析,所以我们最终看到的页面就是丰富多彩的效果了。
在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了,浏览器是如何把页面呈现在屏幕上的呢?不同浏览器可能解析的过程不太一样,这里我们只介绍webkit的渲染过程,下面对应的就是WebKit渲染的过程,这个过程包括:
**解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树**
浏览器在解析html文件时,会自上而下加载,并在加载过程中进行解析渲染。在解析过程中,如果遇到请求外部资源时,如图片、外链的CSS、iconfont等,请求过程是异步的,并不会影响html文档进行加载。
解析过程中,浏览器首先会解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repaint(重绘)。
DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为reflow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repaint。
页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repaint。
当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。因为JS有可能会修改DOM,最为经典的document.write,这意味着,在JS执行完成前,后续所有资源的下载可能是没有必要的,这是js阻塞后续资源下载的根本原因。所以我明平时的代码中,js是放在html文档末尾的。
JS的解析是由浏览器中的JS解析引擎完成的,比如谷歌的是V8。JS是单线程运行,也就是说,在同一个时间内只能做一件事,所有的任务都需要排队,前一个任务结束,后一个任务才能开始。但是又存在某些任务比较耗时,如IO读写等,所以需要一种机制可以先执行排在后面的任务,这就是:同步任务(synchronous)和异步任务(asynchronous)。
JS的执行机制就可以看做是一个主线程加上一个任务队列(task queue)。同步任务就是放在主线程上执行的任务,异步任务是放在任务队列中的任务。所有的同步任务在主线程上执行,形成一个执行栈;异步任务有了运行结果就会在任务队列中放置一个事件;脚本运行时先依次运行执行栈,然后会从任务队列里提取事件,运行任务队列中的任务,这个过程是不断重复的,所以又叫做事件循环(Event loop)。
第八步:TCP关闭连接
现在的页面为了优化请求的耗时,默认都会开启持久连接(keep-alive),那么一个TCP连接确切关闭的时机,是这个tab标签页关闭的时候。这个关闭的过程就是著名的四次挥手。关闭是一个全双工的过程,发包的顺序的不一定的。一般来说是客户端主动发起的关闭,过程如下。
假如最后一次客户端发出的数据seq = x, ack = y;
客户端发送一个FIN置为1的包,ack = y, seq = x + 1,此时客户端的状态为 FIN_WAIT_1
服务端收到包后,状态切换为CLOSE_WAIT发送一个ACK为1的包, ack = x + 2。客户端收到包之后状态切换为FNI_WAIT_2
服务端处理完任务后,向客户端发送一个 FIN包,seq = y; 同时将自己的状态置为LAST_ACK
客户端收到包后状态切换为TIME_WAIT,并向服务端发送ACK包,ack = y + 1,等待2MSL后关闭连接。
为什么客户端等待2MSL?
MSL: 全程Maximum Segment Lifetime,中文可以翻译为报文最大生存时间。
等待是为了保证连接的可靠性,确保服务端收到ACK包,如果服务端没有收到这个ACK包,将会重发FIN包给客户端,而这个时间刚好是服务端等待超时重发的时间 + FIN的传输时间。
补充三个基础概念:
- URL (Uniform Resource Location ) 统一资源定位符
- URI (Uniform Resource Identifier ) 统一资源标识符
- URN (Uniform Resource Name ) 统一资源名称
通用的不一定适合我们
1
我们要到底优化什么
1
阅读更多
- 前端性能优化基础知识--幕课网
- 前端性能优化的基础知识
- 【前端-webpack】webpack性能基础优化
- 前端性能优化基础
- C语言性能优化与基础知识
- 服务器性能优化基础知识
- [基础知识] 总结使用Unity 3D优化游戏运行性能的经验
- JS基础知识补充和性能优化知识学习(CHROME小技巧)
- linux性能优化1-进程相关基础知识
- 性能优化系统学习(一):基础知识
- 前端性能优化-基础认知
- 性能优化系统学习(一):基础知识
- 前端性能优化-基础认知
- H5前端性能优化之预加载知识
- 前端性能优化知识,包括css和js
- 前端性能优化知识,包括css和js
- 前端性能优化基础 -- 图片加载方式
- Java软件开发基础知识梳理之(3)------JDCB操作数据库性能优化策略
- 漫谈Java程序的性能优化-Java基础-Java-编程开发
- 性能优化基础