GroupBy技术-----python进行数据分析
2018-10-19 10:35
357 查看
GroupBy技术
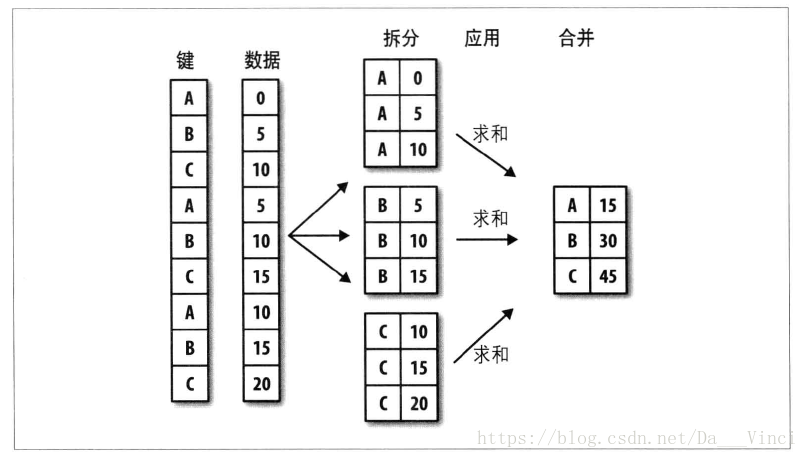
[code]>>> import numpy as np
>>> from pandas import DataFrame,Series
Backend TkAgg is interactive backend. Turning interactive mode on.
>>> df = DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one','two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
>>> df
data1 data2 key1 key2
0 -1.012239 0.381608 a one
1 0.432161 -1.384340 a two
2 0.426435 -1.732019 b one
3 -1.388080 0.839690 b two
4 -0.439888 -0.603553 a one
>>> grouped = df['data1'].groupby(df['key1'])
>>> grouped.mean()
key1
a -0.339989
b -0.480822
Name: data1, dtype: float64
[code]>>> means = df['data1'].groupby([df['key1'],df['key2']]).mean() >>> means key1 key2 a one -0.726064 two 0.432161 b one 0.426435 two -1.388080 Name: data1, dtype: float64 >>> means.unstack() key2 one two key1 a -0.726064 0.432161 b 0.426435 -1.388080
直接使用列名作为分组键
[code]>>> df.groupby('key1').mean()
data1 data2
key1
a -0.339989 -0.535428
b -0.480822 -0.446165
>>> df.groupby(['key1','key2']).size()
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组。
[code]>>> for name,group in df.groupby('key1'):
... print name
... print group
...
a
data1 data2 key1 key2
0 -1.012239 0.381608 a one
1 0.432161 -1.384340 a two
4 -0.439888 -0.603553 a one
b
data1 data2 key1 key2
2 0.426435 -1.732019 b one
3 -1.388080 0.839690 b two
对于多重键情况,元组的第一元素是由键值组成的元组:
[code]>>> for(k1,k2),group in df.groupby(['key1','key2']): ... print k1,k2 ... print group ... a one data1 data2 key1 key2 0 -1.012239 0.381608 a one 4 -0.439888 -0.603553 a one a two data1 data2 key1 key2 1 0.432161 -1.38434 a two b one data1 data2 key1 key2 2 0.426435 -1.732019 b one b two data1 data2 key1 key2 3 -1.38808 0.83969 b two
你可以对这些数据片段做任何操作,比如把他们当成一个字典
[code]>>> pieces = dict(list(df.groupby('key1')))
>>> pieces['b']
data1 data2 key1 key2
2 0.426435 -1.732019 b one
3 -1.388080 0.839690 b two
>>> pieces['a']
data1 data2 key1 key2
0 -1.012239 0.381608 a one
1 0.432161 -1.384340 a two
4 -0.439888 -0.603553 a one
groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组
[code]>>> df.dtypes
data1 float64
data2 float64
key1 object
key2 object
dtype: object
>>> grouped = df.groupby(df.dtypes,axis=1)
>>> dict(list(grouped))
{dtype('O'): key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one, dtype('float64'): data1 data2
0 -1.012239 0.381608
1 0.432161 -1.384340
2 0.426435 -1.732019
3 -1.388080 0.839690
4 -0.439888 -0.603553}
选取一个或一组列
对于大数据集很可能只需对部分列进行聚合,例:
[code]>>> df.groupby(['key1','key2'])[['data2']].mean() data2 key1 key2 a one -0.110972 two -1.384340 b one -1.732019 two 0.839690 >>> s_grouped = df.groupby(['key1','key2'])['data2'] >>> s_grouped.mean() key1 key2 a one -0.110972 two -1.384340 b one -1.732019 two 0.839690 Name: data2, dtype: float64
通过字典或Series进行分组
[code]>>> people = DataFrame(np.random.randn(5,5),columns=['a','b','c','d','e'],index=['Joe','Steve','Wes','Jim','Travis']) >>> people.ix[2:3,['b','c']] = np.nan >>> people a b c d e Joe -0.507204 1.111102 -1.626998 -1.191771 0.386699 Steve 1.225585 1.202014 0.089095 0.004328 -0.660203 Wes -0.641992 NaN NaN -1.612848 0.327813 Jim 1.271822 -0.117422 0.919063 -0.254136 -0.957631 Travis 0.690725 -1.098159 -0.757635 -0.794666 -1.297784
[code]>>> mapping = {'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
>>> by_column = people.groupby(mapping,axis=1)
>>> by_column.sum()
blue red
Joe -2.818768 0.990597
Steve 0.093423 1.767396
Wes -1.612848 -0.314179
Jim 0.664926 0.196769
Travis -1.552301 -1.705217
[code]>>> map_series = Series(mapping) >>> map_series a red b red c blue d blue e red f orange dtype: object >>> people.groupby(map_series,axis=1).count() blue red Joe 2 3 Steve 2 3 Wes 1 2 Jim 2 3 Travis 2 3
通过函数进行分组
[code]>>> import numpy as np >>> from pandas import DataFrame,Series Backend TkAgg is interactive backend. Turning interactive mode on. >>> people = DataFrame(np.random.randn(5,5),columns=['a','b','c','d','e'],index=['Joe','Steve','Wes','Jim','Travis']) >>> people.ix[2:3,['b','c']] = np.nan >>> people.groupby(len).sum() a b c d e 3 2.080547 -0.604547 -0.604366 -1.513836 0.497836 5 0.079461 -1.729398 -0.901477 0.569260 0.302427 6 0.005069 -0.035869 -0.793810 1.150144 2.031785 >>> people a b c d e Joe 1.119423 -0.345290 0.668423 -0.658008 0.413723 Steve 0.079461 -1.729398 -0.901477 0.569260 0.302427 Wes -0.556755 NaN NaN -0.992753 0.124015 Jim 1.517879 -0.259257 -1.272789 0.136925 -0.039903 Travis 0.005069 -0.035869 -0.793810 1.150144 2.031785
下例:先按长度分组,然后是one,two的分组
[code]>>> key_list = ['one','one','one','two','two'] >>> people.groupby([len,key_list]).min() a b c d e 3 one -0.556755 -0.345290 0.668423 -0.992753 0.124015 two 1.517879 -0.259257 -1.272789 0.136925 -0.039903 5 one 0.079461 -1.729398 -0.901477 0.569260 0.302427 6 two 0.005069 -0.035869 -0.793810 1.150144 2.031785
根据索引级别分组
[code]>>> columns = pd.MultiIndex.from_arrays([['US','US','US','JP','JP'],[1,3,5,1,3]],names = ['cty','tenor']) >>> hier_df = DataFrame(np.random.randn(4,5),columns = columns) >>> hier_df cty US JP tenor 1 3 5 1 3 0 0.839657 0.656362 1.034138 -1.107702 0.687075 1 0.979355 0.581277 1.024826 -0.617576 0.117190 2 0.579184 -0.629204 1.849724 -0.738685 -1.937523 3 0.168968 -0.352462 -0.791173 -0.628160 0.391682 >>> hier_df.groupby(level='cty',axis=1).count() cty JP US 0 2 3 1 2 3 2 2 3 3 2 3
阅读更多

相关文章推荐
- Python数据分析中Groupby用法之通过字典或Series进行分组的实例
- 利用Python进行数据分析——时间序列[十](1) .
- 利用Python进行数据分析 笔记4
- 利用python调用elasticsearch-api来分析数据并作图进行日报邮件发送
- Python数据分析:pandas中Dataframe的groupby与索引
- 读《利用 Python 进行数据分析》pdf
- 利用Python 进行数据分析 ch02
- 利用Python进行数据分析——第8章绘图及可视化——学习笔记Python3 5.0.0
- 程序员怎么获取股票实时数据,并进行技术指标分析呢?
- 利用elasticsearch的python模型进行日志数据分析
- python数据聚合-----python进行数据分析
- 利用Python进行数据分析 笔记1
- 利用python进行数据分析读书笔记
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(5) .
- 利用python进行数据分析-NumPy高级应用
- Python进行数据分析(二)MovieLens 1M 数据集
- 利用python进行数据分析-时间序列1
- 利用python进行数据分析——Numpy基础(一)
- 利用python调用elasticsearch-api来分析数据并作图进行日报邮件发送
- Python数据分析与机器学习-使用Kmeans进行图像压缩