【持续更新】图像分类、物体检测、物体分割、实例分割、语义分割的区别
2018-10-09 22:42
483 查看
Directions in the CV
- 物体分割(Object segment)属于图像理解范畴。那什么是图像理解?Image Understanding (IU) 领域包含众多sub-domains,如图像分类、物体检测、物体分割、实例分割等若干问题。每个问题研究的范畴是什么?每个问题中,各个approach对应的the result of processing是什么?
- Image Understanding (IU) is an interdisciplinary approach which fuse computer science, mathematics, engineering science, physics, neurosciences, and cognitive science etc. together.
- 一般我们将CV分为三个大方向:图像处理、图像分析、图像理解。其中图像理解分为以下三个部分
- Image Classification:
即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。其中ImageNet是最权威的测评集,每年的ILSVRC催生大量优秀的深度网络结构,为其他任务提供基础,在应用领域,人脸、场景识别都可以视为分类任务。 - Detection
分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置,常用矩形检测框的坐标表示。 - Segmentation
分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
后期我会写CV综述,此处留坑占位!
也会对object segmentation的方法进行总结,占坑!
Image Classification
- The task of object classification requires binary labels indicating whether objects are present in an image.
- Definition:Image Classification根据image中不同图像信息中不同的feature,把不同类别的object region进行分类。
- 该任务需要我们对出现在某幅图像中的物体做标注。
- 例如:一共有1000个物体类的image中,某个物体要么有,要么没有。可实现:输入一幅测试图片,输出该图片中物体类别的候选集。如下图所示,不同形状的图形,通过分类分成了8类

Object localization (目标定位)
- 在图像分类的基础上,我们还想知道图像中的目标具体在图像的什么位置,通常是以边界框的(bounding box)形式。
- 基本思路
- 多任务学习,网络带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记bounding box位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。
- 人体位姿定位/人脸定位
目标定位的思路也可以用于人体位姿定位或人脸定位。这两者都需要我们对一系列的人体关节或人脸关键点进行回归。 - 弱监督定位
由于目标定位是相对比较简单的任务,近期的研究热点是在只有标记信息的条件下进行目标定位。其基本思路是从卷积结果中找到一些较高响应的显著性区域,认为这个区域对应图像中的目标。
Object detection(目标检测)
- Detecting an object entails both stating that an object belonging to a specified class is present, and localizing it in the image. The location of an object is typically represented by a bounding box.
- 理解:object detection=classification+localization
- 定义:物体探测包含两个问题,一是判断属于某个特定类的物体是否出现在图中;二是对该物体定位,定位常用表征就是物体的边界框(bounding box)。
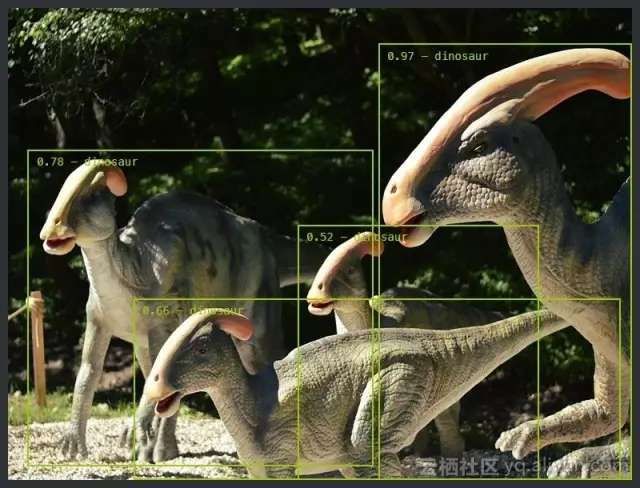
- 可实现:输入测试图片,输出检测到的物体类别和位置。如下图,移动的皮卡丘和恐龙
-

语义分割(Semantic Segmentation)
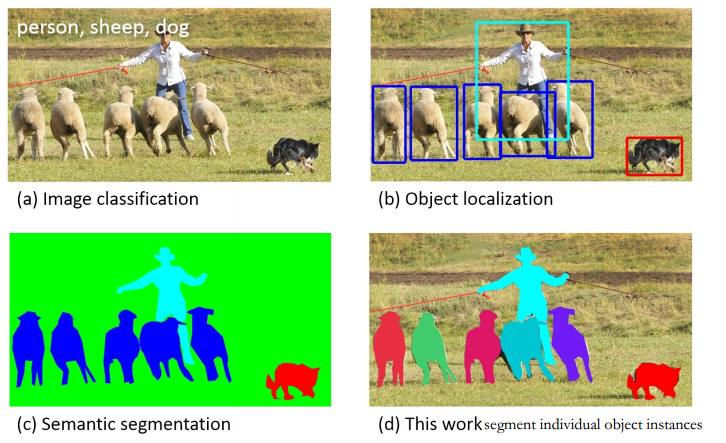
- The task of labeling semantic objects in a scene requires that each pixel of an image be labeled as belonging to a category, such as sky, chair, floor, street, etc. In contrast to the detection task, individual instances of objects do not need to be segmented.
- 语义标注(Semantic scene labeling)/分割(segmentation):该任务需要将图中每一点像素标注为某个物体类别。同一物体的不同实例不需要单独分割出来。
- 例如:gif图中将不同的类用相同的颜色进行标注,并不会把多辆车标注成车1、车2、车3…

Instance segmentation
- instance segment = object detect +semantic segment
- 相对物体检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割可以标注出图上同一物体的不同个体
- 分类任务通常来说就是识别出包含单个对象的图像是什么,但在分割实例时,我们需要执行更复杂的任务。我们会看到多个重叠物体和不同背景的复杂景象,我们不仅需要将这些不同的对象进行分类,而且还要确定对象的边界、差异和彼此之间的关系!
- 如下图所示,把不同的实例对象进行了分割,并用不同的颜色进行边缘标注(而不是边框标注)

Some examples
综述
图像理解领域中的object segmentation方向包括了:image classification、object localization、object detection、semantic segmentation、instance-level segmentation。分类复杂度依次递增,分类详细程度依次递增。
若干参考资料:
阅读更多
相关文章推荐
- 图像分类,物体检测,语义分割,实例分割的联系和区别
- 图像分类,物体检测,语义分割,实例分割等概念
- 图像分类,物体检测,语义分割,实例分割
- 干货丨计算机视觉必读:图像分类、定位、检测,语义分割和实例分割方法梳理(经典长文,值得收藏)
- 【机器视觉】计算机视觉必读:图像分类、定位、检测,语义分割和实例分割方法梳理
- 图像分类、检测,语义分割等方法梳理
- (Slide)CNN图像分类与物体检测
- 实例分割和语义分割的区别
- 论文解析:基于深度卷积神经网络的城市遥感图像小物体语义分割及不确定性建模
- 计算机视觉(图像分类、检测、分割)数据集和比赛
- 图像识别中,目标分割、目标识别、目标检测和目标跟踪这几个方面区别是什么?+资料列表
- 图像物体分类与检测算法综述
- 常用图像数据集大全(分类,跟踪,分割,检测等)
- 常用图像数据集大全(分类,跟踪,分割,检测等)
- paper 111:图像分类物体目标检测 from RCNN to YOLO
- 常用图像数据集大全(分类,跟踪,分割,检测等)
- 常用图像数据集大全(分类,跟踪,分割,检测等)
- 语义分割与实例分割的区别
- 语义分割与实例分割的区别
- 后RCNN时代的物体检测及实例分割进展