深度学习高速路上,PaddlePaddle正在弯道超车
深度学习是机器学习中一种基于对数据进行表证学习的方法,近些年不断发展并广受欢迎。研究热潮的持续高涨,带来各种开源深度学习框架层出不穷,其中包括TensorFlow、Caffe、Keras、CNTK、Torch7、MXNet、Leaf、PaddlePaddle、Theano、DeepLearning4、Lasagne、Neon等,在此背景下,PaddlePaddle如何在这条深度学习的高速路上弯道超车,看PaddlePaddle架构师潘欣如何解答。

以下为潘欣老师演讲实录
借助传统编程语言理念的全功能深度学习框架
PaddlePaddle是国内唯一的开源深度学习平台,由百度自主研发并具备完全的自主核心技术和知识产权,支持从建模、网络、强化学习、语音识别到最后部署的全部环节,具有易学、易用、安全、高效等特点,是全功能的深度学习框架。

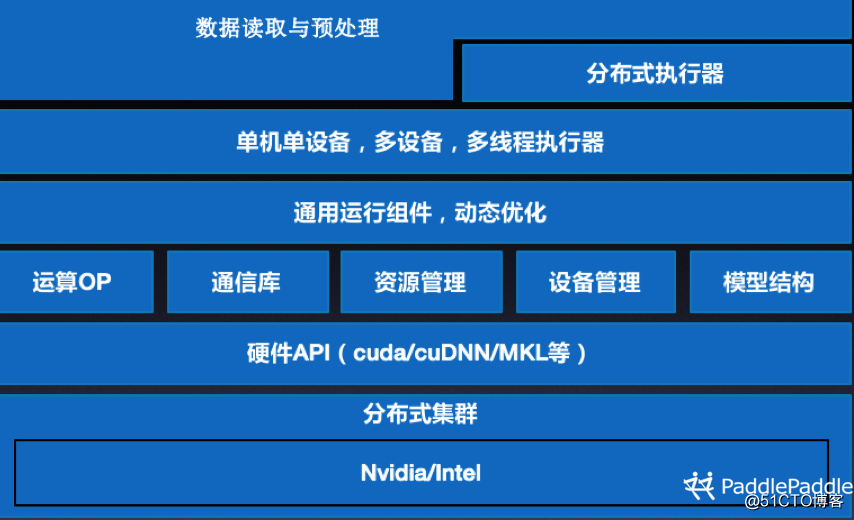
图一 PaddlePaddle核心框架结构
PaddlePaddle的核心架构如图所示,它的整体运行流程是通过API接口组输入/输出网络,并在底层做统一转化,然后通过Runtime进行训练,最后转换成线上部署的模型。线上部署分为服务端和移动端,为应对不同体系平台、能耗的要求,我们部署不同的设备。
其中左侧第一层是API接口,它采用Python语言编写,大致分为两大类,一类是组网类API,包括控制逻辑、构成逻辑、计算逻辑、IO的模块、读取数据的模块等;另一类是执行类底层API,把用户组好的模型进行分析,并将计算方法进行合并优化,以此提高训练速度。
除此之外,对于API的组网,PaddlePaddle还有一些新特性。众所周知,目前很多的框架是在用户层暴露出来一个图的接口,以此进行组网。但我们认为,大多数的程序员更熟悉的是传统的如变量、block的流式程序的概念,而不是通过一个图去连接算子、编写模型。所以在PaddlePaddle API接口的设计中,我们使用了这些传统编程语言的理念,使得最终编写更类似于传统编程语言。
组网类API
组网类API包含通用、控制、计算、优化、IO等类型的API。
Variables:PaddlePaddle中的变量,可以是Tensor、 Parameter,或RPCClient。概念类似高级语言中的变量,有不同类型。
Layers:PaddlePaddle中用户配置模型的基础模块,Layer表示一个或者一组紧密关联的计算,Layers可以通过输入输出连接起来。
Block:Block表示一组连续的计算逻辑,通常是一个或多个顺序Layer组成。通常主模型是一个Block0。另外在Control Flow中,比如While、Iflese,也会单独形成一个子Block。
Control Flow:PaddlePaddle支持If-else、While、Switch等编程语言中常见的Control Flow,以确保模型的灵活表达。Control Flow通常以Block的形式存在。
Program:包含了1个或者多个Block,表示一个完整的模型执行单元。执行器需要完整的执行Program,并保证读写关系符合用户的预期。
执行类API


示例
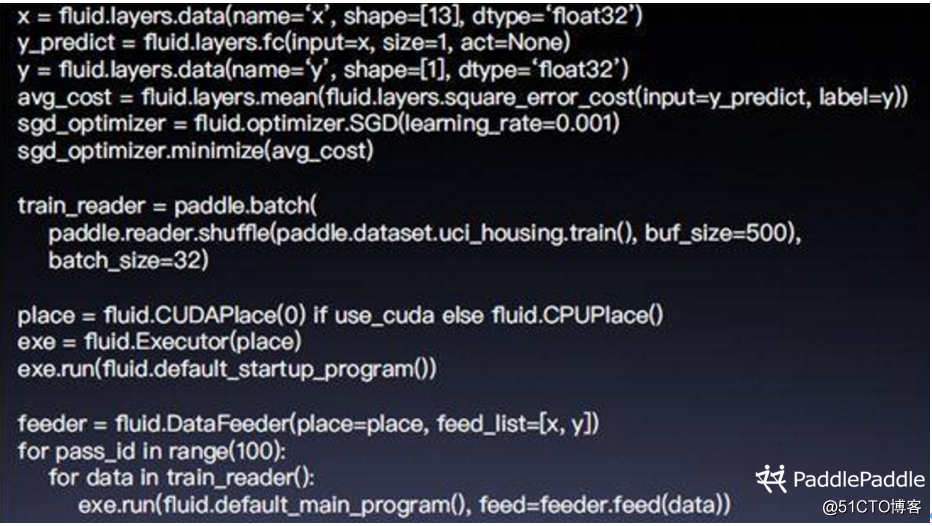
训练Runtime
多卡并行-SSA Graph
将模型Program转换成一个可并发执行的Intermediate Representation(IR);利用Static Single Assignment为Variable加Version,得到一个正确的依赖关系;Build Pass中插入通信节点和额外的依赖关系。
基于图依赖的执行:Input ready的所有Operator可以并发执行;Operators在多个GPU上数据并行执行;多卡Gradient聚合,确保数据并行中参数一致。

多卡并行-Profile
多机分布式
多机分布式支持Ring、Pserver两种模式。
Ring:自动插入多机Communicator,多机同步训练,支持高性能RDMA通信。
Pserver:拆分成Trainer Program和PserverProgram。支持同步和异步的分布式训练。Trainer端多线程异步发送Gradient;Pserver端多线程异步Apply Optimization。
用户Focus Modeling, 框架自动多机化部署:
发现Optimizer Operators、Parameters、Gradients。
Split和Assign到Parameter Server上。
在Trainer和Parameter Server上插入发送和接收的通信节点。
生成在Trainer执行的Program。
生成在Parameter Server执行的Program。
多机分布式的通信和集群
支持MPI、RPC等通信方式。
RPC将来会换成Brpc,并提供原生的RPC+RDMA支持,极大提高通信效率。
支持Kubernetes集群部署。
多机分布式下的容错
Trainer或者PserverFailure后可以重启恢复训练。即将支持Pserver端的分布式CheckPoint和恢复,支持大规模Embedding。
大规模稀疏数据分布式模型训练
在互联网场景中,亿级的用户每天产生着百亿级的用户数据,百度的搜索和推荐系统是大规模稀疏数据分布式模型训练的主要应用场景。
如何利用这些数据训练出更好的模型来给用户提供服务,对机器学习框架提出了很高的要求。主要包括:
样本数量大,单周20T+。
特征维度多达千亿甚至万亿。
T级别,参数大。
小时级更新,时效要求高。
注:文中所提架构基于PaddlePaddle 0.14版本,未来,会发出更为稳定的新版本,欢迎大家关注
提问环节
提问:在分布式训练的时候,有同步和异步两种,什么时候适合用同步,什么时候适合用异步?
潘欣:目前没有机械化的方法确定这个问题,但是有一些经验可以跟大家分享。如在图像这个领域用同步更稳定,还有最近的翻译模型,也是通过同步的方法训练。当然,并不是说同步一定比异步好。根据过去在公司的经验,中国的主流其实是异步,异步的好处是训练更加可扩展,对于很多传统NLP任务,异步比同步要好。所以要验证这个问题需要在实验中比较。
实录结束
潘欣,百度深度学习框架PaddlePaddle的架构设计以及核心模块开发负责人,百度深度学习技术平台部TC主席。在计算机视觉CVPR和云计算SoCC等国际会议发表多篇论文。

- 百度深度学习平台PaddlePaddle的深度学习入门教程
- PaddlePaddle Fluid:弹性深度学习在Kubernetes中的实践
- 深度学习正在吞噬软件
- 深度学习框架PaddlePdddle学习( 一)
- 从学习 Paddle 开始学习深度学习
- 百度开源深度学习平台Paddle
- [置顶] 【深度学习 框架】PaddlePaddle的安装
- paddlepaddle深度学习
- 新一代人工智能发力:深度学习技术正在改变互联网
- PaddlePaddle, TensorFlow, MXNet, Caffe2 , PyTorch五大深度学习框架2017-10评测
- PaddlePaddle深度学习实战——英法文翻译机
- 深度学习入门:详解 Ubuntu 下 PaddlePaddle 源码编译安装
- 百度开源深度学习框架PaddlePaddle安装配置(单机CPU版)
- 百度深度学习平台PaddlePaddle的深度学习
- 百度宣布将在Kubernetes上运行其深度学习平台PaddlePaddle
- 百度深度学习平台PaddlePaddle的深度学习(转载自 m0_37903426的博客)
- 百度AI开发者实战营,百度AI开发平台,PaddlePaddle深度学习架构,资料汇总
- 深度学习框架PaddlePdddle学习( 二)
- 用MXnet实战深度学习之二:Neural art
- 一文看懂深度学习与计算机视觉(上)