Spark优化(五):使用map-side预聚合的shuffle操作
2018-09-29 17:18
489 查看
使用map-side预聚合的shuffle操作
如果因为业务需要,一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map-side预聚合的算子。
所谓的map-side预聚合,说的是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。
map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其它节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。
通常来说,在可能的情况下,建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。
比如以下两幅图就是典型的例子,分别基于reduceByKey和groupByKey进行单词计数。其中第一张图是groupByKey的原理图,可以看到,没有进行任何本地聚合时,所有数据都会在集群节点之间传输;第二张图是reduceByKey的原理图,可以看到,每个节点本地的相同key数据,都进行了预聚合,然后才传输到其他节点上进行全局聚合。
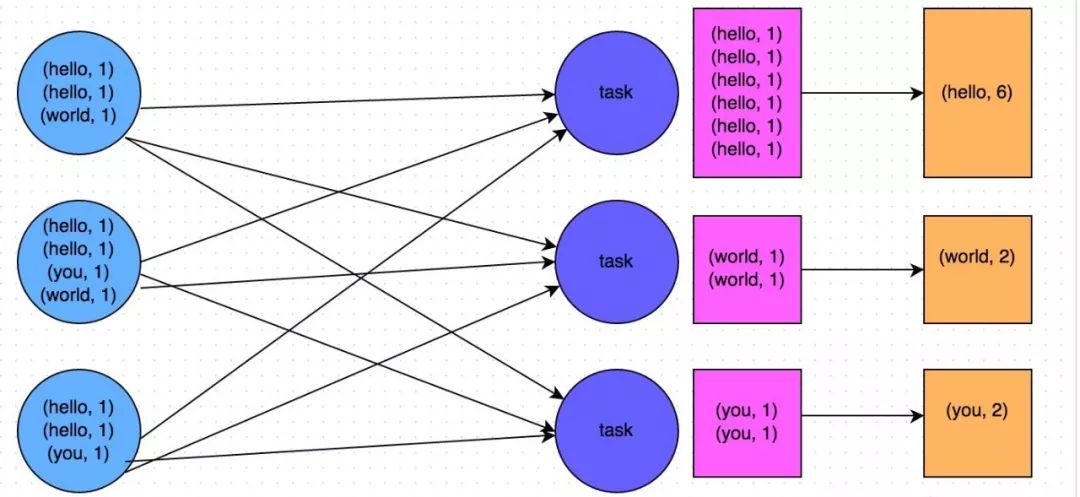
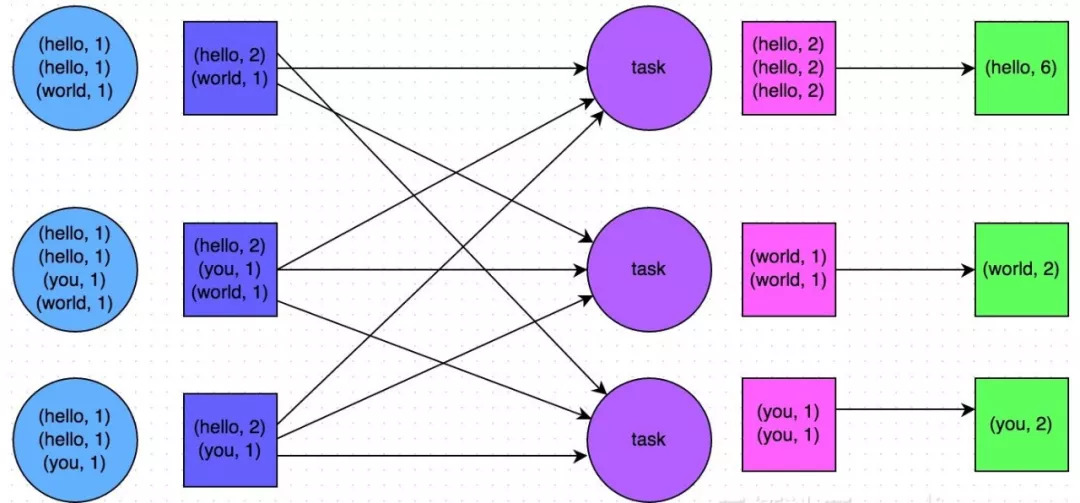

相关文章推荐
- Broadcast与map进行join,避免shuffle,从而优化spark
- Spark map-side-join 关联优化
- Spark优化-数据倾斜解决方案 提高shuffle操作reduce并行度
- Spark map-side-join 关联优化
- C++map的基本操作和使用
- 《C++ Primer》学习笔记:map容器insert操作的使用——编写程序统计并输出所读入的单词出现的次数
- C++ map的基本操作和使用
- 4.如何优化操作大数据量数据库(几十万以上数据)(如何选择聚合索引)
- 使用Jscex优化Ajax操作体验
- VIM 里使用 map/vmap 映射常用操作序列
- C++ map的基本操作和使用
- C++ map的基本操作和使用
- C++ map的基本操作和使用
- Hibernate使用Projections进行聚合操作
- C++ map的基本操作和使用
- C++map的基本操作和使用
- 如何优化操作大数据量数据库(几十万以上数据)(四。如何选择聚合索引)
- Hibernate使用Projections进行聚合操作
- C++ map的基本操作和使用
- Hibernate使用Projections进行聚合操作