Python数据分析——Pandas数据结构和操作
|
Pandas是什么? 1、一个强大的分析 结构化数据 的工具集 2、基础是NumPy,提供了 高性能矩阵 的运算 3、应用在数学挖掘,数据分析。比如,学生成绩分析,股票数据分析等 4、提供数据清洗功能 #使用import pandas as pd |
Pands数据结构,主要分为两种,Series和DataFrame
Series 视频资料学习分享 企(Q)鹅群 519970686
1、类似一维数组的对象
2、通过list构建Series
ser_obj = pd.Series(rang(10))
3、由数据和索引组成
索引在左,数据在右
索引是自动创建的
4、获取数据和索引
| ser_obj.index ser_obj.values |
5、预览数据(取前几个)
ser_obj.head(n)
6、通过索引获取数据
| ser_obj[1] ser_obj[8] |

7、索引与数据的对应关系仍保持在数组运算的结果中(过滤series中的数据)
| print(ser_obj[ser_obj > 15]) |
8、通过dict构建Series
| year_data = {2001: 17.8, 2002: 20.1, 2003: 16.5} ser_obj2 = pd.Series(year_data) print(ser_obj2.head()) print(ser_obj2.index) ser_obj2.name = 'temp' #指定name名称(相当于表头) ser_obj2.index.name = 'year' print(ser_obj2.head()) ================================= 2001 17.8 2002 20.1 2003 16.5 dtype: float64 Int64Index([2001, 2002, 2003], dtype='int64') year 2001 17.8 2002 20.1 2003 16.5 Name: temp, dtype: float64 |
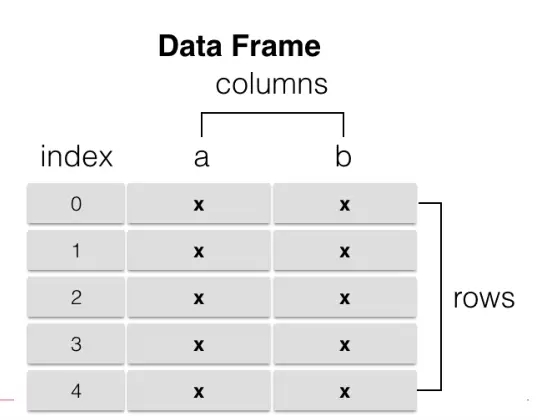
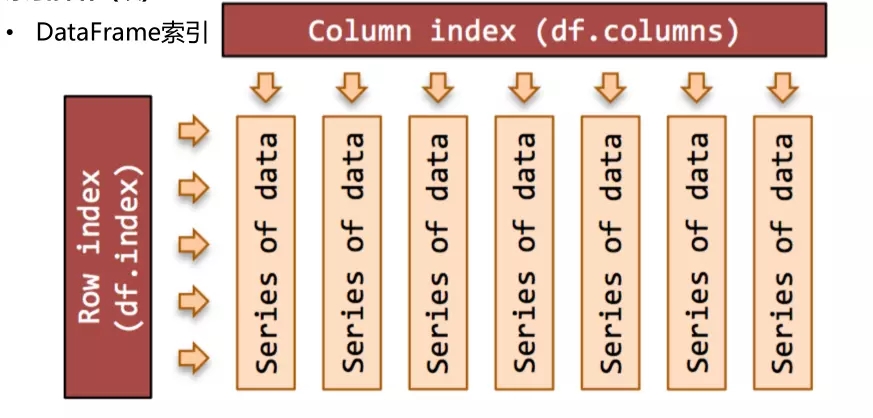
DataFrame
1、类似多维数组/表格数据
2、每列数据可以是不同的类型
3、索引包括行索引和列索引
| import numpy as np # 通过ndarray构建DataFrame array = np.random.randn(5,4) print(array) df_obj = pd.DataFrame(array) print(df_obj) # 通过dict构建DataFrame dict_data = {'A': 1., 'B': pd.Timestamp('20161217'), 'C': pd.Series(1, index=list(range(4)),dtype='float32'), 'D': np.array([3] * 4,dtype='int32'), 'E' : pd.Categorical(["Python","Java","C++","C#"]), 'F' : 'ChinaHadoop' } #print dict_data df_obj2 = pd.DataFrame(dict_data) print(df_obj2.head()) # 通过列索引获取列数据(dataFrame优先通过列索引访问数据) print(df_obj2['A']) #通过索引访问数据 print(df_obj2.values[2]) #每列都是一个series print(type(df_obj2['A'])) #通过对象属性访问 print(df_obj2.A) # 增加列,类似dict添加key-value df_obj2['G'] = df_obj2['D'] + 4 print(df_obj2.head()) # 删除列 del(df_obj2['G'] ) print(df_obj2.head()) |
Index 索引对象 视频资料学习分享 企(Q)鹅群 519970686
1、Series和DataFrame中的索引都是Index对象
2、Index具有不可变性(immutable),即Series和DataFrame中的value可以改变,但是索引不可变,保证了数据的安全
3、常见的Index种类
Index Int64Index MultiIndex(层级索引) DatatimeIndex(时间戳类型)
| print(type(ser_obj.index)) print(type(df_obj2.index)) print(df_obj2.index) ===================================== <class 'pandas.core.indexes.range.RangeIndex'> <class 'pandas.core.indexes.numeric.Int64Index'> Int64Index([0, 1, 2, 3], dtype='int64') |
Series数据操作
| import pandas as pd #index,指定索引名称 ser_obj = pd.Series(range(5), index = ['a', 'b', 'c', 'd', 'e']) print(ser_obj.head()) # 通过索引取值 ser_obj['label'],ser_obj[pos] print(ser_obj['a']) //通过索引名取值 print(ser_obj[0]) //通过位置索引取值 # 切片索引 print(ser_obj[1:3]) // 前开后闭,即,取到两个值 print(ser_obj['b':'d']) //前闭后闭,即,取到三个值 # 不连续索引 print(ser_obj[[0, 2, 4]]) // 内部是list print(ser_obj[['a', 'e']]) //内部是list # 布尔索引 ser_bool = ser_obj > 2 print(ser_bool) print(ser_obj[ser_bool]) print(ser_obj[ser_obj > 2]) |
DataFrame数据操作
| import numpy as np # colmns 指定列名 df_obj = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd']) print(df_obj.head()) # 列索引 print('列索引') print(df_obj['a']) # 返回Series类型 print(type(df_obj)) # 返回DataFrame类型 # 不连续索引 print('不连续索引') print(df_obj[['a','c']]) # 返回第一列和第三列 |
索引操作总结
Pandas的索引操作可归纳为3种
.loc:标签索引(标签的切片索引是包含末尾位置的,上面的前闭后闭)
.iloc: 位置索引
.ix: 标签与位置混合索引
-------------先按标签索引尝试操作,然后再按照位置索引尝试操作
| # 标签索引 loc # Series print(ser_obj['b':'d']) print(ser_obj.loc['b':'d']) # DataFrame print(df_obj['a']) print(df_obj.loc[0:2, 'a']) # 整型位置索引 iloc print(ser_obj[1:3]) print(ser_obj.iloc[1:3]) # DataFrame 第一个参数,表示的是第1行和第二行,第二个0表示的哪一列 print(df_obj.iloc[0:2, 0]) # 注意和df_obj.loc[0:2, 'a']的区别 |
运算与对齐
按索引对齐运算,没对齐的位置补NaN
| s1 = pd.Series(range(10, 20), index = range(10)) s2 = pd.Series(range(20, 25), index = range(5)) # Series 对齐运算,Series按行索引对齐,没对齐的位置补NaN print(s1 + s2) ================================================== 0 30.0 1 32.0 2 34.0 3 36.0 4 38.0 5 NaN 6 NaN 7 NaN 8 NaN 9 NaN ================================================ import numpy as np df1 = pd.DataFrame(np.ones((2,2)), columns = ['a', 'b']) df2 = pd.DataFrame(np.ones((3,3)), columns = ['a', 'b', 'c']) # DataFrame对齐操作 print(df1 + df2) ============================= a b c 0 2.0 2.0 NaN 1 2.0 2.0 NaN 2 NaN NaN NaN ================================ # 填充未对齐的数据进行运算 #使用add,sub,div,mul;同时通过fill_value指定填充值 s1.add(s2, fill_value = 1) df1.sub(df2, fill_value = 2.) # 填充NaN s3 = s1 + s2 s3_filled = s3.fillna(-1)//把所有的NaN使用-1填充 df3 = df1 + df2 df3.fillna(100, inplace = True)//把所有的NaN使用100填充 |
函数应用
| # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) #求绝对值,作用于df中每个数据 print(np.abs(df)) # 使用apply应用行或列数据 #如果没有指定axis方向,默认按列,axis =0 print(df.apply(lambda x : x.max())) # 指定轴方向 print(df.apply(lambda x : x.max(), axis=1)) # 使用applymap应用到每个数据 f2 = lambda x : '%.2f' % x print(df.applymap(f2)) |
排序
| s4 = pd.Series(range(10, 15), index = np.random.randint(5, size=5)) # 索引排序 s4.sort_index() df4 = pd.DataFrame(np.random.randn(3, 4), index=np.random.randint(3, size=3), columns=np.random.randint(4, size=4)) df4.sort_index(axis=1) # 按值排序 sort_values(by='label') df4.sort_values(by=1) |
处理缺失数据 视频资料学习分享 企(Q)鹅群 519970686
| import numpy as np df_data = pd.DataFrame([np.random.randn(3), [1., np.nan, np.nan], [4., np.nan, np.nan], [1., np.nan, 2.]]) df_data.head() # isnull df_data.isnull() # dropna 丢弃缺失数据 df_data.dropna() #df_data.dropna(axis=1) # fillna 填充缺失数据 df_data.fillna(-100.) |

- python数据分析:pandas数据结构与操作
- #######用python做数据分析4|pandas库介绍之DataFrame基本操作#######
- 利用Python进行数据分析(15) pandas基础: 字符串操作
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
- 利用 Python 进行数据分析(八)pandas 基本操作(Series 和 DataFrame)
- 利用Python进行数据分析(15) pandas基础: 字符串操作
- Python操作Mysql数据库入门——数据导入pandas(数据分析准备)
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
- Python数据分析库pandas基本操作
- Python数据分析模块 | pandas做数据分析(二):常用预处理操作
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
- Python数据分析入门(一)-Pandas数据结构(Series)
- Python数据分析入门(一)-Pandas数据结构(Series)
- 【Python数据分析】pandas数据结构简介
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
- [Python数据分析-01]Pandas数据结构之Series
- 用python做数据分析4|pandas库介绍之DataFrame基本操作 by 是蓝先生
- 用python做数据分析4|pandas库介绍之DataFrame基本操作