Tensorflow实现简单的一元线性回归并保存和加载模型
简介:本文章以tensorflow为平台建立了一个简单的线性回归模型,并得到了不错的效果。同时实现了模型的保存与加载,当一个模型的训练时间非常长的时候,利用模型的加载可以实现开启程序时接着上次训练。
- 平台:Python 3.6
- IDE:Pycharm
一、线性回归模型介绍
简单来说:线性回归就是利用一曲线段对一些连续的数据进行拟合,进而可以用这条曲线预测新的输出值。数学模型如下:
其中:w称为权重,b称为偏置,利用现有的数据训练出理想的w和b的值,然后建立模型,进行下一个值的预测。
二、数据介绍
import numpy as np x_data = np.arange(-1, 1, 0.02, dtype=np.float32).reshape((100, 1)) y_true = np.tan(x_data) + np.random.normal(0, 0.1, 100).reshape((100, 1))[/code]
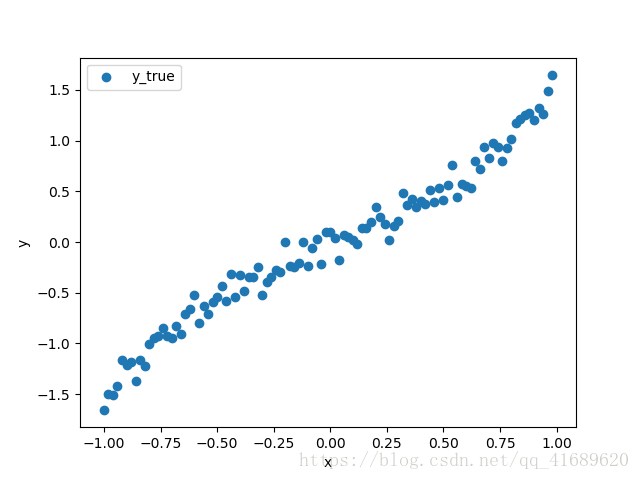
利用numpy模块产生100个数据,如下图展示的散点图,目的就是根据这些数据,拟合出一条最佳的曲线。
三、思路
1、加载数据
由于上图的数据是随机产生的,需要将数据保存在本地,然后从本地读取。不然每次运行程序的数据不一致。
with tf.variable_scope("data"):
# 获取数据
x_data = np.arange(-1, 1, 0.02, dtype=np.float32).reshape((100,1))
y_true = np.loadtxt("./data.csv").reshape((100,1))[/code]
2、建立模型
随机初始化权重weight和偏置bias的值,并建立回归模型。
with tf.variable_scope("model"):
# 初始化权重和偏置
weight = tf.Variable(tf.random_normal([1,1], mean=3.4, stddev=5.2), trainable=True, name="weight")
bias = tf.Variable(3.0, name="bias")
# 建立模型
y_predict = tf.matmul(x_data, weight) + bias[/code]
3、建立损失函数
根据真实值和预测值的均方误差值,建立损失函数。
with tf.variable_scope("loss"):
loss = tf.reduce_mean(tf.square(y_true - y_predict))[/code]
4、利用梯度下降优化损失
利用tensorflow自带的梯度下降法减小损失函数。
with tf.variable_scope("optimizer"):
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)[/code]
5、建立会话运行程序
with tf.Session() as sess:
sess.run(init_op)
print("初始化权重:%f 初始化偏置:%f" %(weight.eval(), bias.eval()))
# 建立事件文件
file_writer = tf.summary.FileWriter("./temp/summary/linear", graph=sess.graph)
# 判断本地是否有保存有模型
if os.path.exists("./temp/ckpt/checkpoint"):
saver.restore(sess, "./temp/ckpt/model")
for i in range(self.FLAGS.train_step):
sess.run(train_op)
# 运行合并的tensor
summary = sess.run(merged)
file_writer.add_summary(summary, i)
print("第%d次优化参数的权重为:%f, 偏置为:%f" % ((i + 1), weight.eval(), bias.eval()))[/code]
四、模型的保存与加载
# 保存模型 var_list:指定要保存和还原的变量, max_to_keep:指定要保存最近检查点文件的个数,默认为5 tf.train.Saver(var_list=None, max_to_keep=5) # 加载模型 saver.save(var_list, file_path)[/code]
模型保存后,会出现四个文件

.meta:保存了TensorFlow的graph。包括all variables,operations,collections等等。
.index和.data:保存了所有weights,biases,gradient and all the other variables的值。
checkpoint文件:只保存最新检查点文件的记录,即最新的保存路径。
五、结果分析
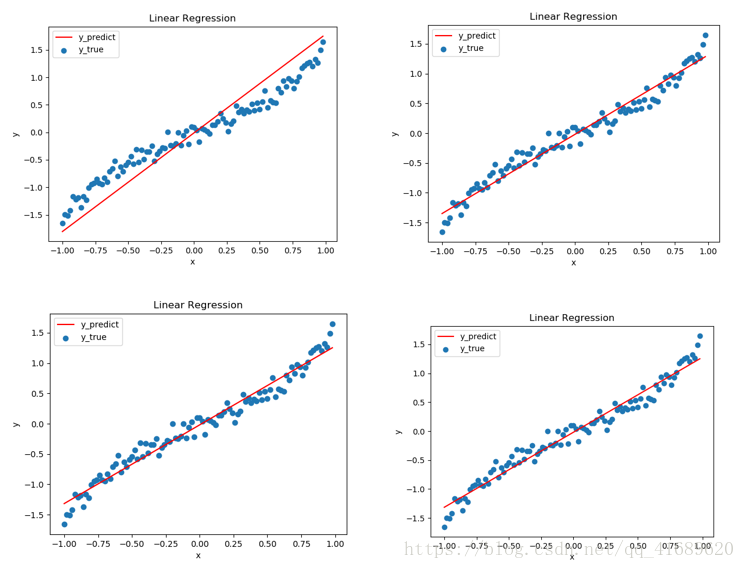
每训练400次便拟合一下曲线,图一是训练400次得到的曲线,图二是训练800次得到的曲线,图三是1200次,图四是1600次。从图中可以看出,拟合的曲线效果越来越好。
六、运行程序
命令行输入以下命令,train_step表示要训练的步数。
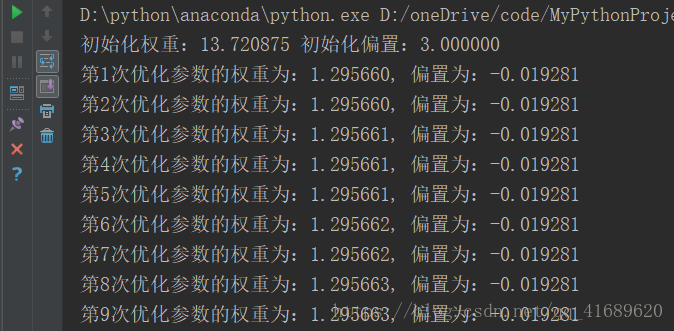
得到如下结果:
七、整体程序
# -*- coding: utf-8 -*-
"""
--------------------------------------------------------
# @Version : python3.6
# @Author : 577828140@qq.com
# @Software: PyCharm
# @Time : 2018/9/21 13.14
--------------------------------------------------------
"""
import os
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
class LinearRegression(object):
def __init__(self):
self.FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_integer("train_step", 100, "训练步数")
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2" # 关闭警告
def run(self):
with tf.variable_scope("data"):
# 获取数据
x_data = np.arange(-1, 1, 0.02, dtype=np.float32).reshape((100,1))
y_true = np.loadtxt("./data.csv").reshape((100,1))
with tf.variable_scope("model"):
# 初始化权重和偏置
weight = tf.Variable(tf.random_normal([1,1], mean=3.4, stddev=5.2), trainable=True, name="weight")
bias = tf.Variable(3.0, name="bias")
# 建立模型
y_predict = tf.matmul(x_data, weight) + bias
with tf.variable_scope("loss"):
# 建立损失函数
loss = tf.reduce_mean(tf.square(y_true - y_predict))
with tf.variable_scope("optimizer"):
# 利用梯度下降优化损失
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(loss)
# 收集tensor
tf.summary.scalar("losses", loss)
tf.summary.histogram("weights", weight)
# 合并tensor
merged = tf.summary.merge_all()
# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()
# 定义一个保存变量的实例
saver = tf.train.Saver()
# 建立会话运行程序
with tf.Session() as sess:
sess.run(init_op)
print("初始化权重:%f 初始化偏置:%f" %(weight.eval(), bias.eval()))
# 建立事件文件
file_writer = tf.summary.FileWriter("./temp/summary/linear", graph=sess.graph)
# 判断本地是否有保存有模型
if os.path.exists("./temp/ckpt/checkpoint"):
saver.restore(sess, "./temp/ckpt/model")
for i in range(self.FLAGS.train_step):
sess.run(train_op)
# 运行合并的tensor
summary = sess.run(merged)
file_writer.add_summary(summary, i)
print("第%d次优化参数的权重为:%f, 偏置为:%f" % ((i + 1), weight.eval(), bias.eval()))
# 数据可视化
if (i+1) % 400 == 0:
self.plot_data(y_true, weight.eval(), bias.eval(), i)
# 保存模型
saver.save(sess, "./temp/ckpt/model")
# 数据可视化
def plot_data(self, y_true, weight, bias, i):
x_data = np.arange(-1, 1, 0.02)
plt.scatter(x_data, y_true, label="y_true")
y_predict = x_data * weight[0][0] + bias
plt.plot(x_data, y_predict, color="red", label="y_predict")
plt.xlabel("x")
plt.ylabel("y")
plt.title("Linear Regression")
plt.legend()
plt.savefig("./img/"+str(i+1)+".png")
plt.show()
if __name__ == '__main__':
linear_regression = LinearRegression()
linear_regression.run()[/code]
八、Tensorboard可视化
Tensorflow一个非常受欢迎的地方就是Tensorboard的可视化部分,该功能可以让我们看到整个模型的运行过程。
开启Tensorboard,命令行输入:
tensorboard --logdir="file_path"
通过梯度下降法得到的损失函数如下,可以看出,损失函数loss逐渐减小并最终收敛在0附近。
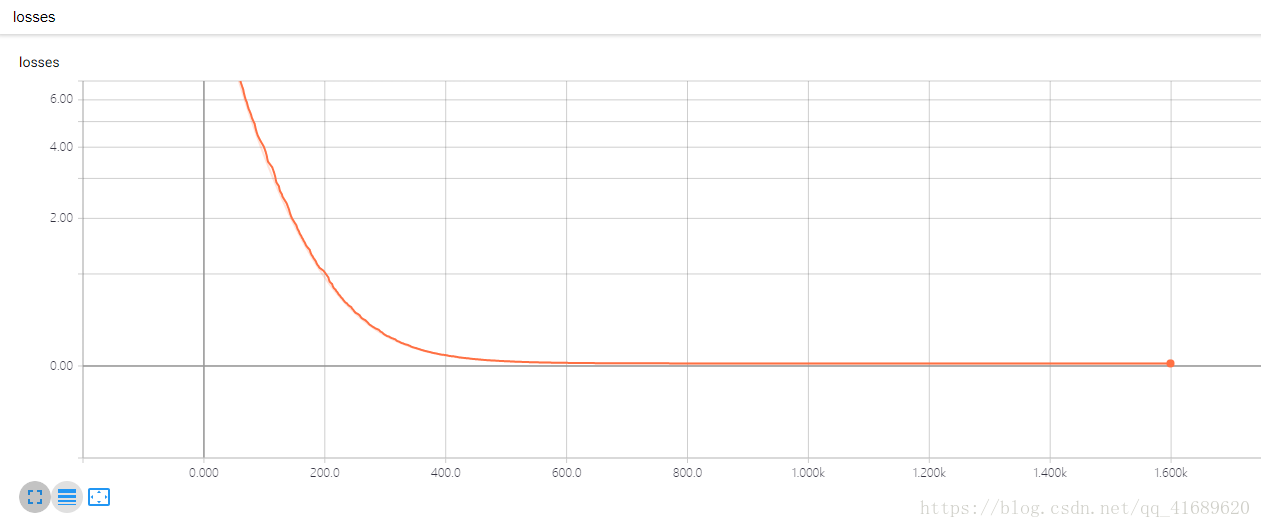
该模型可表示为:
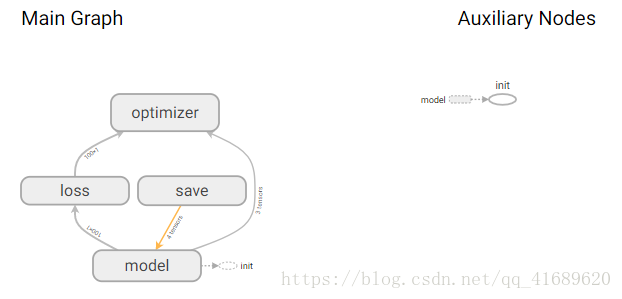
九、总结
本文通过一个简单的一元线性回归模型介绍了Tensorflow的使用流程,并介绍了如何保存和加载模型,同时介绍了关于Tenforboardde的简单使用,为后续神经网络的使用奠定了基础。
阅读更多
- Keras上基于TensorFlow实现简单线性回归模型
- Tensorflow学习笔记-模型保存与加载
- TensorFlow模型保存和恢复简单的例子
- tensorflow 模型保存与加载
- Tensorflow学习笔记:模型训练数据的保存和恢复的简单实例
- tensorflow学习之Faster R-CNN模型的保存与加载
- tensorflow-模型保存和加载(一)
- TensorFlow 深度学习框架(7)-- 变量管理及训练模型的保存与加载
- TensorFlow实现人脸识别(4)--------对人脸样本进行训练,保存人脸识别模型
- 解决tensorflow模型参数保存和加载的问题
- tensorflow学习之Faster R-CNN模型的保存与加载
- TensorFlow 深度学习框架(7)-- 变量管理及训练模型的保存与加载
- 利用tensorflow 一步一步实现一个简单神经网络,线性回归
- C++从零实现深度神经网络之五——模型的保存和加载以及画出实时输出曲线
- TensorFlow1.5训练模型的保存与加载
- Tensorflow深度学习之十五:VGG16模型的简单自主实现
- 基于TensorFlow实现一元线性回归
- 使用TensorFlow实现简单的线性回归(LinearRegression)
- TensorFlow 深度学习框架(7)-- 变量管理及训练模型的保存与加载
- 简单完整地讲解tensorflow模型的保存和恢复