python3.5入门笔记(一)--------基础知识
(一)前言:
1. IDLE:python学习的外壳,即通过键入文本与程序交互的途径。、
2. 在python官网下载python到本地,在电脑左下角开始->搜索找到IDLE打开,即可看到编译软件。
3. 基础:print("welcome python") ,表示打印输出里面的语句,主要python3.0之后不支持print "welcome python"和 printf("welcome python"); 2种写法都不支持,报错。 #在python中表示注释。dir(_bulitins_)查看python的内置函数(bif),help(big)查看某个内置函数的解释说明,type(a)查看a的类型,isinstance(a,str/int/float)判断a的类型是否是字符串/整数/浮点型,返回true/false。ctrl+n进入IDLE的编译入口,即之编译不执行,再保存后按F5或者点击run即可执行编译好的代码块。alt+n下一条编译语句,alt+p上一条编译语句。

,
(二)基础语法:
1. python支持的数据类型:Number(数字,包括整型int,浮点型float,复数complex),String(字符串),List(列表),Tuple(元组),Sets(集合),Dictionary(字典);
2.整型int:包括正,负整数,没有限制大小,支持+、-、*、/法则。注意:在整数除法中,(/)计算的结果是浮点数(即使能整除也至少保留一位小数)如151/51 结果为3.0,(//)表示只取结果的整数部分,如200//51 结果为3。
3. 浮点型float:有小数点,或者科学计数法表示。支持+、-、*、/法则。注意:在计算机中整型和浮点型存储方式不同,整数的运算永远是精确的,浮点型运算可能会有四舍五入的误差,如3.3*102 结果为352.0999999999997,且浮点型在四则运算下结果都为浮点型。
4. 复数complex:即有实数部分和虚数部分组成,a+bj或complex(a,b)表示复数,其中a、b都是浮点型。
5. 数据类型的转换:int(x) :x转换为整数,即去整数部分,单是只能转换数值类型或者纯数字的字符串类型,否则报错。float(x):x转换为浮点型。complex(x):x转换为复数,实数部分x,虚数0。complex(x,y):x为实数部分,y为虚数部分。str(x):x转换为字符串,str(5e10) 其结果为"5e10"。
6. 常量:全部大写的变量名,如PT(圆周率)和E(自然常数)。
7. 转义:转移字符\或者在字符串前加r'这是字符串,里面的特殊符号会被转义'。注意用r转义时,字符串最后一位不能是\。对于很多行的字符串,需要用三引号""",如""" 这里是一段小诗 """ 。注意:单双引号都是英文的。
8. 模块: import random, 引用random模块, random.randint(1,10)调用random模块中的randint()方法,随机生成1~10的整数。
以.py结尾的文件,就是模块。引入模块:import random 。 调用模块的方法 :random.randint()
9. 算术操作符:+、-、*、/、%、**(幂运算)、//(除取下整)。
10.比较操作符:>、<、>=、<=、==、!=,判断两个变量的值(不是内存地址)是否相等。
11.赋值运算符:=、+=、-=、*=、/=、%=,**=、//=。
12.位运算符:&、|、^、~、<<、>>。
13.逻辑操作符:and 、or、not。
14.成员运算符:in、not in。
15.身份运算符:is、is not,判断俩个对象的内存地址是否想到。
16.优先级:幂运算>正负符号>算术运算符>比较运算符>逻辑运算符。
17.查看变量在内存的地址:id(a),就是查看变量a在内存的地址,如14656。
18.修改全局变量:在函数内部global num声明该函数内的num是全局变量,然后可以修改全局变量num了。否则在函数内部不能修改全局变量。注意:全局变量的定义,通常在所以函数的最上面(前面)。全局变量的命名,为了区分局部变量,可以在前面加gl_,如gl_name。
19. 在hbuilder编译器中怎么编译.py文件:https://www.geek-share.com/detail/2675860755.html;18. 变量: 无需声明,直接赋值,全部大写字母可以表示常量也不需要声明, teacher="我是变量值,被赋值给前面的teacher变量",变量的命名,由数字,字母,_组成,数字不能再首位,且不能是关键词。在使用变量前 需要进行赋值。命名规则:驼峰命名法,匈牙利命名法,下划线命名法。注意,在使用变量之前,一定要对其赋值。
(三)列表和元祖:
1.序列:包括列表,元祖,字符串,Unicode字符串,buffer对象,xrange对象。序列的操作如下:
① 索引:即下标,通过索引获取单个元素,a[0]。正向从0开始,反向从-1开始。
② 分片:获取一定范围的元素组成的序列,a[start:end:step],含start不含end,step默认1,不位0,负数表示反向取值。
③ 序列拼接:通过'+'返回新的序列。
④ 乘以数字:序列*数字,返回,重复数字遍的新序列。如'a'*3='aaa';
⑤ 判断成员资格:in、not in。
⑥ 常用api:len(a),max(a),min(a)。
2.列表:除了以上序列的操作方法,还有如下操作:
① 元素索引赋值:通过索引修改元素的值,list[0]="修改列表下标为0的值"。但是,不能为不存在位置赋值。
② 增加元素append:list.append(obj),向列表尾部添加obj元素。
③ 删除元素del:del list[1],删除页列表指定下标对应的元素。
④ 列表化对象list():将字符串转换为列表;
⑤ 分片插入:list[2:2]="这列表2位置插入该值"。
⑥ 嵌套列表:[[1,2],3,4]。
⑦ 列表方法:
⑴ append:list.append(obj),在列表尾部添加元素。
⑵ count:list.count(obj),元素obj在列表中出现的次数。
⑶ extend:list.extend(obj),在列表尾部追加另一个序列的多个值,修改原列表。
⑷ index:list.index(obj),从列表中查找第一个匹配项obj的索引位置。
⑸ insert:list.insert(index,obj),在列表指定位置,插入指定元素。
⑹ pop:list.pop(i),移除列表中指定位置的元素,并返回该值,默认不写i,是移除最后一个元素。
⑺ remove:list.remove(obj),移除列表中第一个出现obj值的元素。
⑻ reverse:list.reverse(),列表倒叙。
⑼ sort:list.sort(func),列表排序。
⑽ clear:list.clear(),清空列表,相当于del list[:]。
⑾ copy:list.copy(),复制列表,相当于list[:]。
3.元祖:内容不能改变的列表,空元祖(),只有一个元素的元祖(1,)。
① tuple():函数是讲序列转换为元祖。
② 索引访问元祖:tuple[i],查找元祖下标i的值。
③ 拼接元素:通过'+'返回新的元祖。
④ 删除元祖:del tuple1,只能删除整个元祖,不能删除元祖里面的某个元素。
⑤ 分片元祖:tuple1[1:]。
⑥ len(tuple1):元祖长度,max/min(tuple1),元祖里最大最小值。
⑦ 交换2个变量的值:a,b=(b,a),其中()可以省略。另外一种交换变量值的方式,a=a+b,b=a-b,a=a-b;
(四)字符串:
1.字符串:由单/双引号构成,支持序列的索引,分片,成员资格,长度,最大最小值。但是不支持分片赋值。
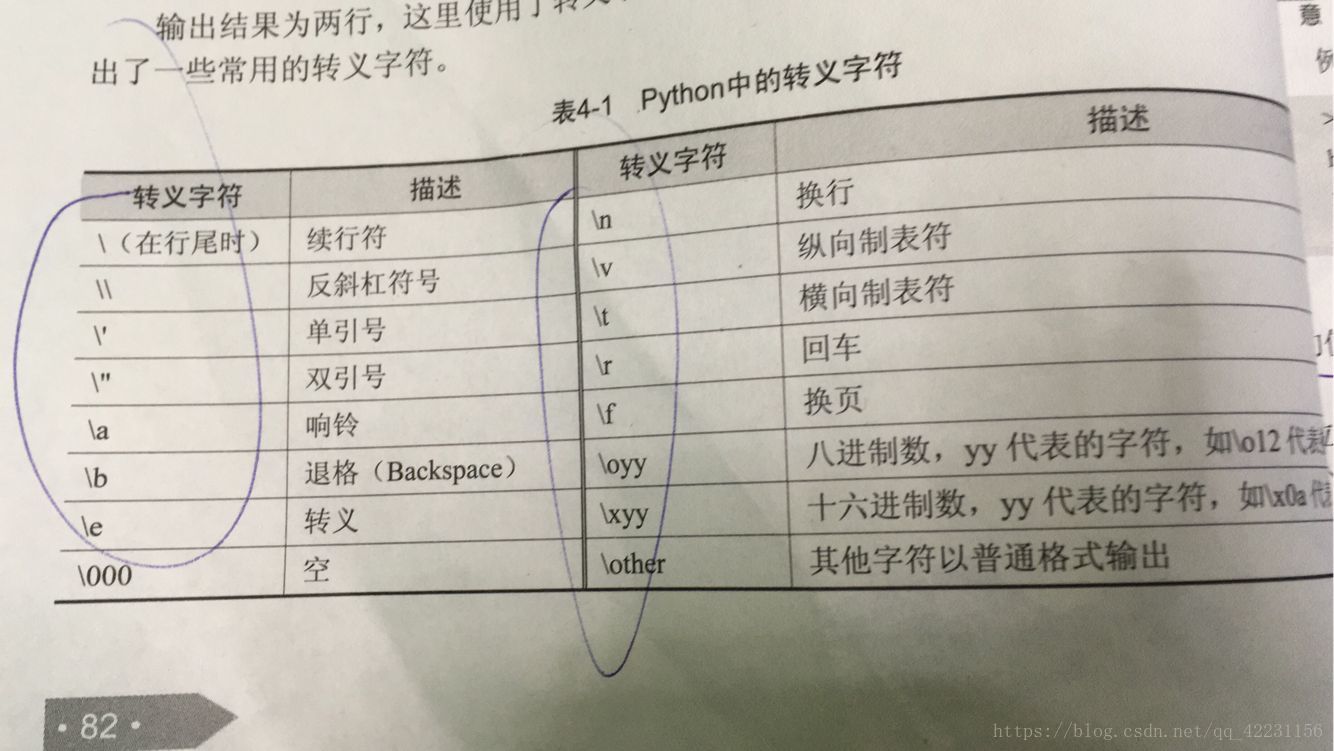
2.转义字符:
3.字符串格式化:使用'%'完成字符串格式化操作。
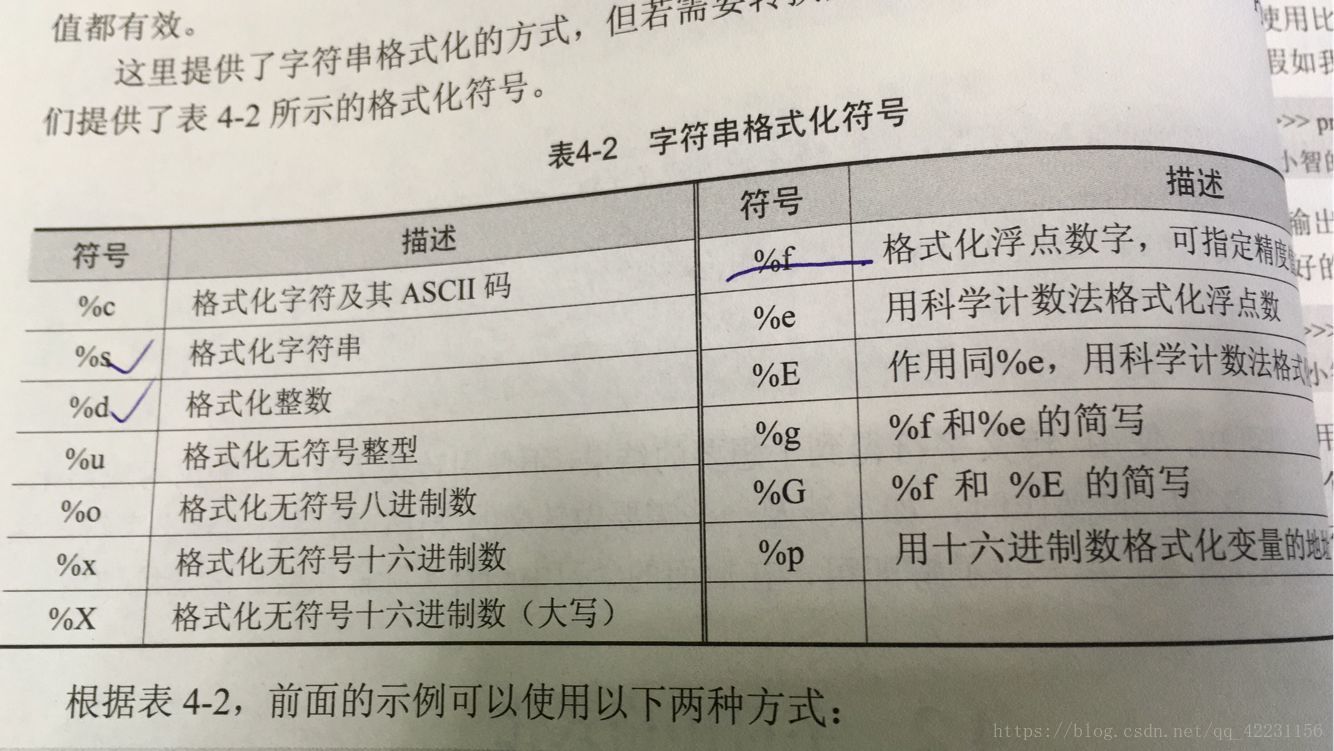
print("阿哲今年%s岁"%'27')。
print("%s今年%s岁"%("Ace",'27'))。
4.字符串的api方法:
① find():str.find(str1,start=0,end=len(str)),查找字符串str中从索引start开始到end结束的子字符串str1第一次出现的位置,找到返回该位置,找不到返回-1。不写start和end默认查找整个字符串。
② join():str.join(sq),将序列sq中的元素,通过字符str(如'+',','等)拼接成新的元素。注意,str和sq里面的元素都必须全是字符串,否则报错,即'+'.join([1,2])会报错。
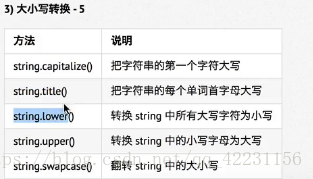
③ lower():str.lower(),不需参数,将字符串str全部大写转换为小写。
④ upper():str.upper(),不需参数,将字符串str全部小写转换为大写。
⑤ swapcase():str.swapcase(),不需参数,将字符串str中小写转换为大写,小写转换为大写。
⑥ replace():str.replace(old,new[,max]),将字符串str中的old子字符串替换为new字符串,不写max参数,表示替换所有的old,有max参数表示最多替换max次old。
⑦ split():str.split(str1="",num)将字符串切片成列表,str是切割符,默认是空格,num表示切割几次,默认是该切割符
存在的次数。
⑧ strip():str.strip([chars]),去掉字符串首尾的chars字符(如'---'),默认是空格。



(五)字典:
1. 字典:即由一对键值对组成的,键必须是唯一的,key键的类型可以是字符串,整数,元祖,但是不能为列表/元祖类型,即字典的key必须是不可变类型(字符串,整数,元祖),不能是可变类型(列表/元祖)。
2. 通过key键获取值:dict1[k]。
3.通过key来修改/新增键值:dict1[key]=val,如果key存在就是修改Key值,否则就是新增key值对。
4.for循环遍历字典:for k in dict1: print(k,dict1[k])。
5. 字典的方法:
① len():len(dict1)查看字典键值对个数。
② clear():dict1.clear(),清空字典。
③ update():dict1.update(dict2),合并键值对。
(六)条件、循环和其他语句:
1.文件名:智能是字母,数字,下划线组成。
2.import的使用:import module1[,module2,module3] 从python标准库中引入单个或多个模块。import math as m,为模块取别名。
3.from modname import name1[,name2,name3]/*:从指定模块中引入其中的部分函数,*表示引入模块中所有。 from math import pi as p,取别名。
4.使用逗号输出:print("a","b","c")
5.赋值:
① 序列解包:如x,y,z=1,2,3,相当于x=1,y=2,z=3赋值。注意:左边的x,y,z和右边的1,2,3数量必须相等,否则报错。
② 链式赋值:如x=y=z=10。
③ 增量赋值:如*=、+=、-=、/=、//=、%=、**=。
6. 条件语句:
① if 条件表达式:
#满足条件表达式时,执行的代码,需要缩进。
elif 条件表达式:
#满足条件,执行的代码。
else:
#else执行的代码。
② 嵌套代码:即if条件语句里面还有嵌套if语句。
③ is的同一性运输符:x is y与x==y,前者是判断x和y是否指向同一内存地址,后者判断x和y值是否相等。
7. 循环:
① while 条件表达式/True:
#执行循环体
break #跳出循环
countinue #跳出当前循环进入下一次循环
② for item in seq: #循环任何序列,包括字符串,列表。for key,value in tuple1.items(): 循环字典。注意:字典是无序的。for num1,num2 in zip(range(3),range(100)),zip函数以短序列range(3)为准长度,当短序列遍历结束,for循环就会结束。num1,num2分别对应序列range(3)和range(100)的元素。for item in
③ sorted(seq):倒序排列序列,并返回列表。如seq=[1,2,3]或seq='hello,world!'。
④ reversed(seq):倒序排列序列,并返回与原序列同类型,如字符串,列表,就返回倒序后的字符串,列表。
⑤ pass:空语句,保持程序结构的完整性。
⑥ 例如九九乘法表:

(七)函数:
1. 对代码的封装:重用,优化代码,对有参数的函数,参数类型不对,数量不对也会报错。
2.函数的声明:
def 函数名(参数):
#要执行的函数体,必须缩进,没有return或者return(return None)表示返回值都是None。
3.函数的参数:
def fun(name,age=27):
#调用函数fun时,传入的参数方式,fun("Ace",27)或fun(name="Ace",age=27),在声明函数def fun(age=27)表示默认参 #数值为27,注意无论多少个默认参数,默认参数都不能在必须参数之前。如不能def fun(age=27,name):会报错。对 #于不确定参数个数的用*arg表示未知参数个数,对于参数是字典的未知元素个数,用**arg。组合参数顺序:def fun(p #,d val,**a)。注意:函数的必须先定义,才能提前,不能声明提前。
4.函数的执行流程:从上倒下,从左到右。
5.形参和实惨:
6.变量的作用域:局部作用域,全局作用域。
7.递归函数:函数内部调用函数自身,注意:一定要有终止条件,避免死循环。
8.匿名函数:调用完就在内存中清除的函数。
lambda x,y:
return x+y
9.函数的注释:
def fun():
"""这是函数的注释"""
print("关于函数的注释")
10.多值参数:
def fun(num,*args,**kwargs): 一个*表示接收不确定个数的元祖,俩个**表示接收不确定个数的字典参数.
print(num)
print(args)
print(kwargs)
fun(1,2,3,4,name="啊啊",age=27) :其中num=1,*args=(2,3,4),可以循环元祖,求元祖所有值的和,**kwargs={name="啊啊",age=27}
11. 元祖(*实参)和字典(**实参)的拆包: fun(*tuple1,**dict1)。
def fun(*args,**kwargs): 一个*表示接收不确定个数的元祖,俩个**表示接收不确定个数的字典参数.
print(args)
print(kwargs)
tuple1=(1,2,3)
dict1={name="Ace“,age=27}
fun(tuple1,dict1) #执行该函数时,会将tuple1,dict1实参全部划分给形参*args,而**kwargs则为空字典。即打印args出来(1,2,3),{name="Ace“,age=27} 以及kwargs打印出来{}。
fun(*tuple1,**dict1) #执行该函数时,会将tuple1实参划分给形参*args,而实参dict1划分给**kwargs。即打印args出来(1,2,3) 以及kwargs打印出来{name="Ace“,age=27}。
阅读更多

- 零基础 入门学Python-学习笔记第一讲(基本知识)
- Python学习入门笔记-基础知识
- python 学习笔记之基础知识总结
- Python学习笔记-第一章 基础知识
- 【零基础入门学习Python笔记005】闲聊之Python的数据类型
- 零基础入门学习Python学习笔记第五讲【列表】
- 【python数据挖掘课程】二十二.Basemap地图包安装入门及基础知识讲解
- python学习笔记一:python基础知识
- python入门基础笔记
- python基础教程学习笔记 第一章 基础知识
- Python初学笔记:Python编程基础知识
- python学习笔记(二)基础入门
- Python学习笔记之基础知识
- Python学习笔记---基础知识
- Python自学笔记(一)(Python基础知识)
- Python学习笔记:程序设计的基础知识
- [Python入门及进阶笔记]Python-基础-元组小结
- [Python入门及进阶笔记]Python-基础-集合小结
- 【零基础入门学习Python笔记004】改进第一次设计的游戏
- Python学习笔记一(基础知识)