基于centos7部署hadoop集群的准备环境部署
2018-09-12 14:34
531 查看
由于工作需要,需要搭建hadoop+zookeeper+hbase+storm+kafka集群
准备了三台服务器(一台8核+32G内存+300G硬盘充当master,一台8核+16G内存+300G硬盘充当slave01,一台8+16G+500G硬盘充当slave02,并且都能上网),具体如下:
Master Hadoop、zookeeper、hbase、storm、kafka、
Slave01 Hadoop、zookeeper、hbase、opentsdb、storm、kafka
Slave02 Hadoop、zookeeper、hbase、opentsdb、storm、kafka
以下用来作为学习笔记。
一、安装前准备工作。【三台机器需要准备环境】
(1)修改主机名。
使用命令:hostnamectl set-hostname master 【在master主机上执行】
hostnamectl set-hostname slave01 【在slave01主机上执行】
hostnamectl set-hostname slave02 【在slave02主机上执行】
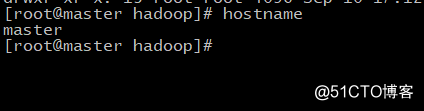
执行完命令后查看,如下图:
(2)配置免密钥登录
ssh-keygen #一路回车即可
ssh-copy-id master
ssh-copy-id slave01
ssh-copy-id slave02
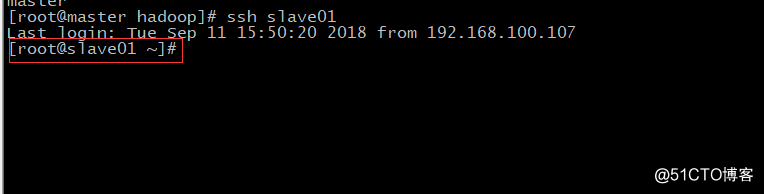
验证是否正确,如下图:
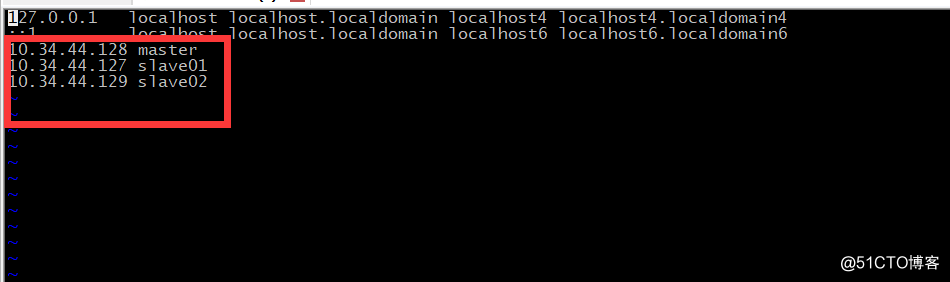
(3)配置hosts文件
vim /etc/hosts
(4)安装jdk1.8
①下载安装包
wget http://s***.hc-yun.com:10081/down/jdk-8u171-linux-x64.tar.gz
②解压到目录 (目录随意)
tar zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local
③添加jdk环境变量
vim /etc/profile.d/java.sh

验证是否安装jdk成功,如下图:

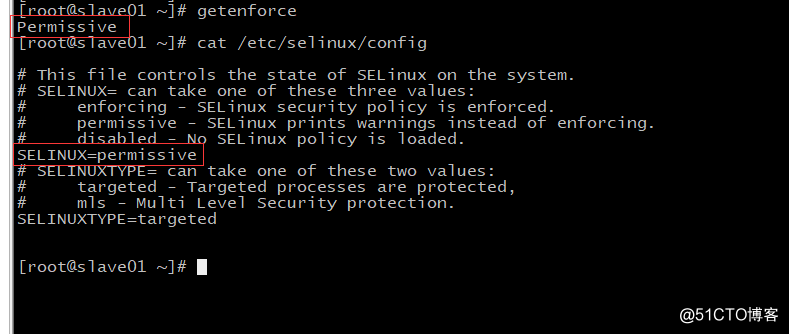
(5)关闭防火墙和selinux
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
rm -rf /etc/localtime && ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
systemctl stop firewalld
systemctl disable firewalld
(6)修改环境变量
echo " soft nofile 65535" >> /etc/security/limits.conf
echo " hard nofile 65535" >> /etc/security/limits.conf
echo " soft nproc 65535" >> /etc/security/limits.conf
echo " hard nproc 65535" >> /etc/security/limits.conf
echo " soft memlock unlimited" >> /etc/security/limits.conf
echo " hard memlock unlimited" >> /etc/security/limits.conf
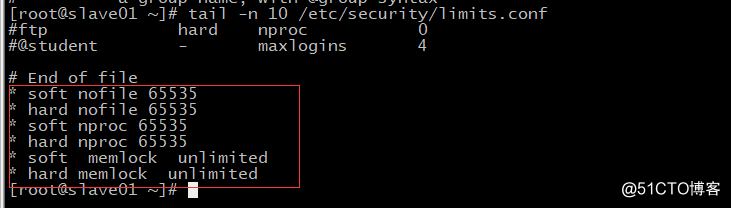
(7)创建统一文件夹,后期把程序都放到该文件夹下 【根据磁盘状况】
mkdir -p /home/hadoop
添加各个服务变量
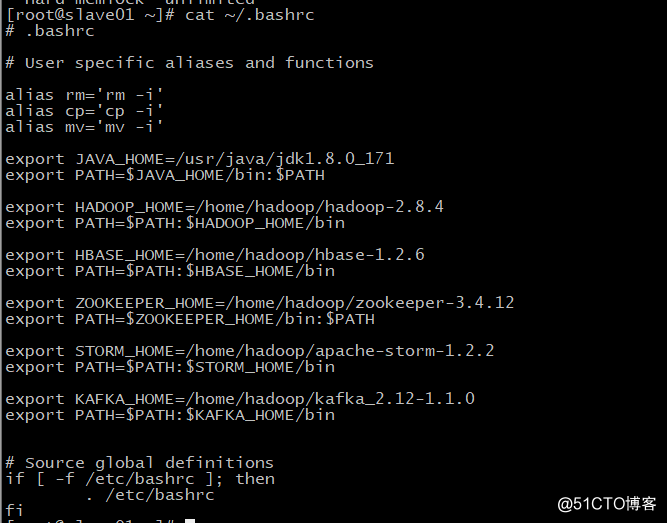
cat <<EOF > /root/.bashrc
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
export JAVA_HOME=/usr/java/jdk1.8.0_171
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/home/hadoop/hadoop-2.8.4
export PATH=$PATH:$HADOOP_HOME/bin
export HBASE_HOME=/home/hadoop/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.12
export PATH=$ZOOKEEPER_HOME/bin:$PATH
export STORM_HOME=/home/hadoop/apache-storm-1.2.2
export PATH=$PATH:$STORM_HOME/bin
export KAFKA_HOME=/home/hadoop/kafka_2.12-1.1.0
export PATH=$PATH:$KAFKA_HOME/bin
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
EOF
如下图:
基础环境已经布置完成,后续......
准备了三台服务器(一台8核+32G内存+300G硬盘充当master,一台8核+16G内存+300G硬盘充当slave01,一台8+16G+500G硬盘充当slave02,并且都能上网),具体如下:
Master Hadoop、zookeeper、hbase、storm、kafka、
Slave01 Hadoop、zookeeper、hbase、opentsdb、storm、kafka
Slave02 Hadoop、zookeeper、hbase、opentsdb、storm、kafka
以下用来作为学习笔记。
一、安装前准备工作。【三台机器需要准备环境】
(1)修改主机名。
使用命令:hostnamectl set-hostname master 【在master主机上执行】
hostnamectl set-hostname slave01 【在slave01主机上执行】
hostnamectl set-hostname slave02 【在slave02主机上执行】
执行完命令后查看,如下图:
(2)配置免密钥登录
ssh-keygen #一路回车即可
ssh-copy-id master
ssh-copy-id slave01
ssh-copy-id slave02
验证是否正确,如下图:
(3)配置hosts文件
vim /etc/hosts
(4)安装jdk1.8
①下载安装包
wget http://s***.hc-yun.com:10081/down/jdk-8u171-linux-x64.tar.gz
②解压到目录 (目录随意)
tar zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local
③添加jdk环境变量
vim /etc/profile.d/java.sh
验证是否安装jdk成功,如下图:
(5)关闭防火墙和selinux
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
rm -rf /etc/localtime && ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
systemctl stop firewalld
systemctl disable firewalld
(6)修改环境变量
echo " soft nofile 65535" >> /etc/security/limits.conf
echo " hard nofile 65535" >> /etc/security/limits.conf
echo " soft nproc 65535" >> /etc/security/limits.conf
echo " hard nproc 65535" >> /etc/security/limits.conf
echo " soft memlock unlimited" >> /etc/security/limits.conf
echo " hard memlock unlimited" >> /etc/security/limits.conf
(7)创建统一文件夹,后期把程序都放到该文件夹下 【根据磁盘状况】
mkdir -p /home/hadoop
添加各个服务变量
cat <<EOF > /root/.bashrc
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
export JAVA_HOME=/usr/java/jdk1.8.0_171
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/home/hadoop/hadoop-2.8.4
export PATH=$PATH:$HADOOP_HOME/bin
export HBASE_HOME=/home/hadoop/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.12
export PATH=$ZOOKEEPER_HOME/bin:$PATH
export STORM_HOME=/home/hadoop/apache-storm-1.2.2
export PATH=$PATH:$STORM_HOME/bin
export KAFKA_HOME=/home/hadoop/kafka_2.12-1.1.0
export PATH=$PATH:$KAFKA_HOME/bin
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
EOF
如下图:
基础环境已经布置完成,后续......

相关文章推荐
- Hadoop的集群环境部署说明
- hadoop集群环境部署之cloudera
- 在windows环境通过cygwin部署hadoop伪集群
- Hadoop环境部署(单节点和集群)
- Hadoop集群环境部署_lzo
- Hadoop2.7.2 Centos 完全分布式集群环境搭建 (1) - 基础环境准备-1
- Hadoop集群环境安装部署
- hadoop集群环境部署
- Hadoop集群环境部署
- 搭建hadoop集群环境准备centOS系统
- hadoop集群环境部署之rsyncd
- Hadoop 2.5.1 虚拟集群搭建——基本环境准备
- 在windows环境通过cygwin部署hadoop伪集群
- 批量部署Hadoop集群环境(1)
- vmware中hadoop的linux环境集群配置环境准备
- 大数据环境搭建-之-hadoop 2.x分布式部署-集群配置
- 第1.1章 hadoop之hadoop2集群(一)环境准备
- Hadoop集群完全分布式模式环境部署
- Hadoop集群搭建之二 集群环境部署说明+SSH
- 在windows环境通过cygwin部署hadoop伪集群