Hadoop集群启动、初体验
2018-09-04 10:20
441 查看
1. 启动方式
要启动Hadoop集群,需要启动HDFS和YARN两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。
hdfs namenode–format或者hadoop namenode –format
1.1. 单节点逐个启动
在主节点上使用以下命令启动HDFS NameNode:
hadoop-daemon.sh start namenode
在每个从节点上使用以下命令启动HDFS DataNode:
hadoo
1c7c
p-daemon.sh start datanode
在主节点上使用以下命令启动YARN ResourceManager:
yarn-daemon.sh start resourcemanager
在每个从节点上使用以下命令启动YARN nodemanager:
yarn-daemon.sh start nodemanager
以上脚本位于$HADOOP_PREFIX/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start改为stop即可。
1.2. 脚本一键启动
如果配置了etc/hadoop/slaves和ssh免密登录,则可以使用程序脚本启动所有Hadoop两个集群的相关进程,在主节点所设定的机器上执行。
hdfs:$HADOOP_PREFIX/sbin/start-dfs.sh
yarn: $HADOOP_PREFIX/sbin/start-yarn.sh
停止集群:stop-dfs.sh、stop-yarn.sh
2. 集群web-ui
一旦Hadoop集群启动并运行,可以通过web-ui进行集群查看,如下所述:
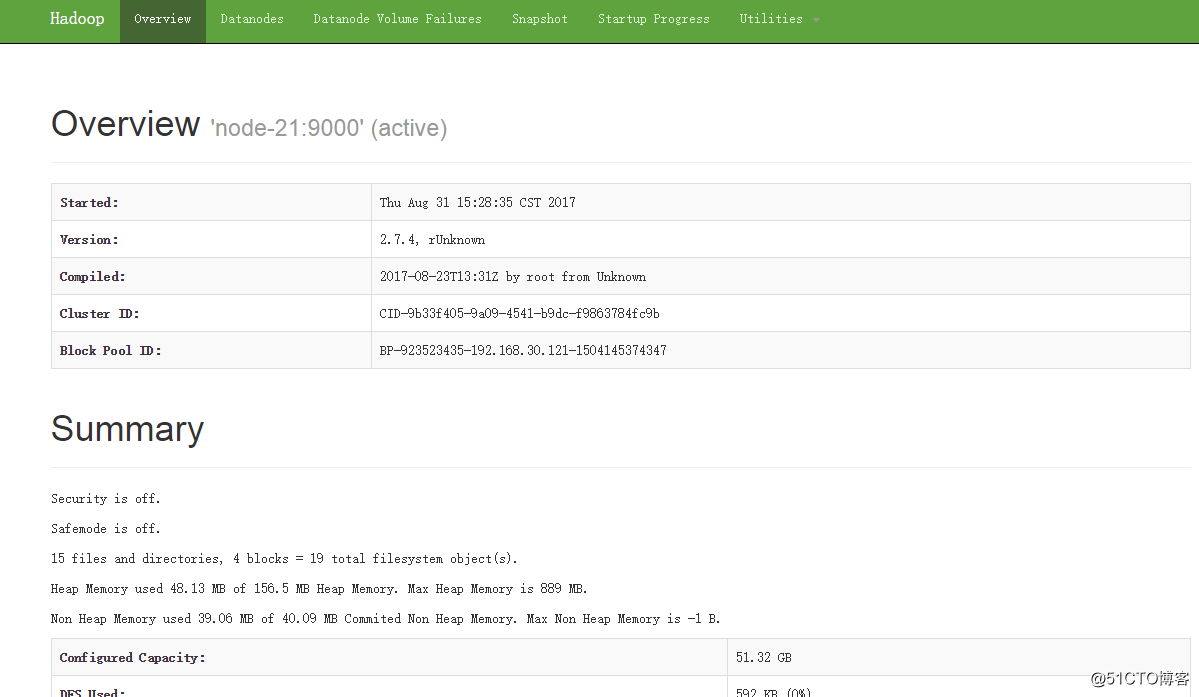
NameNode http://nn_host:port/ 默认50070.
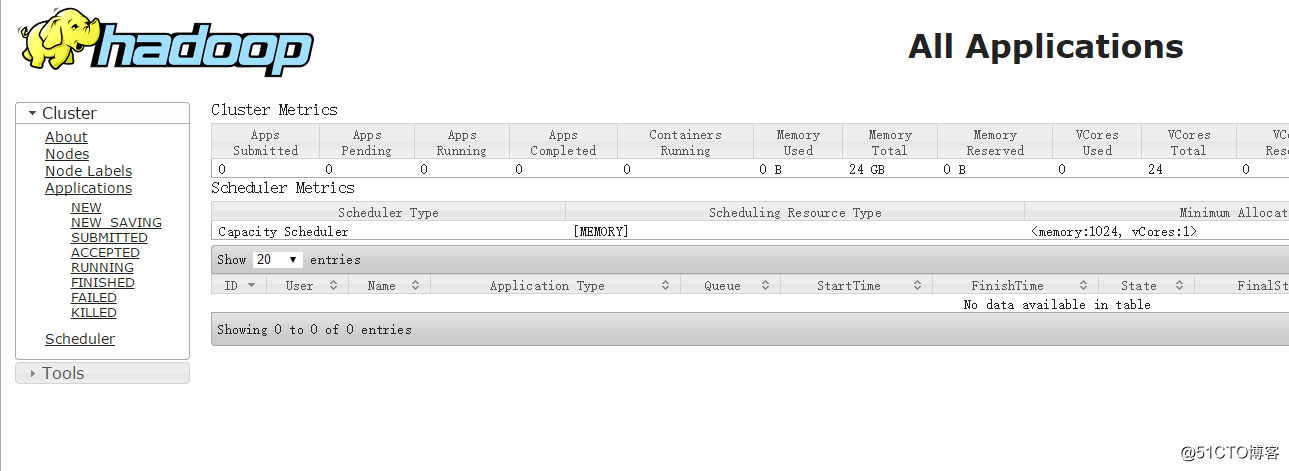
ResourceManager http://rm_host:port/ 默认 8088.
3. Hadoop初体验3.1. HDFS使用
从Linux本地上传一个文本文件到hdfs的/test/input目录下
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put /root/somewords.txt /test/input
3.2. 运行mapreduce程序
在Hadoop安装包的hadoop-2.7.4/share/hadoop/mapreduce下有官方自带的mapreduce程序。我们可以使用如下的命令进行运行测试。
示例程序jar:
hadoop-mapreduce-examples-2.7.4.jar
计算圆周率:
hadoop jar hadoop-mapreduce-examples-2.7.4.jar pi 20 50
关于圆周率的估算,感兴趣的可以查询资料Monte Carlo方法来计算Pi值。
要启动Hadoop集群,需要启动HDFS和YARN两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。
hdfs namenode–format或者hadoop namenode –format
1.1. 单节点逐个启动
在主节点上使用以下命令启动HDFS NameNode:
hadoop-daemon.sh start namenode
在每个从节点上使用以下命令启动HDFS DataNode:
hadoo
1c7c
p-daemon.sh start datanode
在主节点上使用以下命令启动YARN ResourceManager:
yarn-daemon.sh start resourcemanager
在每个从节点上使用以下命令启动YARN nodemanager:
yarn-daemon.sh start nodemanager
以上脚本位于$HADOOP_PREFIX/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start改为stop即可。
1.2. 脚本一键启动
如果配置了etc/hadoop/slaves和ssh免密登录,则可以使用程序脚本启动所有Hadoop两个集群的相关进程,在主节点所设定的机器上执行。
hdfs:$HADOOP_PREFIX/sbin/start-dfs.sh
yarn: $HADOOP_PREFIX/sbin/start-yarn.sh
停止集群:stop-dfs.sh、stop-yarn.sh
2. 集群web-ui
一旦Hadoop集群启动并运行,可以通过web-ui进行集群查看,如下所述:
NameNode http://nn_host:port/ 默认50070.
ResourceManager http://rm_host:port/ 默认 8088.
3. Hadoop初体验3.1. HDFS使用
从Linux本地上传一个文本文件到hdfs的/test/input目录下
hadoop fs -mkdir -p /wordcount/input
hadoop fs -put /root/somewords.txt /test/input
3.2. 运行mapreduce程序
在Hadoop安装包的hadoop-2.7.4/share/hadoop/mapreduce下有官方自带的mapreduce程序。我们可以使用如下的命令进行运行测试。
示例程序jar:
hadoop-mapreduce-examples-2.7.4.jar
计算圆周率:
hadoop jar hadoop-mapreduce-examples-2.7.4.jar pi 20 50
关于圆周率的估算,感兴趣的可以查询资料Monte Carlo方法来计算Pi值。

相关文章推荐
- hadoop集群启动脚本——解决启动hadoop集群时,效率低问题
- hadoop集群启动但不能访问50070
- hadoop集群启动
- HBase HA 集群启动 报错 java.net.UnknownHostException: HadoopCluster
- hadoop集群配置无密码登陆 启动关闭namenode输入密码的解决方法
- hadoop集群启动脚本——解决启动hadoop集群时,效率低问题
- hadoop集群namenode启动不了问题
- hadoop - hadoop2.6 分布式 - 集群环境搭建 - Hadoop 2.6 分布式安装配置与启动
- 启动hadoop集群
- 我的小锦囊之Hadoop集群的启动命令以及经常遇到的小问题
- 在搭建好Hadoop集群后,namenode与datanode两个过程不能起来,或者一个启动之后另一个自动关闭
- hadoop HA 集群启动发现现datanode没有启动,namenode clusterID与datanode clusterID不兼容,不匹配。
- 解决hadoop集群环境datanode无法启动的问题
- hadoop启动集群的免密码登陆设置
- hadoop集群无法启动datanode节点
- Hadoop集群系统版本安装和启动配置
- 【Hadoop】ZooKeeper集群搭建中的Connection refused而导致的启动失败
- hadoop & hbase 集群安装&启动常见问题解决
- hadoop集群中datanode启动几秒钟自动关闭
- hadoop-0.20.2 & hbase-0.90.1 集群启动错误“org.apache.hadoop.ipc.RPC$VersionMismatch: Protocol org.apache.hadoop.hdfs.protocol.ClientP