关于js渲染网页时爬取数据的思路和全过程(附源码)
2018-08-25 21:12
405 查看
于js渲染网页时爬取数据的思路
首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里加上headers.
如果还是没有一个你想要的结果,打印出来 的只是一个框架,那么就可以排除这方面了。就只可能是ajax或者是javascript来渲染的。
就可以按照下图去看一下里面有没有
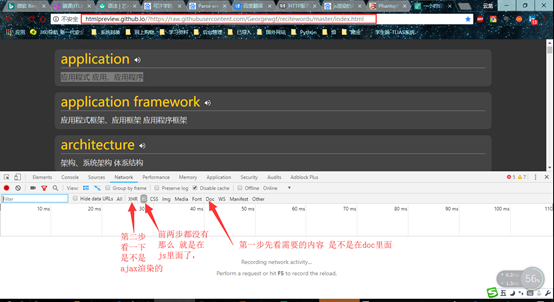
本次先重点去讲一下关于js来渲染网页的数据爬取,这下面的数据是随机找的,只要是里面想要爬取的数据就行 了。
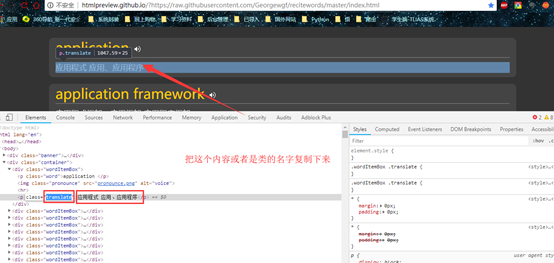
这里ctrl+f就可以搜索到了说明就是在这个js的文件里面
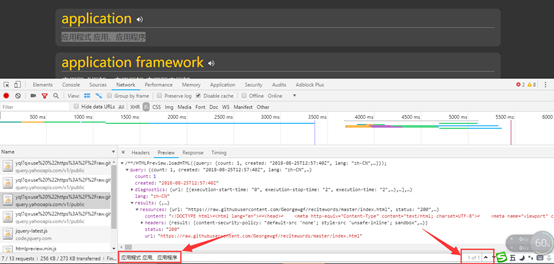
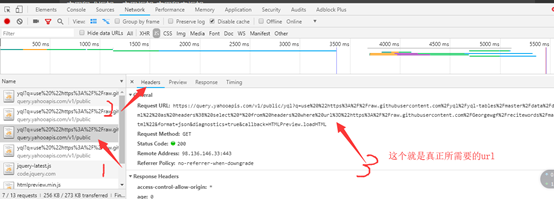

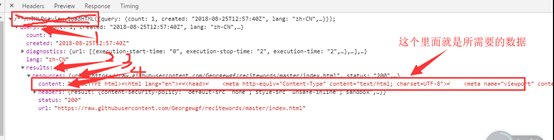
这个就是真正的数据。
剩下的就是可以利用xpath,beautifulsoup或者pyquery来解析得到的网页源码就可以了。
这里我个人推荐此处用pyquery比较方便简单一些。
另附上源码给大家:
import json
from pyquery import
PyQuery as pq
import requests
requests.get()
# 利用爬虫来获取关于程序员的600个单词
def get_web_page():
'''
分析网页,得到结果是一个js渲染的网页,利用requests来把js中的真正的url传递
过来,利用字符串的操作来得到一个真正的json数据
:return: html源码
'''
# 从网上找的一个url地址
url = 'https://query.yahooapis.com/v1/public/yql?q=use%20%22https%3A%2F%2Fraw.githubusercontent.com%2Fyql%2Fyql-tables%2Fmaster%2Fdata%2Fdata.headers.xml%22%20as%20headers%3B%20select%20*%20from%20headers%20where%20url%3D%22https%3A%2F%2Fraw.githubusercontent.com%2FGeorgewgf%2Frecitewords%2Fmaster%2Findex.html%22&format=json&diagnostics=true&callback=HTMLPreview.loadHTML'
# 页面分析得到源码
res = requests.get(url)
json_loads = json.loads(res.text.lstrip('/**/HTMLPreview.loadHTML(').rstrip(');'))
html = json_loads['query']['results']['resources']['content']
# print(html)
return html
def parse_web_page(html):
'''
根据传递过来的网页源码来通过pyquery模块来得到需要的数据
:param html: 网页的源码
:return: 所需要的内容,单词和翻译
'''
# 把网页源码放到pyquery解析器中
doc = pq(html)
# 根据class为wordItemBox的来筛选需要的内容块并得到一个生成器来为了方便下面数据的遍历
contents = doc('.wordItemBox').items()
# 把需要的数据遍历并得到真正的内容
for temp
in contents:
word = temp('.word').text()
translate = temp('.translate').text()
# 返回数据
return word, translate
def main():
'''利用爬虫来获取关于程序员的600个单词'''
# 得到的网页源码
html = get_web_page()
# 解析网页得到需要的数据
content = parse_web_page(html)
# 打印需要的数据
print(content)
if __name__ == '__main__':
main()

相关文章推荐
- 关于通过网页查看JS源码中汉字显示乱码的解决方法
- Vue.js源码学习四 —— 渲染 Render 初始化过程学习
- 网页爬虫抓取js动态渲染数据
- 网页图表 开源工具Chart.js中关于Y轴数据从浮点数修改至整数展示的方法
- 网页爬虫抓取js动态渲染数据
- angularjs-渲染完数据后执行js
- Python分布式爬虫前菜(2):关于提取网页源码中特定信息的技巧
- spark-parquet列存储之:数据写入过程源码分析
- 关于js继承---Base类的源码解析
- 分享》:关于阅读开源项目的源码思路方法
- 原生js的ajax数据渲染
- 关于用Matlab训练BP神经网络过程中显示的数据的意义
- 浏览器将数据进行计算渲染的过程
- 抓取网页中的内容、如何解决乱码问题、如何解决登录问题以及对所采集的数据进行处理显示的过程
- phantomjs介绍-(js网页截屏、javascript网页解析渲染工具)
- Vue2.4.2源码探究之渲染过程1
- 关于面对对象过程中的三大架构以及数据访问层(实体类、数据操作类)
- Vue.js基础指令实例讲解(各种数据绑定、表单渲染大总结)
- java 关于项目导出功能实现过程中遇到的问题及思路历程
- 关于网页动态数据获取的知识学习(2)