数据分析与挖掘入门——学习笔记(四)利用NumPy进行历史股价分析
2018-08-22 10:55
459 查看
利用NumPy进行历史股价分析
该练习使用的csv文件如下:
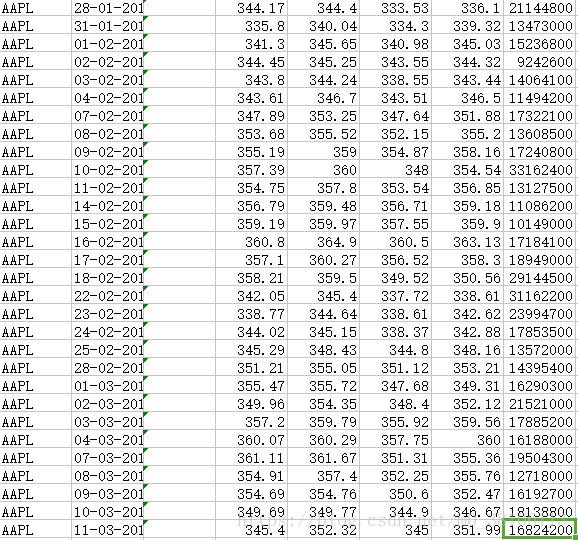
其中第二列为日期,格式是%d-%m-%Y;第四到七列分别是当日开盘价,最高价,最低价,收盘价和成交量
准备工作:
import sys
import numpy as np
# 读入文件,函数是loadtxt
# 第一个参数是文件名,delimiter是获取的数据的分隔符,usecols是指定读取哪列的数据,unpack为True表示获取的数据根据列分为不同的数组
# 这里分隔符是“,”,读取第6,7行(收盘价和交易量),unpack为true,分开存储为不同的变量
c, v = np.loadtxt('./data.csv', delimiter=',', usecols=(6, 7), unpack=True)
1 计算成交量加权平均值
np中使用average()计算加权平均值,第一个参数为计算的数组,第二个参数为加权平均值的权重
vwap = np.average(c, weights=v) vwap # 350.58954935320088
2 计算算术平均值
np.mean(c) # 计算算术平均值 # 351.03766666666672
3 计算时间加权平均值
t = np.arange(len(c)) np.average(c, weights=t) # 计算时间加权平均值 # 352.42832183908041
4 寻找最大值和最小值
h,l = np.loadtxt('./data.csv', delimiter=',', usecols=(4, 5), unpack=True)
np.max(h)
# 364.89999999999998
np.min(l)
# 333.52999999999997
5 计算中程数和极差
(np.max(h) + np.min(l)) / 2 # 计算中程数 # 349.21499999999997 np.ptp(h) # 计算最大值和最小值之间的差值 极差 # 24.859999999999957 np.ptp(l) # 计算交易量的极差 # 26.970000000000027
6 统计分析
c = np.loadtxt('./data.csv', delimiter=',', usecols=(6,), unpack=True) # 读取收盘价
np.median(c) # 中间数
# 352.05500000000001
sorted = np.msort(c)
sorted # 可见中间数是351.99和352.12的平均值
# array([ 336.1 , 338.61, 339.32, 342.62, 342.88, 343.44, 344.32,
# 345.03, 346.5 , 346.67, 348.16, 349.31, 350.56, 351.88,
# 351.99, 352.12, 352.47, 353.21, 354.54, 355.2 , 355.36,
# 355.76, 356.85, 358.16, 358.3 , 359.18, 359.56, 359.9 ,
# 360. , 363.13])
np.var(c) # 方差的计算
# 50.126517888888884
np.mean((c - c.mean()) ** 2) # 手动计算方差
# 50.126517888888884
7 股票收益率计算
c = np.loadtxt('./data.csv', delimiter=',', usecols=(6,), unpack=True)
returns = np.diff(c) / c[: -1] # diff计算差分,总体是求股票收益率
np.std(returns) # 求标准差
# 0.012922134436826306
log_returns = np.diff(np.log(c)) # 股票对数收益率
log_returns
# array([ 0.00953488, 0.01668775, -0.00205991, -0.00255903, 0.00887039,
# 0.01540739, 0.0093908 , 0.0082988 , -0.01015864, 0.00649435,
# 0.00650813, 0.00200256, 0.00893468, -0.01339027, -0.02183875,
# -0.03468287, 0.01177296, 0.00075857, 0.01528161, 0.01440064,
# -0.011103 , 0.00801225, 0.02090904, 0.00122297, -0.01297267,
# 0.00112499, -0.00929083, -0.01659219, 0.01522945])
posretindices = np.where(returns > 0) # 求收益率大于0的那几天
posretindices
# (array([ 0, 1, 4, 5, 6, 7, 9, 10, 11, 12, 16, 17, 18, 19, 21, 22, 23,
# 25, 28], dtype=int64),)
ann_vol = np.std(log_returns) / np.mean(log_returns) # 日收益率
ann_vol = ann_vol / np.sqrt(1. / 252.) # 年收益率
ann_vol
# 129.27478991115132
ann_vol * np.sqrt( 1. / 12.) # 月收益率
# 37.318417377317765
8 日期分析
用以下数字代表星期
Monday 0
Tuesday 1
Wednesday 2
Thursday 3
Friday 4
星期六日股市休市,不考虑了
定义一个把日期转换为数字的函数
from datetime import datetime
def date2num(s):
return datetime.strptime(s, '%d-%m-%Y').date().weekday()
# 读取收盘价
close = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
# 读取日期
dates = np.loadtxt('data.csv', delimiter=',', usecols=(1,), unpack=True, dtype=bytes).astype(str)
# 将读取的str数据转换为数字
for i in range(dates.size):
dates[i] = date2num(dates[i])
dates = dates.astype(np.int8)
dates.dtype
# dtype('int8')
averages = np.zeros(5) # 定义一个空数组
# 依次获取不同天的索引,然后根据索引求得close(收盘价)数组中所有的对应值,计算平均值,把平均值加入到averages数组中
for i in range(5):
indices = np.where(dates == i)
prices = np.take(close, indices)
avg = np.mean(prices)
print("Day", i, "prices", prices, "Average", avg)
averages[i] = avg
# Day 0 prices [[ 339.32 351.88 359.18 353.21 355.36]] Average 351.79
# Day 1 prices [[ 345.03 355.2 359.9 338.61 349.31 355.76]] Average 350.635
# Day 2 prices [[ 344.32 358.16 363.13 342.62 352.12 352.47]] Average 352.136666667
# Day 3 prices [[ 343.44 354.54 358.3 342.88 359.56 346.67]] Average 350.898333333
# Day 4 prices [[ 336.1 346.5 356.85 350.56 348.16 360. 351.99]] Average 350.022857143
top = np.max(averages) # 计算周每日的收盘价平均值的最大值
# 352.1366666666666
np.argmax(averages) # 获取周每日的收盘价平均值的最大值是哪一天
# 2
bottom = np.min(averages) # 计算周每日的收盘价平均值的最小值
# 350.02285714285711
np.argmin(averages) # 获取周每日的收盘价平均值的最小值是哪一天
# 4
9 周数据汇总
以周为单位进行计算
#读取日期
dates = np.loadtxt('data.csv', delimiter=',', usecols=(1,), unpack=True, dtype=bytes).astype(str)
for i in range(dates.size):
dates[i] = date2num(dates[i])
dates = dates.astype(np.int8)
dates.dtype
# dtype('int8')
open, high, low, close=np.loadtxt('data.csv', delimiter=',', usecols=(3, 4, 5, 6), unpack=True)
close = close[:16] # 因为后面有一周的星期五是放假,所以不纳入计算,再往后数据不齐,也不计算
dates = dates[:16]
first_Monday = np.ravel(np.where(dates == 0))[0] # 获取第一个星期一
first_Monday
# 1
last_Friday = np.ravel(np.where(dates == 4))[-1]
last_Friday
# 15
# 将这十五天分割为三个星期
week_indices = np.arange(first_Monday, last_Friday + 1)
week_indices
# array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], dtype=int64)
week_indices = np.split(week_indices, 3)
week_indices
# [array([1, 2, 3, 4, 5], dtype=int64),
# array([ 6, 7, 8, 9, 10], dtype=int64),
# array([11, 12, 13, 14, 15], dtype=int64)]
# 计算每个星期的最高价,最低价,星期一开盘价,星期五收盘价
def summarizer(a, o , h, l, c):
Monday_open = o[a[0]]
week_high = np.max(np.take(h, a))
week_low = np.min(np.take(l, a))
Friday_close = c[a[-1]]
return ("APPL", Monday_open, week_high, week_low, Friday_close)
weeksummary = np.apply_along_axis(summarizer, 1, week_indices, open, high, low, close)
weeksummary
# array([['APPL', '335.8', '346.7', '334.3', '346.5'],
# ['APPL', '347.8', '360.0', '347.6', '356.8'],
# ['APPL', '356.7', '364.9', '349.5', '350.5']],
# dtype='<U5')
# 保存结果,第一个参数为文件名,第二个参数为保存的数组,第三个参数为分隔符,fmt为保存的数据格式
np.savetxt("weeksummary.csv", weeksummary, delimiter=",", fmt="%s")
10 真实波动幅度均值
# 读取最大值,最小值,收盘价
h, l, c = np.loadtxt('data.csv', delimiter=',', usecols=(4, 5, 6), unpack=True)
N = 20
h = h[-N:]
l = l[-N:]
len(h)
# 20
pre_close = c[-N -1: -1] # 倒数第二十一的数值到倒数第一的数值
len(pre_close)
# 20
pre_close
# array([ 354.54, 356.85, 359.18, 359.9 , 363.13, 358.3 , 350.56,
# 338.61, 342.62, 342.88, 348.16, 353.21, 349.31, 352.12,
# 359.56, 360. , 355.36, 355.76, 352.47, 346.67])
# 获取当日最高价和最低价的差价,当日最高价和前一日收盘价差价,前一日收盘价和当日最低价的差价,求三者中的最大值
truerange = np.maximum(h - l, h - pre_close, pre_close - l)
truerange
# array([ 4.26, 2.77, 2.42, 5. , 3.75, 9.98, 7.68, 6.03,
# 6.78, 5.55, 6.89, 8.04, 5.95, 7.67, 2.54, 10.36,
# 5.15, 4.16, 4.87, 7.32])
# 计算股票的ATR
atr = np.zeros(N)
atr[0] = np.mean(truerange)
for i in range(1, N):
atr[i] = (N-1) * atr[i - 1] + truerange[i]
atr[i] /= N
print("ATR", atr)
# ATR [ 5.8585 5.704075 5.53987125 5.51287769 5.4247338 5.65249711
# 5.75387226 5.76767864 5.81829471 5.80487998 5.85913598 5.96817918
# 5.96727022 6.05240671 5.87678637 6.10094705 6.0533997 5.95872972
# 5.90429323 5.97507857]
11 简单移动平均线
from matplotlib.pyplot import plot
from matplotlib.pyplot import show
N = 5
weights = np.ones(N) / N
weights
# array([ 0.2, 0.2, 0.2, 0.2, 0.2])
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
sma = np.convolve(weights, c)[N-1: -N+1] # 计算移动平均值, convolve(权重, 数组)
sma
# array([ 341.642, 343.722, 346.234, 348.268, 351.036, 353.256,
# 355.326, 356.786, 357.726, 358.72 , 359.472, 358.214,
# 354.1 , 350.644, 346.594, 344.566, 345.096, 347.236,
# 349.136, 352.472, 354.84 , 355.27 , 356.56 , 356.63 ,
# 354.052, 352.45 ])
t = np.arange(N -1, len(c))
# array([ 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
# 21, 22, 23, 24, 25, 26, 27, 28, 29])
plot(t, c[N-1:], lw=1.0)
plot(t, sma, lw=2.0)
show()
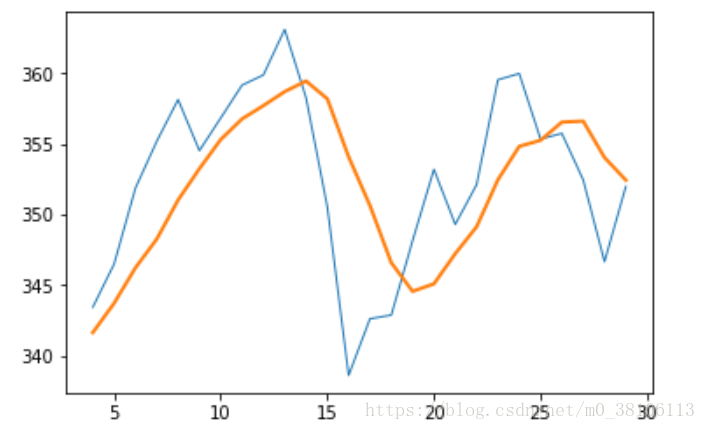
蓝色的线是原本的数值变化,橘色的线是简单移动平均线
12 指数移动平均线
x = np.arange(5)
np.exp(x) # 计算指数
np.linspace(-1, 0, 5)
# array([-1. , -0.75, -0.5 , -0.25, 0. ])
N = 5
weights = np.exp(np.linspace(-1., 0., N))
weights /= weights.sum() # 计算权重
weights
# array([ 0.11405072, 0.14644403, 0.18803785, 0.24144538, 0.31002201])
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
ema = np.convolve(weights, c)[N-1:-N+1]
t = np.arange(N - 1, len(c))
plot(t, c[N-1:], lw=1.0)
plot(t, sma, lw=2.0)
plot(t, ema, lw=2.0)
show()

绿色的是指数加权平均线,比起橘色的简单移动平均线稍微往前靠
13 布林带
用于刻画价格的波动区域,分为中规(简单移动平均线),上轨(比中轨高出2倍标准差),下轨(比中轨低2倍标准差)
N = 5
weights = np.ones(N) / N
weights
# array([ 0.2, 0.2, 0.2, 0.2, 0.2])
c = np.loadtxt('data.csv', delimiter=',', usecols=(6,), unpack=True)
sma = np.convolve(weights, c)[N-1:-N+1]
deviation = []
C = len(c)
for i in range(N -1, C):
if i + N < C:
dev = c[i: i+N]
else:
dev = c[-N:]
averages = np.zeros(N)
averages.fill(sma[i - N -1])
dev = dev - averages
dev = dev ** 2
dev = np.sqrt(np.mean(dev))
deviation.append(dev)
deviation = 2 * np.array(deviation)
print(len(deviation), len(sma))
upperBB = sma + deviation
lowerBB = sma - deviation
c_slice = c[N-1:]
between_bands = np.where((c_slice < upperBB) & (c_slice > lowerBB))
print(lowerBB[between_bands])
print(c[between_bands])
print(upperBB[between_bands])
between_bands = len(np.ravel(between_bands))
print("Ratio between bands", float(between_bands)/len(c_slice))
t = np.arange(N - 1, C)
plot(t, c_slice, lw=1.0)
plot(t, sma, lw=2.0)
plot(t, upperBB, lw=3.0)
plot(t, lowerBB, lw=4.0)
show()
结果如下:
26 26 [ 329.23044409 335.70890572 318.53386282 321.90858271 327.74175968 331.5628136 337.94259734 343.84172744 339.99900409 336.58687297 333.15550418 328.64879207 323.61483771 327.25667796 334.30323599 335.79295948 326.55905786 324.27329493 325.47601386 332.85867025 341.63882551 348.75558399 348.48014357 348.01342992 343.56371701 341.85163786] [ 336.1 339.32 345.03 344.32 343.44 346.5 351.88 355.2 358.16 354.54 356.85 359.18 359.9 363.13 358.3 350.56 338.61 342.62 342.88 348.16 353.21 349.31 352.12 359.56 360. 355.36] [ 354.05355591 351.73509428 373.93413718 374.62741729 374.33024032 374.9491864 372.70940266 369.73027256 375.45299591 380.85312703 385.78849582 387.77920793 384.58516229 374.03132204 358.88476401 353.33904052 363.63294214 370.19870507 372.79598614 372.08532975 368.04117449 361.78441601 364.63985643 365.24657008 364.54028299 363.04836214] Ratio between bands 1.0


相关文章推荐
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
- 利用python进行数据分析-pandas入门
- 利用python进行数据分析-pandas入门2
- 数据分析与挖掘入门——学习笔记(五)Matplotlib的简介、折线图与基础绘画功能
- 利用 Python 进行数据分析(四)NumPy 基础:ndarray 简单介绍
- 利用python进行数据分析-NumPy基础2
- 利用Python进行数据分析——第8章绘图及可视化——学习笔记Python3 5.0.0
- 数据分析与挖掘入门——学习笔记(七)Pandas简介与其数据结构
- 银行金融领域,如何利用数据挖掘对客户进行深入分析?
- Python数据挖掘:利用聚类算法进行航空公司客户价值分析
- 利用Pythonj进行数据分析学习笔记——第五章 pandas入门
- 利用python进行数据分析-NumPy高级应用
- 数据分析与挖掘入门——学习笔记(八)Pandas基本操作、运算、画图和IO操作
- 利用Python进行数据分析_python3实现_pandas入门_相关系数与协方差
- 利用python进行数据分析-NumPy基础
- 数据分析与挖掘入门——学习笔记(九)Pandas高级操作
- 数据分析与挖掘入门——学习笔记(六)matplotlib的常用图表
- 如何利用数据挖掘进行分析的方法
- 利用Python进行数据分析(6) NumPy基础: 矢量计算
- 利用Python进行数据分析(五)之pandas入门