python数据分析之爬虫五:实例
实例一:淘宝商品比价定向爬虫
打开淘宝,输入衬衫,链接为:
第二页的链接为:
第三页的链接为:
发现翻页操作是通过后边的参数s来操作的,每页44个商品。
ps:不知道为什么原来的链接里边 search?q=衬衫 复制过来就变成了上述打不开的链接。
哈哈,这里突然发现 https://s.taobao.com/search?q=衬衫(自己码的,不是复制过来的)就可以进去了。
输入https://s.taobao.com/search?q=衬衫&s=44 哈哈发现翻了页了。


这里提取出名称,价格还有付款人数。
首先分析定向爬虫的可行性
进入网址:http://s.taobao.com/robots.txt 查看
程序结构设计

进入衬衫页面,查看网页源代码,按照第一个衬衫的名称,价格,已购人数搜索源码(ctrl+f)查看数据是怎么存在的。
主程序:
[code]import requests
import re
def getHTMLText(url):
print("")
def parserPage(ilt,html):
print("")
def printGoodsList(ilt):
print("")
def main():
goods="衬衫" #指定商品名称
depth=2 #指定爬取的页面个数
start_url='https://s.taobao.com/search?q='+goods
infoList=[]
for i in range(depth):
try:
url=start_url+"&s="+str(44*i)
html=getHTMLText(url)
parserPage(infoList,html)
except:
continue
printGoodsList(infoList)
main()
对各函数进行填充:
[code]def getHTMLText(url): try: r=requests.get(url,timeout=30) #时间限制为30秒 r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return ""
[code]def parserPage(ilt,html):
try:
#返回商品名称的列表,?是最小匹配。加\是为了转义。s
ns=re.findall(r'\"raw_title\"\:\".*?\"',html)
#返回价格的列表,[\d\.]*这个好好消化
jiage=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
#返回已购人数列表
renshu=re.findall(r'\"view_sales\"\:\".*?\"',html)
for i in range(len(ns)):
#将raw_title去掉,eval函数的意思是吧返回的字符串中的最外层单引号或双引号去掉。
name=eval(ns[i].split(':')[1])
print(name)
price=eval(jiage[i].split(':')[1])
print(price)
people=eval(renshu[i].split(':')[1])
print(people)
ilt.append([price,people,name])
except:
print("")
[code]def printGoodsList(ilt):
tplt="{:<4}\t{:<6}\t{:<10}\t{:<10}"
print(tplt.format("序号","价格","已购人数","商品名称"))
count=0
for j in ilt:
count+=1
print(tplt.format(count,j[0],j[1].split('人')[0],j[2]))
总代码为:
[code]import requests
import re
def getHTMLText(url):
try:
r=requests.get(url,timeout=30) #时间限制为30秒
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def parserPage(ilt,html):
try:
#返回商品名称的列表,?是最小匹配。加\是为了转义。s
ns=re.findall(r'\"raw_title\"\:\".*?\"',html)
#返回价格的列表,[\d\.]*这个好好消化
jiage=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
#返回已购人数列表
renshu=re.findall(r'\"view_sales\"\:\".*?\"',html)
for i in range(len(ns)):
#将raw_title去掉,eval函数的意思是吧返回的字符串中的最外层单引号或双引号去掉。
name=eval(ns[i].split(':')[1])
print(name)
price=eval(jiage[i].split(':')[1])
print(price)
people=eval(renshu[i].split(':')[1])
print(people)
ilt.append([price,people,name])
except:
print("")
def printGoodsList(ilt):
tplt="{:<4}\t{:<6}\t{:<10}\t{:<10}"
print(tplt.format("序号","价格","已购人数","商品名称"))
count=0
for j in ilt:
count+=1
print(tplt.format(count,j[0],j[1].split('人')[0],j[2]))
def main():
goods="衬衫" #指定商品名称
depth=2 #指定爬取的页面个数
start_url='https://s.taobao.com/search?q='+goods
infoList=[]
for i in range(depth):
try:
url=start_url+"&s="+str(44*i)
html=getHTMLText(url)
parserPage(infoList,html)
except:
continue
printGoodsList(infoList)
main()
结果如下:

ps: 注意eval函数这个知识点

输出到excel中去
[code]import requests
import re
import pandas as pd
def getHTMLText(url):
try:
r=requests.get(url,timeout=30) #时间限制为30秒
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def parserPage(ilt,html):
try:
#返回商品名称的列表,?是最小匹配。加\是为了转义。s
ns=re.findall(r'\"raw_title\"\:\".*?\"',html)
#返回价格的列表,[\d\.]*这个好好消化
jiage=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
#返回已购人数列表
renshu=re.findall(r'\"view_sales\"\:\".*?\"',html)
for i in range(len(ns)):
#将raw_title去掉,eval函数的意思是吧返回的字符串中的最外层单引号或双引号去掉。
name=eval(ns[i].split(':')[1])
#print(name)
price=eval(jiage[i].split(':')[1])
#print(price)
people=eval(renshu[i].split(':')[1])
#print(people)
ilt.append([price,people,name])
except:
print("")
def saveGoodsList(ilt):
ilts=[]
for j in ilt:
ilts.append([j[0],j[1].split('人')[0],j[2]])
fpath=r'C:\Users\LPH\Desktop\chenshan.xlsx'
a=pd.DataFrame(ilts,columns=['价格','已购人数','商品名称'])
a.to_excel(fpath)
def main():
goods="衬衫" #指定商品名称
depth=2 #指定爬取的页面个数
start_url='https://s.taobao.com/search?q='+goods
infoList=[]
for i in range(depth):
try:
url=start_url+"&s="+str(44*i)
html=getHTMLText(url)
parserPage(infoList,html)
except:
continue
saveGoodsList(infoList)
main()
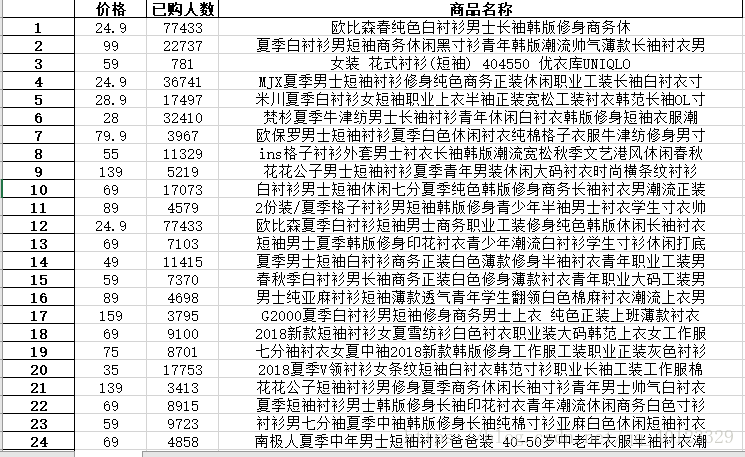
效果如图:
实例二:股票数据定向爬虫


对于新浪股票,进入网站后,选取任意一个股票的价格,在网页源码中搜索价格,找不到,说明是由js代码生成。
对于百度股票,进入网站,打开个股,查看其价格是否在HTML页面中。,找到了。说明百度股票适合作为定向爬取的
数据来源。
需要找到包含所有股票的列表,但在百度股票中很难找到一个页面包含所有股票。可以去东方财富网爬取股票列表信息。
http://quote.eastmoney.com/stocklist.html
百度股票中每一个个股网址中都包含了个股的数字代码和2个字母的字符串。

因此程序结构框架为:

函数代码:
[code]import requests
import re
import traceback #方便调试
from bs4 import BeautifulSoup
import bs4 #因为用了isinstance函数,其中的第二个参数是bs4.element.Tag
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def getStockList(lst,StockURL):#去东方财富网获得股票列表
html=getHTMLText(StockURL)
soup=BeautifulSoup(html,'html.parser')
a=soup.find_all('a')
for i in a:
try:
href=i.attrs['href']
lst.append(re.findall(r'[s][hz]\d{6}',href)[0])
except:
continue
def getStockInfo(lst,stockURL,fpath): #根据股票列表获取个股信息
for stock in lst:
url = stockURL + stock + '.html'
html = getHTMLText(url)
try:
if html=='':
continue
infoDict={}
soup=BeautifulSoup(html,"html.parser")
stockInfo=soup.find('div',attrs={'class':'stock-bets'})
#print(type(stockInfo)) 发现其中有<class 'bs4.element.Tag'> <class 'NoneType'>两种类型
#如果不区分,就会得到name=stockInfo.find_all(attrs={'class':'bets-name'})[0]
#AttributeError: 'NoneType' object has no attribute 'find_all' 这个结果
if isinstance(stockInfo,bs4.element.Tag):
name=stockInfo.find_all(attrs={'class':'bets-name'})[0]
# 采用空格分割,split什么也不写就表示空格。可以百度字典的update方法
#标签有text属性?是的,而且比string好用。
infoDict.update({'股票名称':name.text.split()[0]})
keylist=stockInfo.find_all('dt') #标签dt的内容作为键
valuelist=stockInfo.find_all('dd') #标签dd的内容作为值
for i in range(len(keylist)):
key=keylist[i].text
val=valuelist[i].text
infoDict[key]=val
with open(fpath,'a',encoding='utf-8') as f:
#写入的对象必须是字符类型。而且如果要每个股票占据一行,要加换行符。
f.write(str(infoDict)+'\n')
except:
traceback.print_exc()
continue
def main():
stock_list_url='http://quote.eastmoney.com/stocklist.html'
stock_info_url='https://gupiao.baidu.com/stock/'
output_file=r'C:\Users\LPH\Desktop\stock.txt'
slist=[]
getStockList(slist,stock_list_url)
getStockInfo(slist,stock_info_url,output_file)
main()
对过程进行优化(增加用户体验)
- 一 速度提高:编码识别的优化
r.encoding=r.apparent_encoding
后者根据文本通过程序来分析文本的编码方式,前者从HTML头文件中解析它可能用到的编码方式。前者的获取很费时间。对于定向爬虫,可以自己手工获取文本编码方式,节省时间。
首先修改getHTMLText函数
[code]def getHTMLText(url,code='utf-8'): try: r=requests.get(url) r.raise_for_status() r.encoding=code return r.text except: return ""
再查得东方财富网股票列表网页的编码方式是:GBK(右键 编码)
修改getStockList函数
[code]def getStockList(lst,StockURL):#去东方财富网获得股票列表
html=getHTMLText(StockURL,'GBK')
soup=BeautifulSoup(html,'html.parser')
a=soup.find_all('a')
for i in a:
try:
href=i.attrs['href']
lst.append(re.findall(r'[s][hz]\d{6}',href)[0])
except:
continue
由于百度股票是UTF-8编码,因此是默认情况。
- 二增加动态进度显示(不换行显示的动态进度条)
\r可以将打印的字符串的最后的光标提到当前行打印信息的头部,下次再进行相关信息打印时,会覆盖原来的信息。
但\r这个功能被IDLE禁止。
[code] with open(fpath,'a',encoding='utf-8') as f:
#写入的对象必须是字符类型。而且如果要每个股票占据一行,要加换行符。
f.write(str(infoDict)+'\n')
count+=1
#end='' 因为print函数每次都会在输出后自动添加换行。
print('\r当前速度:{:.2f}%'.format(count*100/len(lst)),end='')
except:
count+=1
# end='' 因为print函数每次都会在输出后自动添加换行。
print('\r当前速度:{:.2f}%'.format(count * 100 / len(lst)), end='')
traceback.print_exc()
continue
完整代码:
[code]import requests
import re
import traceback #方便调试
from bs4 import BeautifulSoup
import bs4 #因为用了isinstance函数,其中的第二个参数是bs4.element.Tag
def getHTMLText(url,code='utf-8'):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=code
return r.text
except:
return ""
def getStockList(lst,StockURL):#去东方财富网获得股票列表
html=getHTMLText(StockURL,'GBK')
soup=BeautifulSoup(html,'html.parser')
a=soup.find_all('a')
for i in a:
try:
href=i.attrs['href']
lst.append(re.findall(r'[s][hz]\d{6}',href)[0])
except:
continue
def getStockInfo(lst,stockURL,fpath): #根据股票列表获取个股信息
count=0
for stock in lst:
url = stockURL + stock + '.html'
html = getHTMLText(url)
try:
if html=='':
continue
infoDict={}
soup=BeautifulSoup(html,"html.parser")
stockInfo=soup.find('div',attrs={'class':'stock-bets'})
#print(type(stockInfo)) 发现其中有<class 'bs4.element.Tag'> <class 'NoneType'>两种类型
#如果不区分,就会得到name=stockInfo.find_all(attrs={'class':'bets-name'})[0]
#AttributeError: 'NoneType' object has no attribute 'find_all' 这个结果
if isinstance(stockInfo,bs4.element.Tag):
name=stockInfo.find_all(attrs={'class':'bets-name'})[0]
# 采用空格分割,split什么也不写就表示空格。可以百度字典的update方法
#标签有text属性?是的,而且比string好用。
infoDict.update({'股票名称':name.text.split()[0]})
keylist=stockInfo.find_all('dt') #标签dt的内容作为键
valuelist=stockInfo.find_all('dd') #标签dd的内容作为值
for i in range(len(keylist)):
key=keylist[i].text
val=valuelist[i].text
infoDict[key]=val
with open(fpath,'a',encoding='utf-8') as f:
#写入的对象必须是字符类型。而且如果要每个股票占据一行,要加换行符。
f.write(str(infoDict)+'\n')
count+=1
#end='' 因为print函数每次都会在输出后自动添加换行。
print('\r当前速度:{:.2f}%'.format(count*100/len(lst)),end='')
except:
count+=1
# end='' 因为print函数每次都会在输出后自动添加换行。
print('\r当前速度:{:.2f}%'.format(count * 100 / len(lst)), end='')
traceback.print_exc()
continue
def main():
stock_list_url='http://quote.eastmoney.com/stocklist.html'
stock_info_url='https://gupiao.baidu.com/stock/'
output_file=r'C:\Users\LPH\Desktop\stock.txt'
slist=[]
getStockList(slist,stock_list_url)
getStockInfo(slist,stock_info_url,output_file)
main()
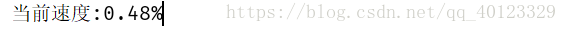
慢的跟啥一样......
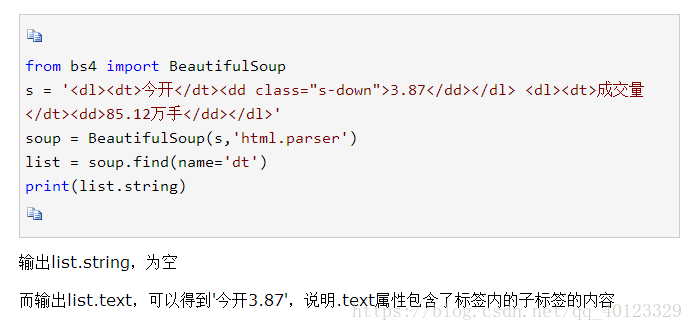
注意:soup.a.string与soup.a.text的区别(后者比前者好用)
https://www.cnblogs.com/Alexzzzz/p/6812766.html
https://blog.csdn.net/qq_36525166/article/details/81258168
阅读更多

- python网络编程之数据传输UDP实例分析
- Python数据采集处理分析挖掘可视化应用实例
- 通过实例快速掌握sklearn中的kmeans聚类----python数据分析,聚类,pandas
- Python爬虫(urllib2+bs4)+分析找出谁是水贴王(2)--数据分析
- Python 爬虫和数据分析实战
- $用python玩点有趣的数据分析——一元线性回归分析实例
- Python实现微信公众号爬虫进行数据分析
- 数据分析——以斗鱼为实例解析requests库与scrapy框架爬虫技术
- 用python玩点有趣的数据分析——一元线性回归分析实例
- Python网络爬虫与信息提取-Day14-(实例)股票数据定向爬虫
- Python网络爬虫实战:根据天猫胸罩销售数据分析中国女性胸部大小分布
- 【Python数据分析】简单爬虫 爬取知乎神回复
- 【Python数据分析】简单爬虫,爬取知乎神回复
- Python爬虫爬取京东内存条数据并作简单分析
- Python爬虫----实例: 抓取百度百科Python词条相关1000个页面数据
- python用BeautifulSoup库简单爬虫实例分析
- 开启菜鸟的python爬虫与数据分析之旅
- 【Python高级工程师之路】入门+进阶+实战+爬虫+数据分析整套教程
- python&php数据抓取、爬虫分析与中介,有网址案例
- python数据分析之爬虫六:Scrapy爬虫