实时数据平台设计:技术选型与应用场景适配模式 - 大数据
2018-08-09 10:15
1126 查看
实时数据平台(RTDP,Real-time Data Platform)是一个重要且常见的大数据基础设施平台。在上篇《实时数据平台设计:解决从OLTP到OLAP实时流转缺失》中,我们从现代数仓架构角度和典型数据处理角度介绍了RTDP,并探讨了RTDP的整体设计架构。
本文作为下篇,则是从技术角度入手,介绍RTDP的技术选型和相关组件,探讨适用不同应用场景的相关模式。RTDP的敏捷之路就此展开:
一、技术选型介绍
在上篇中,我们给出了RTDP的一个整体架构设计(图1),而本文我们则会推荐整体技术组件选型,对每个技术组件做出简单介绍,尤其对我们抽象并实现的四个技术平台(统一数据采集平台、统一流式处理平台、统一计算服务平台、统一数据可视化平台)着重介绍设计思路;对Pipeline端到端切面话题进行探讨,包括功能整合、数据管理、数据安全等。
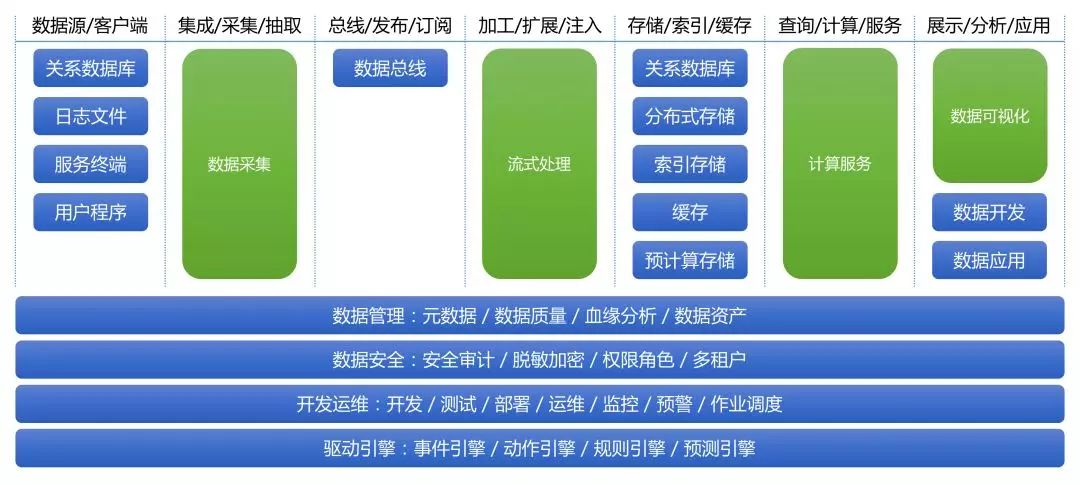
(图1)
1整体技术选型
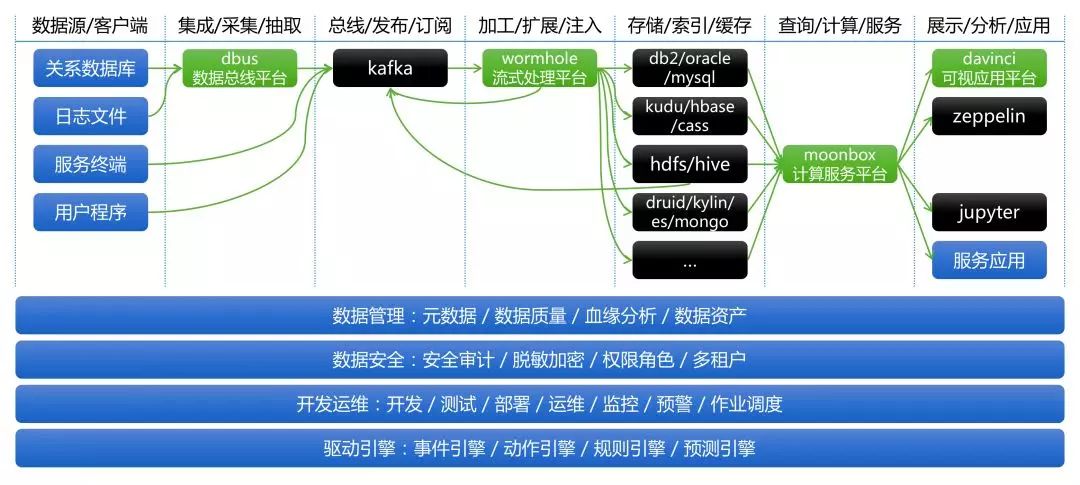
(图2)
首先,我们简要解读一下图2:
数据源、客户端,列举了大多数数据应用项目的常用数据源类型。
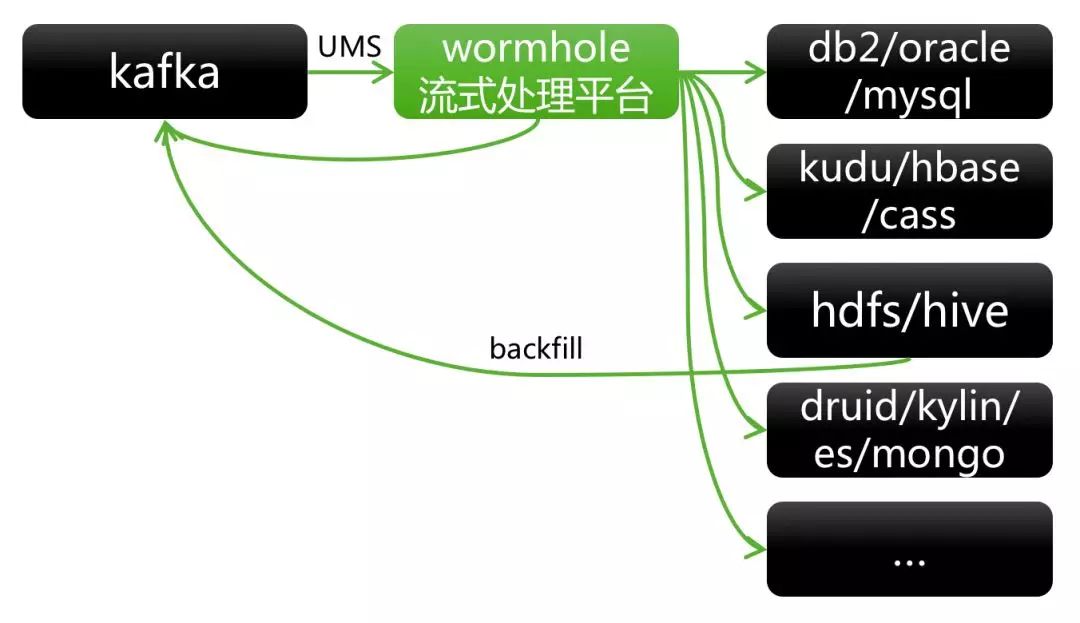
数据总线平台DBus,作为统一数据采集平台,负责对接各种数据源。DBus将数据以增量或全量方式抽取出来,并进行一些常规数据处理,最后将处理后的消息发布在Kafka上。
分布式消息系统Kafka,以分布式、高可用、高吞吐、可发布-订阅等能力,连接消息的生产者和消费者。
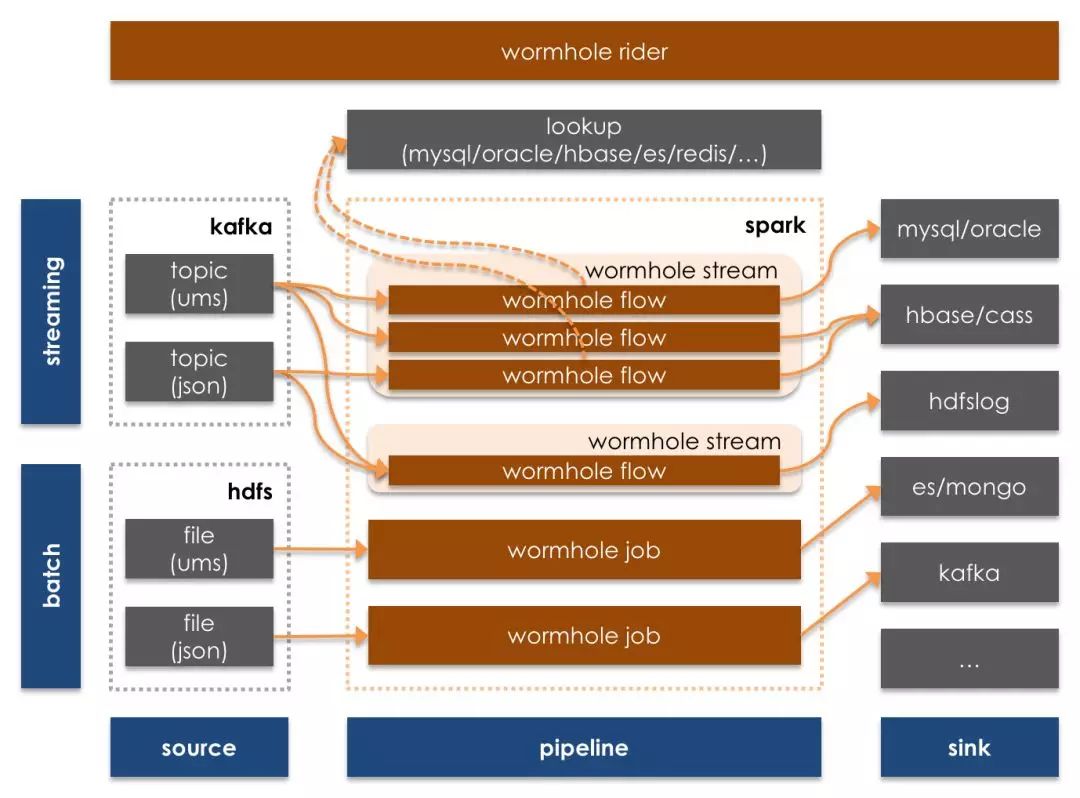
流式处理平台Wormhole,作为统一流式处理平台,负责流上处理和对接各种数据目标存储。Wormhole从Kafka消费消息,支持流上配置SQL方式实现流上数据处理逻辑,并支持配置化方式将数据以最终一致性(幂等)效果落入不同数据目标存储(Sink)中。
在数据计算存储层,RTDP架构选择开放技术组件选型,用户可以根据实际数据特性、计算模式、访问模式、数据量等信息选择合适的存储,解决具体数据项目问题。RTDP还支持同时选择多个不同数据存储,从而更灵活的支持不同项目需求。
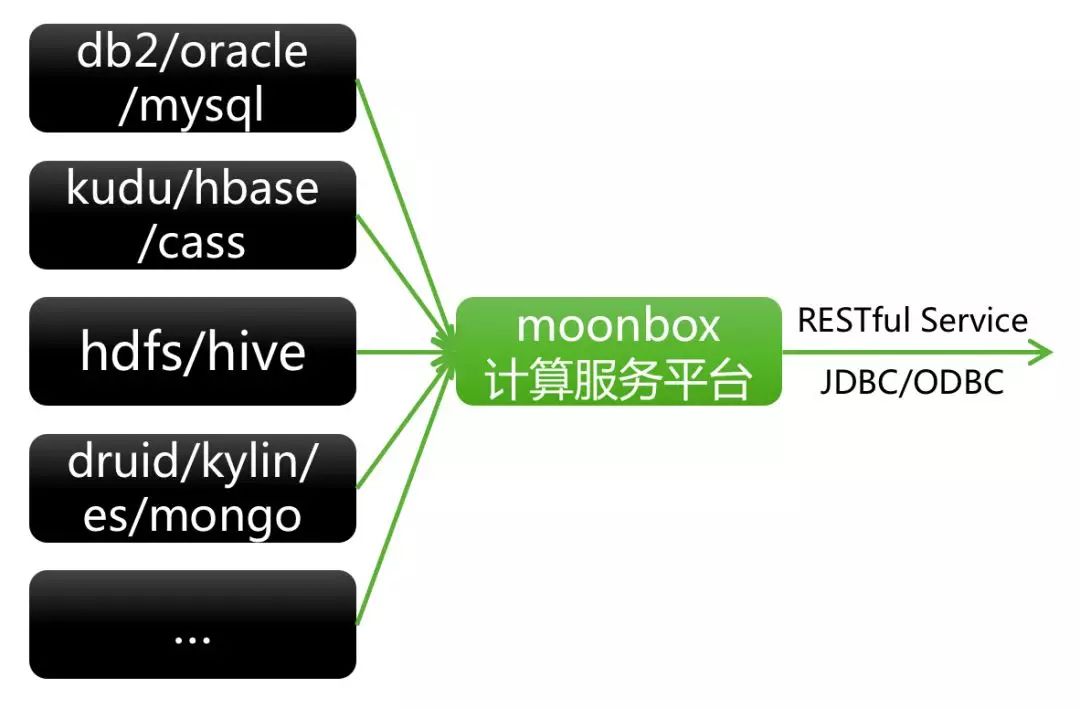
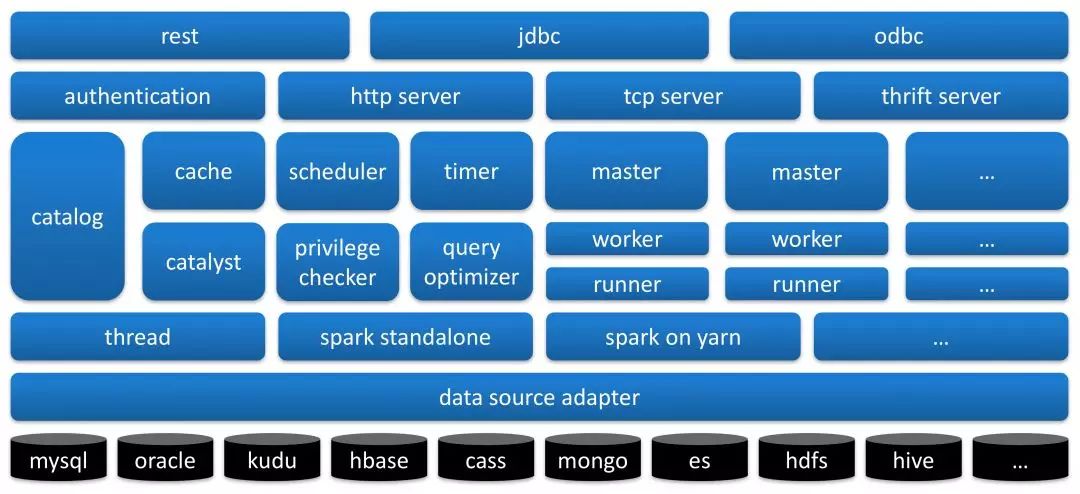
计算服务平台Moonbox,作为统一计算服务平台,对异构数据存储端负责整合、计算下推优化、异构数据存储混算等(数据虚拟化技术),对数据展示和交互端负责收口统一元数据查询、统一数据计算和下发、统一数据查询语言(SQL)、统一数据服务接口等。
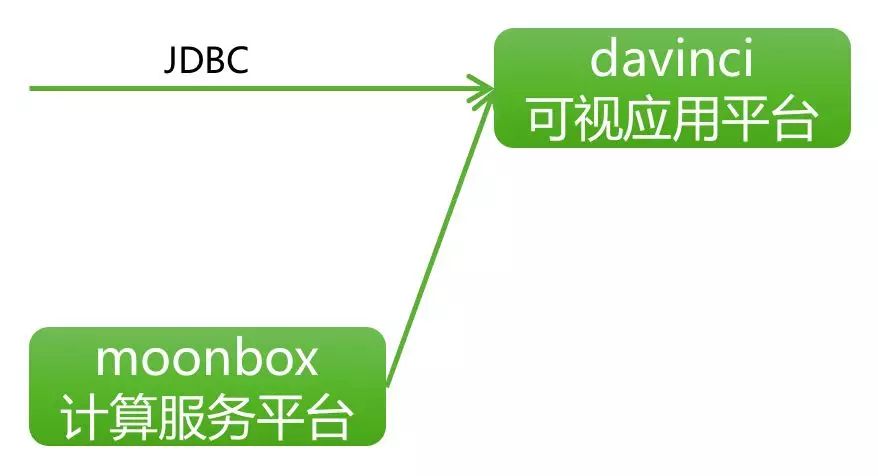
可视应用平台Davinci,作为统一数据可视化平台,以配置化方式支持各种数据可视化和交互需求,并可以整合其他数据应用以提供数据可视化部分需求解决方案,另外还支持不同数据从业人员在平台上协作完成各项日常数据应用。其他数据终端消费系统如数据开发平台Zeppelin、数据算法平台Jupyter等在本文不做介绍。
切面话题如数据管理、数据安全、开发运维、驱动引擎,可以通过对接DBus、Wormhole、Moonbox、Davinci的服务接口进行整合和二次开发,以支持端到端管控和治理需求。
下面我们会进一步细化图2涉及到的技术组件和切面话题,介绍技术组件的功能特性,着重讲解我们技术组件的设计思想,并对切面话题展开讨论。
2技术组件介绍
(1) 数据总线平台DBus
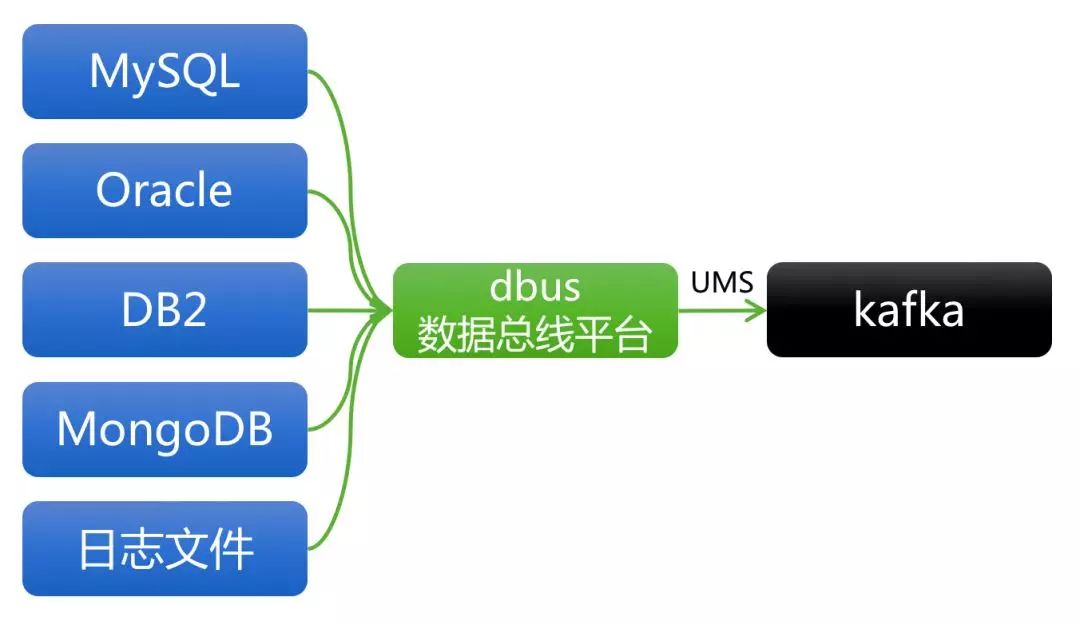
图3 RTDP架构之DBus
DBus设计思想
从外部角度看待设计思想:
负责对接不同的数据源,实时抽取出增量数据,对于数据库会采用操作日志抽取方式,对于日志类型支持与多种Agent对接。
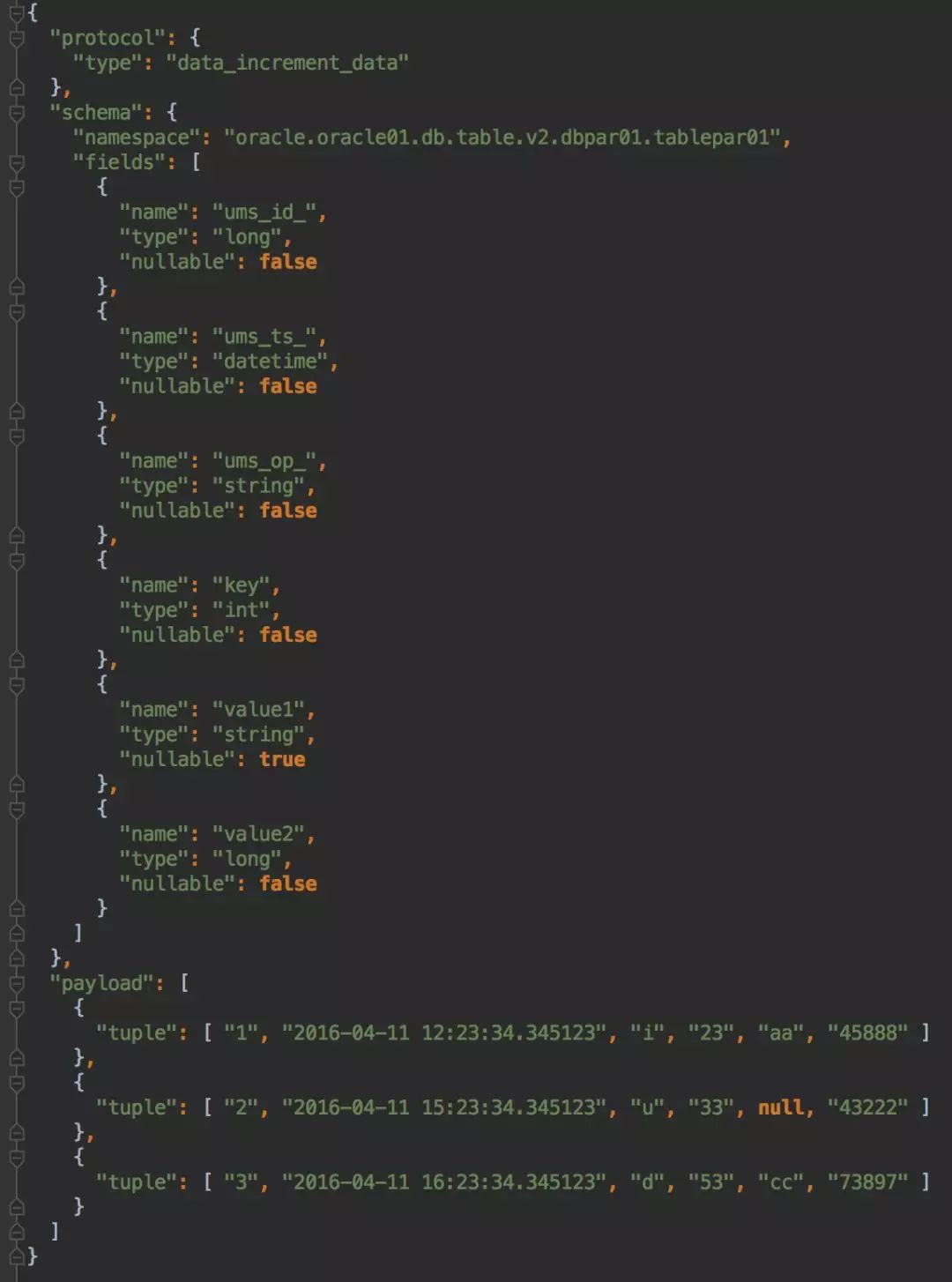
将所有消息以统一的UMS消息格式发布在Kafka上,UMS是一种标准化的自带元数据信息的JSON格式,通过统一UMS实现逻辑消息与物理Kafka Topic解耦,使得同一Topic可以流转多个UMS消息表。
支持数据库的全量数据拉取,并且和增量数据统一融合成UMS消息,对下游消费透明无感知。
从内部角度看待设计思想:
基于Storm计算引擎进行数据格式化,确保消息端到端延迟最低。
对不同数据源数据进行标准化格式化,生成UMS信息,其中包括:
生成每条消息的唯一单调递增id,对应系统字段ums_id_;
确认每条消息的事件时间戳(event timestamp),对应系统字段ums_ts_;
确认每条消息的操作模式(增删改,或insert only),对应系统字段ums_op_;
对数据库表结构变更实时感知并采用版本号进行管理,确保下游消费时明确上游元数据变化。
在投放Kafka时确保消息强有序(非绝对有序)和at least once语义。
通过心跳表机制确保消息端到端探活感知。
DBus功能特性
支持配置化全量数据拉取;
支持配置化增量数据拉取;
支持配置化在线格式化日志;
支持可视化监控预警;
支持配置化多租户安全管控;
支持分表数据汇集成单逻辑表。
DBus技术架构
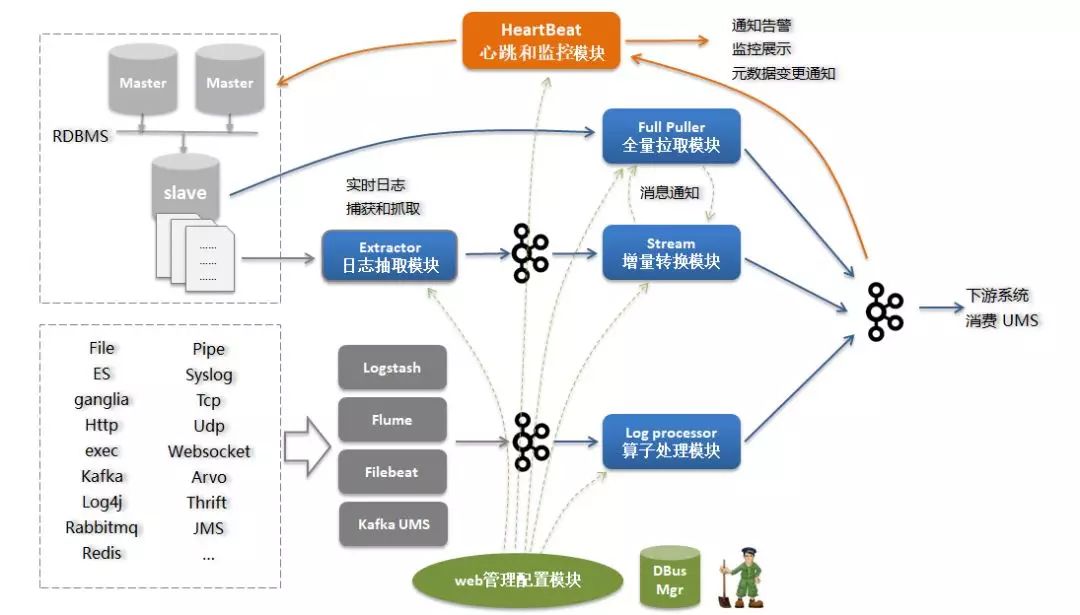
图4 DBus数据流转架构图
更多DBus技术细节和用户界面,可以参看:
#DBus# 数据库表结构变更处理方案
#DBus# 关系型数据库全表扫描分片详解
GitHub用户手册: https://bridata.github.io/DBus/
(2) 分布式消息系统Kafka
Kafka已经成为事实标准的大数据流式处理分布式消息系统,当然Kafka在不断的扩展和完善,现在也具备了一定的存储能力和流式处理能力。关于Kafka本身的功能和技术已经有很多文章信息可以查阅,本文不再详述Kafka的自身能力。
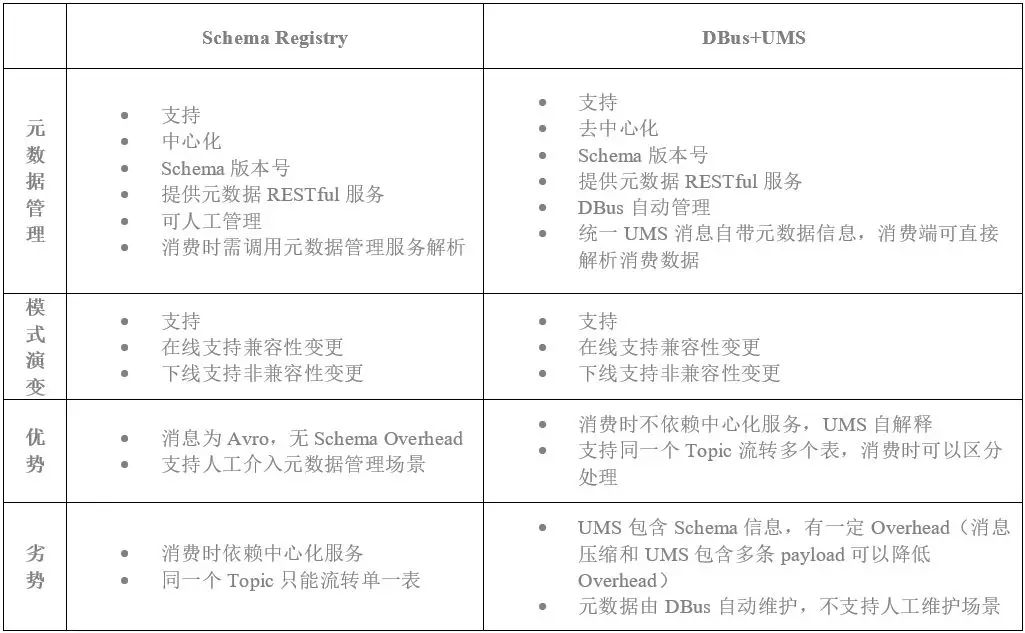
这里我们具体探讨Kafka上消息元数据管理(Metadata Management)和模式演变(Schema Evolution)的话题。
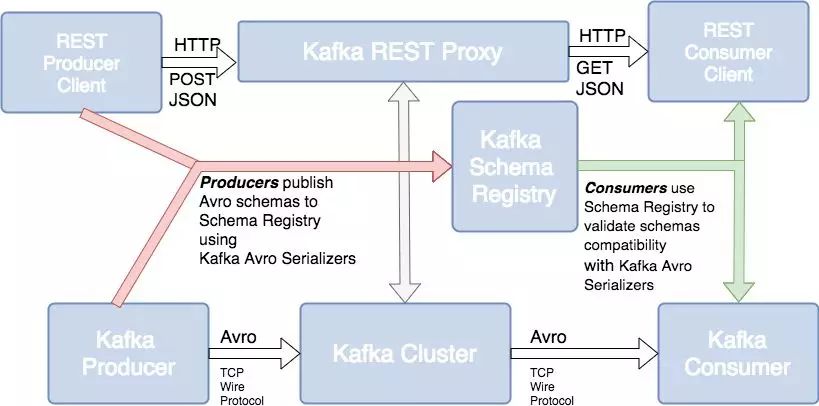
图5 图片来源: http://cloudurable.com/images/kafka-ecosystem-rest-proxy-schema-registry.png
图5显示,在Kafka背后的Confluent公司解决方案中,引入了一个元数据管理组件:Schema Registry。这个组件主要负责管理在Kafka上流转消息的元数据信息和Topic信息,并提供一系列元数据管理服务。
之所以要引入这样一个组件,是为了Kafka的消费方能够了解不同Topic上流转的是哪些数据、以及了解数据的元数据信息,并进行有效的解析消费。任何数据流转链路,不管是在什么系统上流转,都会存在这段数据链路的元数据管理问题,Kafka也不例外。
Schema Registry是一种中心化的Kafka数据链路元数据管理解决方案,并且基于Schema Registry,Confluent提供了相应的Kafka数据安全机制和模式演变机制。更多关于Schema Registry的介绍,可以参看:
Kafka Tutorial:Kafka, Avro Serialization and the Schema Registry http://cloudurable.com/blog/kafka-avro-schema-registry/index.html
那么在RTDP架构中,如何解决Kafka消息元数据管理和模式演变问题呢?
元数据管理(Metadata Management):
DBus会自动将实时感知的数据库元数据变化记录下来并提供服务;
DBus会自动将在线格式化的日志元数据信息记录下来并提供服务;
DBus会发布在Kafka上发布统一UMS消息,UMS本身自带消息元数据信息,因此下游消费时无需调用中心化元数据服务,可以直接从UMS消息里拿到数据的元数据信息。
模式演变(Schema Evolution):
UMS消息会自带Schema的Namespace信息,Namespace是一个7层定位字符串,可以唯一定位任何表的任何生命周期,相当于数据表的IP地址,形式如下:
[Datastore].[Datastore Instance].[Database]..[TableVersion].[Database Partition].[Table Partition]
本文作为下篇,则是从技术角度入手,介绍RTDP的技术选型和相关组件,探讨适用不同应用场景的相关模式。RTDP的敏捷之路就此展开:
一、技术选型介绍
在上篇中,我们给出了RTDP的一个整体架构设计(图1),而本文我们则会推荐整体技术组件选型,对每个技术组件做出简单介绍,尤其对我们抽象并实现的四个技术平台(统一数据采集平台、统一流式处理平台、统一计算服务平台、统一数据可视化平台)着重介绍设计思路;对Pipeline端到端切面话题进行探讨,包括功能整合、数据管理、数据安全等。
(图1)
1整体技术选型
(图2)
首先,我们简要解读一下图2:
数据源、客户端,列举了大多数数据应用项目的常用数据源类型。
数据总线平台DBus,作为统一数据采集平台,负责对接各种数据源。DBus将数据以增量或全量方式抽取出来,并进行一些常规数据处理,最后将处理后的消息发布在Kafka上。
分布式消息系统Kafka,以分布式、高可用、高吞吐、可发布-订阅等能力,连接消息的生产者和消费者。
流式处理平台Wormhole,作为统一流式处理平台,负责流上处理和对接各种数据目标存储。Wormhole从Kafka消费消息,支持流上配置SQL方式实现流上数据处理逻辑,并支持配置化方式将数据以最终一致性(幂等)效果落入不同数据目标存储(Sink)中。
在数据计算存储层,RTDP架构选择开放技术组件选型,用户可以根据实际数据特性、计算模式、访问模式、数据量等信息选择合适的存储,解决具体数据项目问题。RTDP还支持同时选择多个不同数据存储,从而更灵活的支持不同项目需求。
计算服务平台Moonbox,作为统一计算服务平台,对异构数据存储端负责整合、计算下推优化、异构数据存储混算等(数据虚拟化技术),对数据展示和交互端负责收口统一元数据查询、统一数据计算和下发、统一数据查询语言(SQL)、统一数据服务接口等。
可视应用平台Davinci,作为统一数据可视化平台,以配置化方式支持各种数据可视化和交互需求,并可以整合其他数据应用以提供数据可视化部分需求解决方案,另外还支持不同数据从业人员在平台上协作完成各项日常数据应用。其他数据终端消费系统如数据开发平台Zeppelin、数据算法平台Jupyter等在本文不做介绍。
切面话题如数据管理、数据安全、开发运维、驱动引擎,可以通过对接DBus、Wormhole、Moonbox、Davinci的服务接口进行整合和二次开发,以支持端到端管控和治理需求。
下面我们会进一步细化图2涉及到的技术组件和切面话题,介绍技术组件的功能特性,着重讲解我们技术组件的设计思想,并对切面话题展开讨论。
2技术组件介绍
(1) 数据总线平台DBus
图3 RTDP架构之DBus
DBus设计思想
从外部角度看待设计思想:
负责对接不同的数据源,实时抽取出增量数据,对于数据库会采用操作日志抽取方式,对于日志类型支持与多种Agent对接。
将所有消息以统一的UMS消息格式发布在Kafka上,UMS是一种标准化的自带元数据信息的JSON格式,通过统一UMS实现逻辑消息与物理Kafka Topic解耦,使得同一Topic可以流转多个UMS消息表。
支持数据库的全量数据拉取,并且和增量数据统一融合成UMS消息,对下游消费透明无感知。
从内部角度看待设计思想:
基于Storm计算引擎进行数据格式化,确保消息端到端延迟最低。
对不同数据源数据进行标准化格式化,生成UMS信息,其中包括:
生成每条消息的唯一单调递增id,对应系统字段ums_id_;
确认每条消息的事件时间戳(event timestamp),对应系统字段ums_ts_;
确认每条消息的操作模式(增删改,或insert only),对应系统字段ums_op_;
对数据库表结构变更实时感知并采用版本号进行管理,确保下游消费时明确上游元数据变化。
在投放Kafka时确保消息强有序(非绝对有序)和at least once语义。
通过心跳表机制确保消息端到端探活感知。
DBus功能特性
支持配置化全量数据拉取;
支持配置化增量数据拉取;
支持配置化在线格式化日志;
支持可视化监控预警;
支持配置化多租户安全管控;
支持分表数据汇集成单逻辑表。
DBus技术架构
图4 DBus数据流转架构图
更多DBus技术细节和用户界面,可以参看:
#DBus# 数据库表结构变更处理方案
#DBus# 关系型数据库全表扫描分片详解
GitHub用户手册: https://bridata.github.io/DBus/
(2) 分布式消息系统Kafka
Kafka已经成为事实标准的大数据流式处理分布式消息系统,当然Kafka在不断的扩展和完善,现在也具备了一定的存储能力和流式处理能力。关于Kafka本身的功能和技术已经有很多文章信息可以查阅,本文不再详述Kafka的自身能力。
这里我们具体探讨Kafka上消息元数据管理(Metadata Management)和模式演变(Schema Evolution)的话题。
图5 图片来源: http://cloudurable.com/images/kafka-ecosystem-rest-proxy-schema-registry.png
图5显示,在Kafka背后的Confluent公司解决方案中,引入了一个元数据管理组件:Schema Registry。这个组件主要负责管理在Kafka上流转消息的元数据信息和Topic信息,并提供一系列元数据管理服务。
之所以要引入这样一个组件,是为了Kafka的消费方能够了解不同Topic上流转的是哪些数据、以及了解数据的元数据信息,并进行有效的解析消费。任何数据流转链路,不管是在什么系统上流转,都会存在这段数据链路的元数据管理问题,Kafka也不例外。
Schema Registry是一种中心化的Kafka数据链路元数据管理解决方案,并且基于Schema Registry,Confluent提供了相应的Kafka数据安全机制和模式演变机制。更多关于Schema Registry的介绍,可以参看:
Kafka Tutorial:Kafka, Avro Serialization and the Schema Registry http://cloudurable.com/blog/kafka-avro-schema-registry/index.html
那么在RTDP架构中,如何解决Kafka消息元数据管理和模式演变问题呢?
元数据管理(Metadata Management):
DBus会自动将实时感知的数据库元数据变化记录下来并提供服务;
DBus会自动将在线格式化的日志元数据信息记录下来并提供服务;
DBus会发布在Kafka上发布统一UMS消息,UMS本身自带消息元数据信息,因此下游消费时无需调用中心化元数据服务,可以直接从UMS消息里拿到数据的元数据信息。
模式演变(Schema Evolution):
UMS消息会自带Schema的Namespace信息,Namespace是一个7层定位字符串,可以唯一定位任何表的任何生命周期,相当于数据表的IP地址,形式如下:
[Datastore].[Datastore Instance].[Database].