Hadoop体系之MapReduce的工作机制
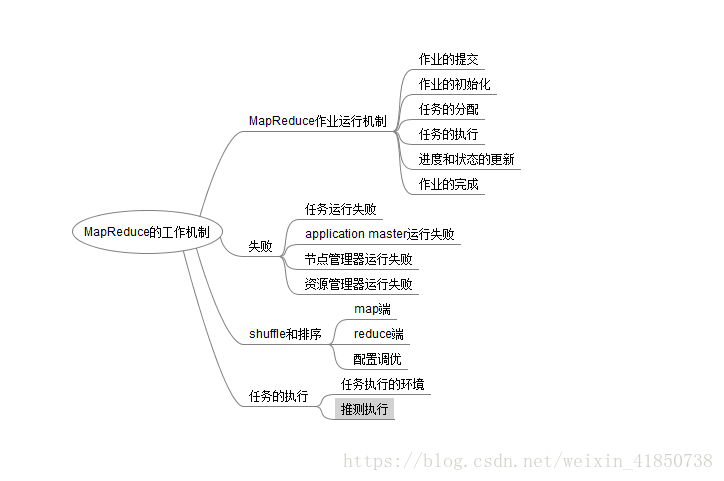
一、思维导图
二、MapReduce作业的工作原理
2.1 作业的提交
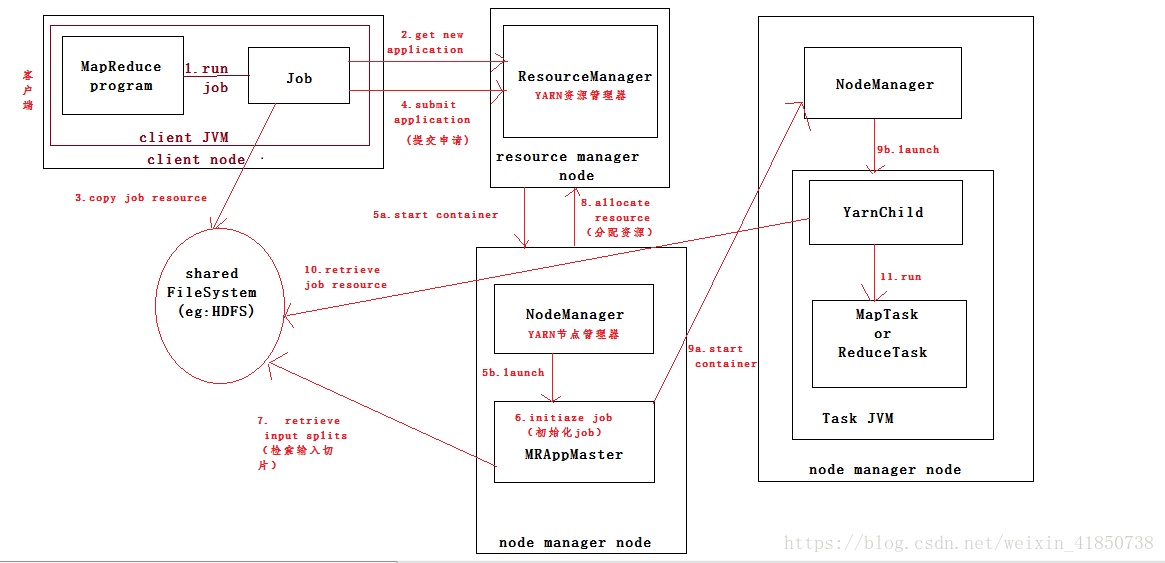
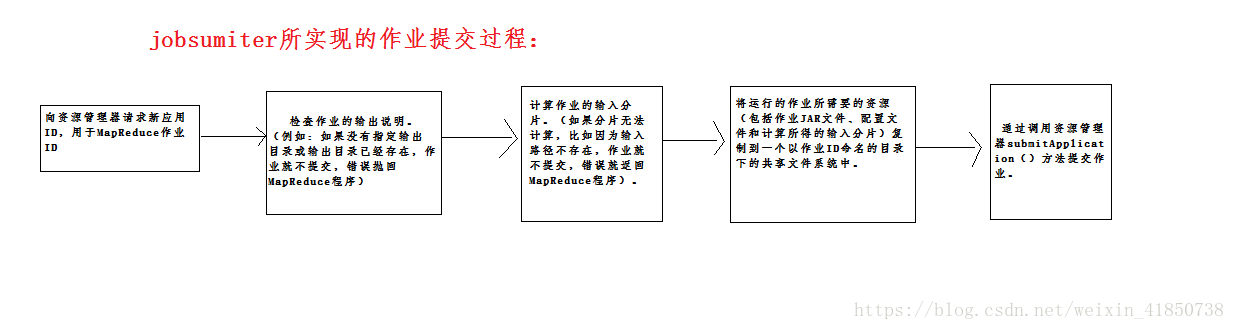
在步骤1中,Job中的submit()方法创建一个内部的JobSummiter的实例,并且调用其submitJobInternal()方法。作业提交之后,waitForCompletion()每秒轮询作业的进度,如果发现自上次报告后有改变,便把进度报告到控制台。作业完成后,如果成功,就显示作业计数器。如果失败,导致作业失败的错误被记录到控制台。
2.2 作业的初始化
资源管理器收到调用它的submitApplication()消息后,便将请求传递给YARN调度器。调度器分配一个容器,然后资源管理器在节点管理器的管理下,在容器中启动application master 的进程(步骤5a和5b)。
MapReduce作业的application master是一个java应用程序,它的主类是MRAppMaster。由于将接受来自任务的进度和完成报告(步骤6),因此application master对作业的初始化是通过创建多个簿记对象以保持对作业进度的跟踪来完成。紧接着,MRAppMaster接受来自共享文件系统的,在客户端计算的输入分片。然后对y每一个分片创建一个map任务对象以及由mapreduce.job.reduces属性(通过作业的setNumReduceTasks()方法设置)确定多个reduce任务。任务ID在此时分配。
application master必须确定如何运行构成MapReduce作业的各个任务。如果作业很小,就选择和自己同当一个JVM上运行任务。当application master判断在新的容器中分配和运行任大于并行运行他们的开销时,application master将作业运行在与自身同一个JVM任务中。这样的作业称为uber。
2.3 任务的分配
如果作业不适合作为ube任务运行,那么application master就会为该作业中的所有map任务和reduce任务向资源管理器请求容器(步骤8)。首先Map任务发出请求,该请求的优先级要高于reduce任务的请求。这是因为所有的map任务必须在ruduce的排序阶段能够启动前完成。直到有5%的map任务已经完成时,为reduce任务的请求才会发出。
reduce任务能够在集群中任意位置运行,但是map任务的请求有着数据本地化的局限。
2.4 任务的执行
一旦资源管理器的调度器为任务分配了一资源本地化个特定节点上的容器,application master就和节点管理器通信来启动容器(步骤9a和9b)。该任务由主类为YarnChild的的一个java应用程序执行。执行之前将任务所需要的资源本地化。包括作业的配置,jar文件和所有来自分布式缓存的文件。最后运行map任务和reduce任务。
YarnChild在指定的jvm中运行,因此用户定义的map和reduce任何函数中的任何缺陷都不会影响到节点管理器。
每个任务都能够执行搭建(setup)和提交(commit)动作,他们和任务的本身在同一个JVM中运行,并由作业outputCommitter确定。
Streaming :streaming运行特殊的map任务和reduce任务,目的是运行用户提供的可执行程序,并与之提供通信。如下图所示:
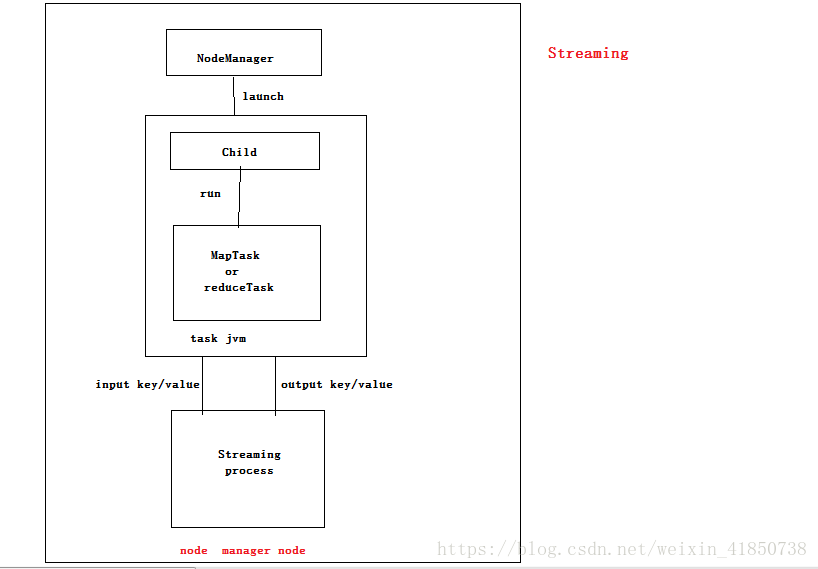
Streaming任务使用标准输入和输出流与进程进行通信,在任务执行过程中,java进程把输入键/值对传给外部进程,外部进程通过用户定义的map和reduce函数来执行它并把 输出键/值对传回java进程。
2.5 进度和状态的更新
作业状态信息在作业期间不断更新化,它是如何与客户端进行通信的呢?
任务在运行时,对其进度保持追踪。对map任务,任务是已处理输入所占的比例。对reduce任务,系统估计已处理reduce输入的比例,整个过程分为三个部分,与shuffle的三个阶段相对应。例如:如果任务已经执行了reduce一半的输入,那么任务进度便是5/6,这是因为已经完成复制和排序ji阶段(每个占1/3),并且已经完成reduce阶段的一半。
2.6 作业的完成
当application master收到作业最后一个任务已完成的通知后,便把作业的状态设置为“成功”。作业完成时,application master和任务容器清理其工作状态(中间输出将被删除。)。作业信息由作业历史服务器存档。
3. 失败
|
错误 类型 |
原因分析 |
备注 |
|
任务运行失败 |
|
Application master被告知一个任务尝试失败之后,将重新调度该任务执行。Application master会试图避免在以前失败过的节点管理器上重新调度该任务。一个任务重新尝试次数最多为4。 |
|
Application master运行失败 |
|
MapReduce application master失败尝试次数为2,Yarn application master失败尝试次数也为2. |
|
节点管理器运行失败 |
如果节点管理器由于崩溃或运行缓慢,就会停止向资源管理器发送心跳信息,如果十分钟之内,没有收到心跳信息,资源管理器将会通知停止发送心跳信息的节点管理器,并且将从自己的节点池中移除以调度启用容器。 |
如果应用程序的运行失败次数过高,那么节点管理器可能会被application master 管理的黑名单拉黑。 |
|
资源管理器运行失败 |
|
双机热备机制,减少资源管理器故障带来的损失、 |
四、shuffle 和 排序
1. MapReduce确保每个reduce的输入都是按键排序的,系统执行排序,将map输出作为输入传递给reducer的过程称为shuffle。
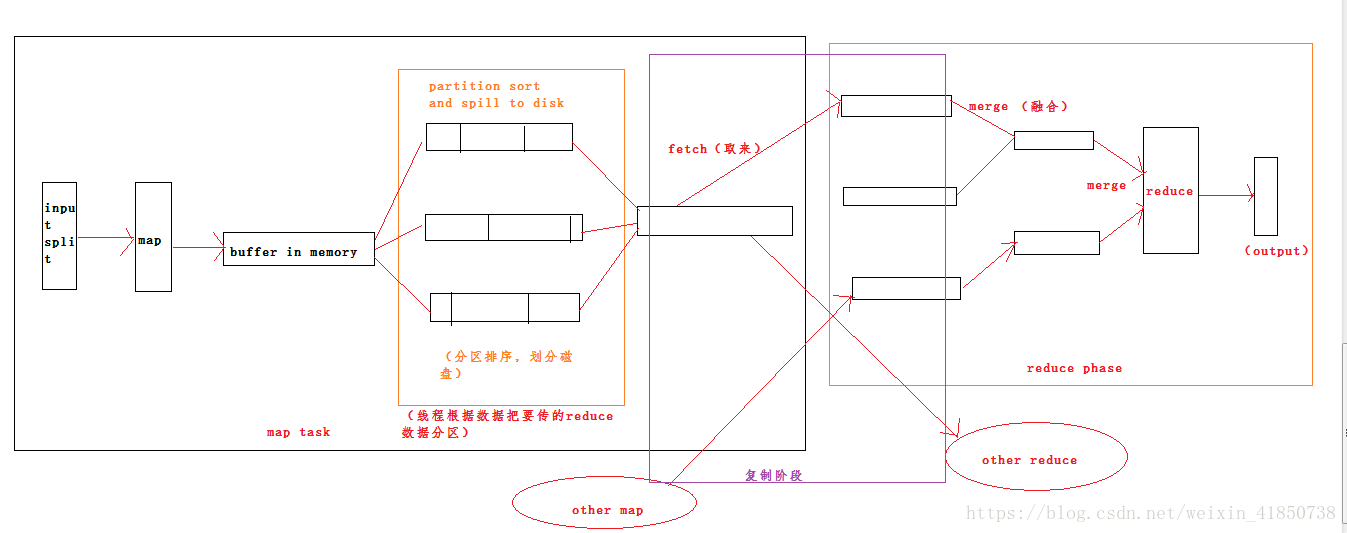
2.reducer如何知道要从哪台机器取得map输出?
map任务完成后,他们会使用心跳机制通知他们的application master 。因此对于指定作业,application master知道map输出和主机位置之间的映射关系,reducer中的一个线程定期询问master以便获取map输出主机的位置。
阅读更多

- 知识学习——Hadoop MapReduce工作机制
- hadoop,MapReduce的工作机制
- Hadoop学习笔记一:MapReduce的工作机制
- hadoop MapReduce 工作机制
- hadoop一些基本知识——Mapreduce 整个工作机制图
- [hadoop读书笔记] 第五章 MapReduce工作机制
- hadoop 自学指南五之MapReduce工作机制
- Hadoop学习笔记(5) MapReduce工作机制
- Hadoop学习笔记(一):MapReduce工作机制
- Hadoop基础教程-第7章 MapReduce进阶(7.2 MapReduce工作机制)(草稿)
- Hadoop入门第三篇-MapReduce试手以及MR工作机制
- hadoop之fsimage和edits工作机制和元数据namenode宕机恢复
- Hadoop读写文件时内部工作机制
- Hadoop体系结构之 Mapreduce
- MapReduce工作机制总结
- Hadoop系列-MapReduce设计思想与原理机制(九)
- Hadoop系列-MapReduce自定义数据类型(序列化、反序列化机制)(十二)
- Hadoop:MapReduce编程接口体系结构
- MapReduce及其工作机制 (Book Review & Personal Conclusion)
- _00003 Hadoop MapReduce体系结构