Python实现网络爬虫基础学习(三)
2018-07-25 18:41
447 查看
获取新闻评论数
发现获取到的评论数为空
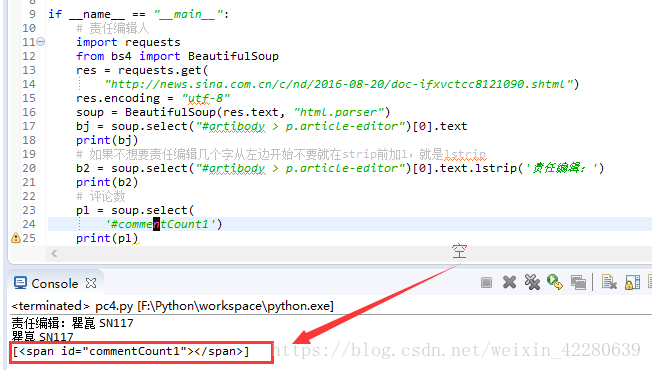
猜想数据可能是采用JavaScript的方式存放的,会不会并没有放在document下,那么试着找一下js里面,接下来需要大海捞针了,筛选一下其他的链接,找出可能放有评论数的工具
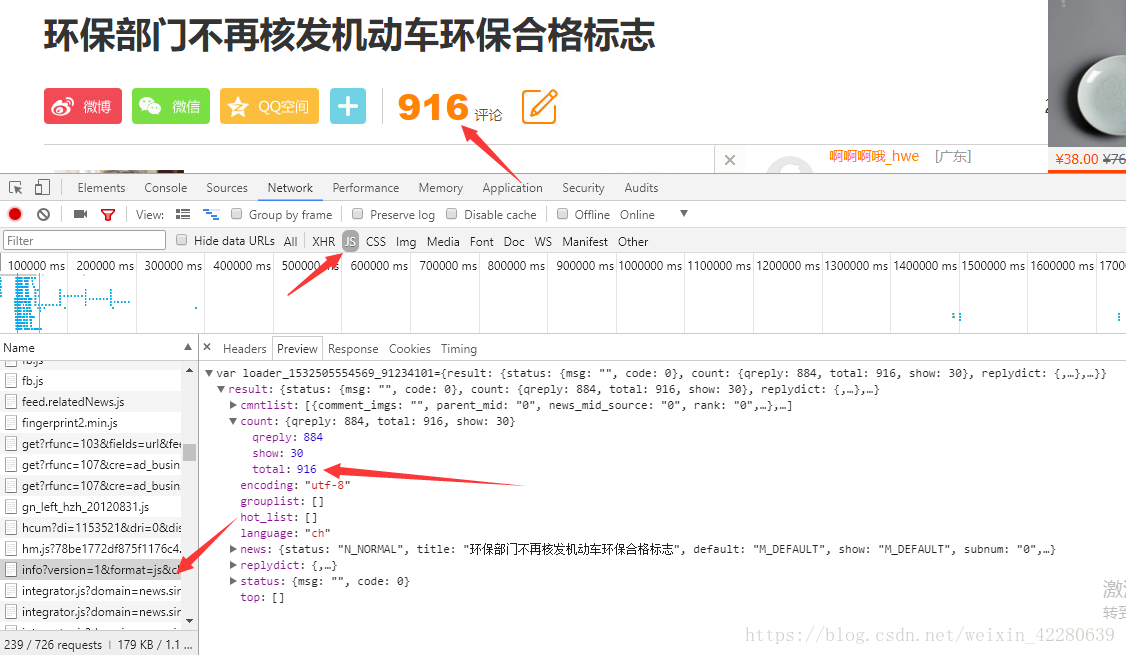
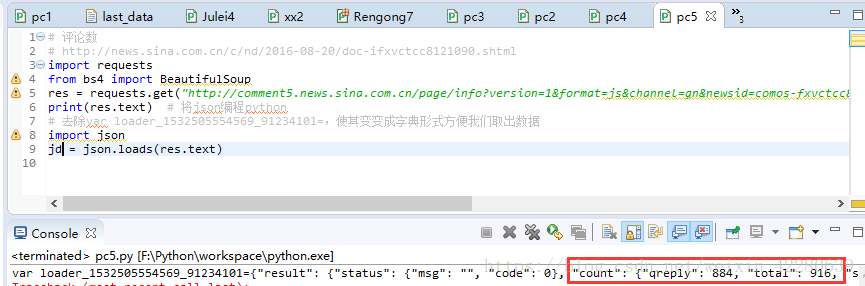
还可以发现这里的评论也全部存放在这里
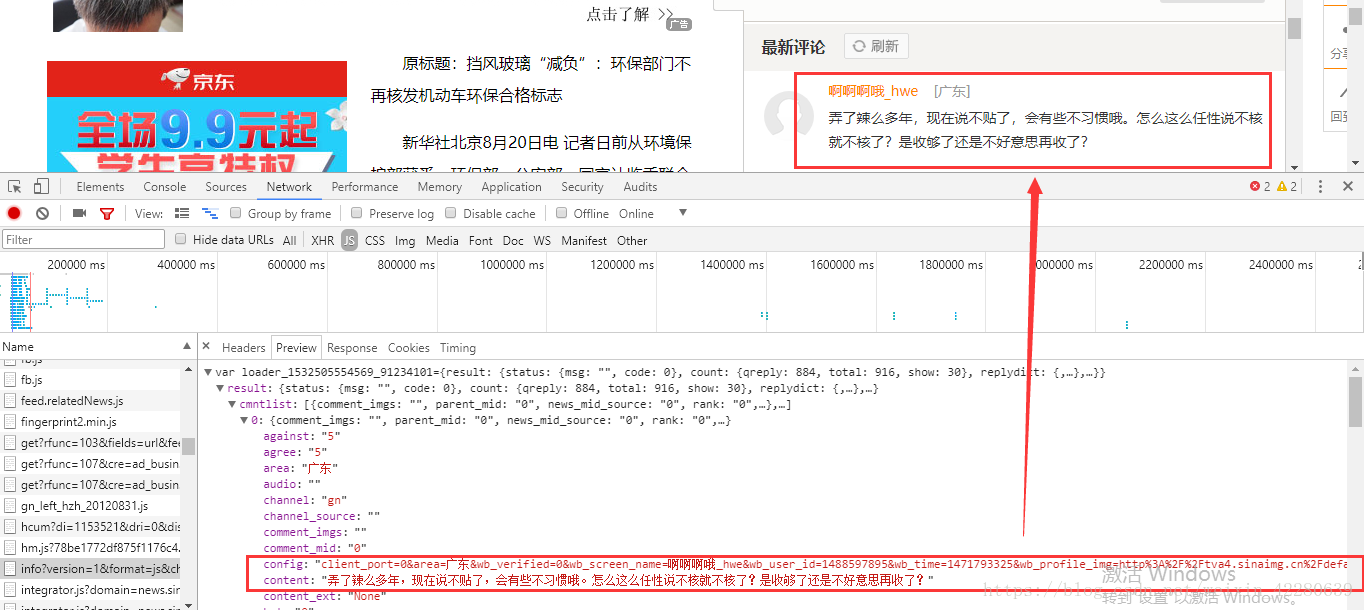
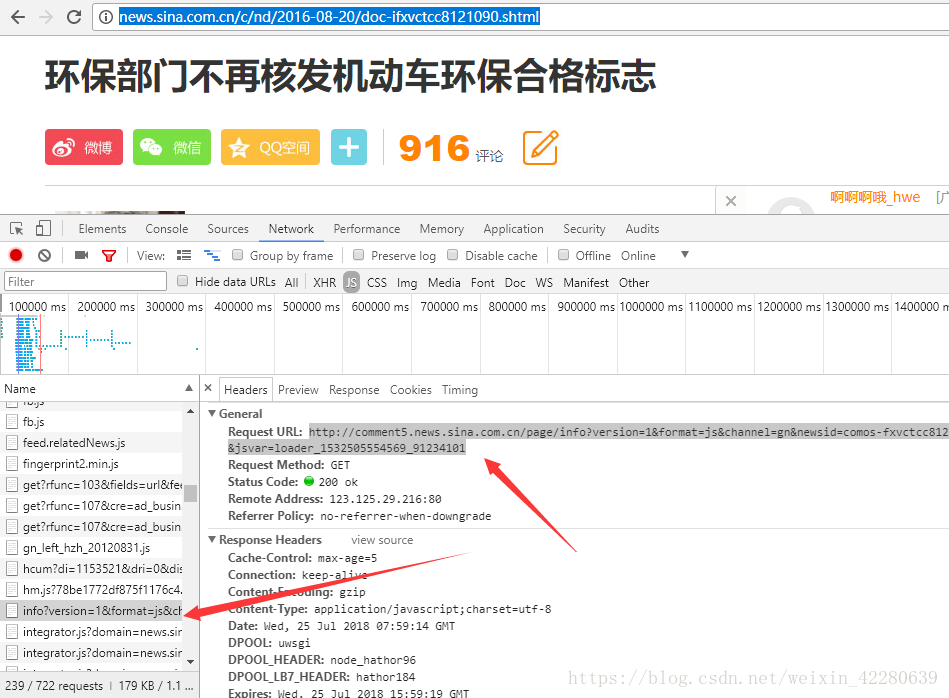
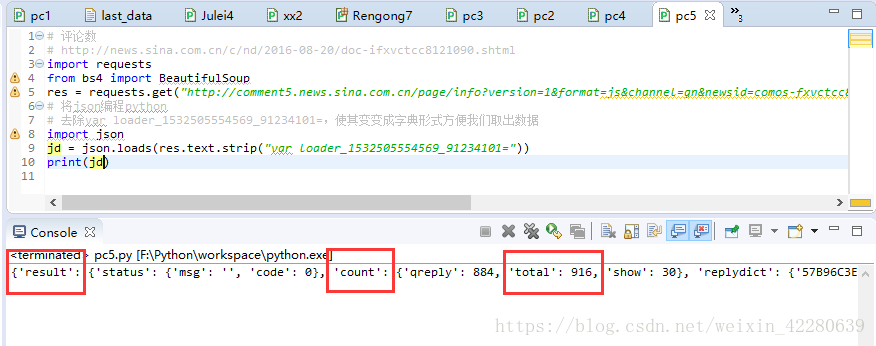
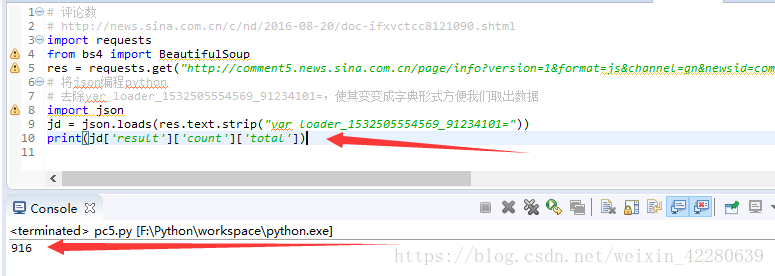
那么我们就可以进行操作,就可以发现确实有916数字
[code]# 评论数
# http://news.sina.com.cn/c/nd/2016-08-20/doc-ifxvctcc8121090.shtml
import requests
from bs4 import BeautifulSoup
res = requests.get("http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fxvctcc8121090&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20&jsvar=loader_1532505554569_91234101")
# 将json编程python
# 去除var loader_1532505554569_91234101=,使其变变成字典形式方便我们取出数据
import json
jd = json.loads(res.text.strip("var loader_1532505554569_91234101="))
print(jd['result']['count']['total'])
那么再尝试一下最新的新闻下方的评论数:
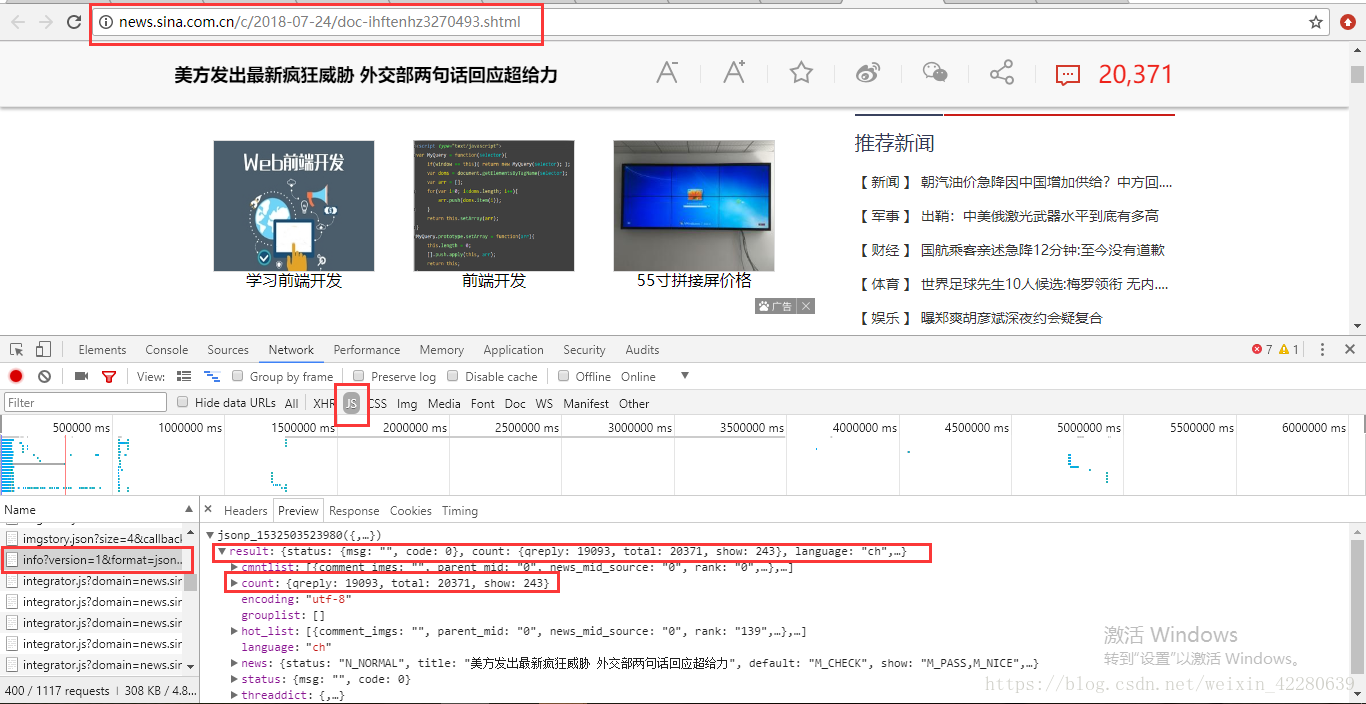
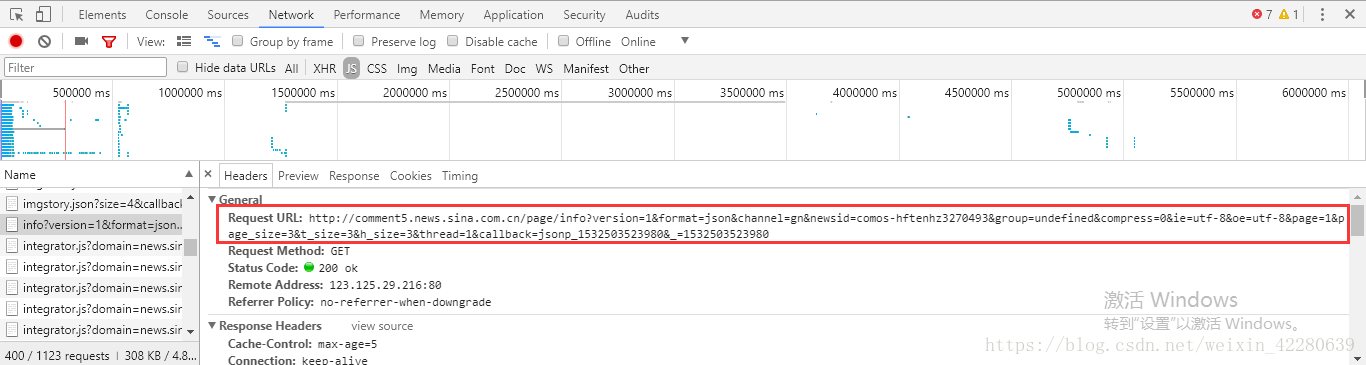
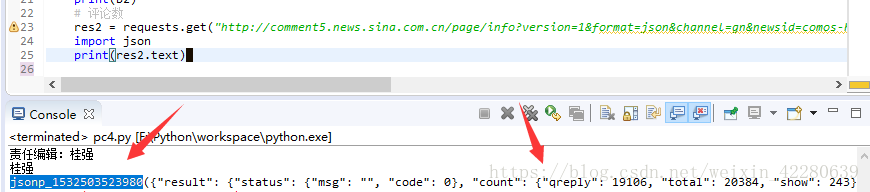
可以发现此时得到的数据是一个元组,这样就无法用json筛选出数据,使用的时候一直报错,我尝试了很多方法,包括将元组转换为list,还想过去除掉tuple,但是由于也没有查找到方法,最后发现所学习的教程上面将URL的最后一部分删除,但是出来的数据完全没有变化,只是现在的数据已经不是tuple类型了,而只是一个简单的字典。这样就可以继续用刚才的方法进行操作了 ,至于还有没有其他方法,就需要去多尝试了。
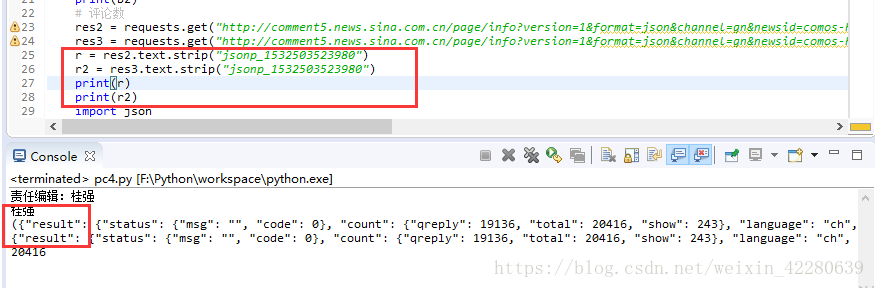
每次刷新只要网站上的评论数发生变化,那么我么所获取到的评论数也会更改

[code]#!F:\workspace python3
# -*- coding:utf-8 -*-
u'''
Created on 2018年7月24日
@author: chen
'''
if __name__ == "__main__":
# 责任编辑人
import requests
from bs4 import BeautifulSoup
res = requests.get(
"http://news.sina.com.cn/c/2018-07-24/doc-ihftenhz3270493.shtml")
res.encoding = "utf-8"
soup = BeautifulSoup(res.text, "html.parser")
bj = soup.select(".show_author")[0].text
print(bj)
# 如果不想要责任编辑几个字从左边开始不要就在strip前加l,就是lstrip
b2 = soup.select(".show_author")[0].text.lstrip('责任编辑:')
print(b2)
# 评论数
res2 = requests.get("http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gn&newsid=comos-hftenhz3270493&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1&callback=jsonp_1532503523980&_=1532503523980")
res3 = requests.get("http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gn&newsid=comos-hftenhz3270493&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1")
r = res2.text.strip("jsonp_1532503523980")
r2 = res3.text.strip("jsonp_1532503523980")
print(r)
print(r2)
import json
j = json.loads(r2)
print(j['result']['count']['total'])
剖析新闻标识符
取得了评论数后,看看如何取得新闻的id,新闻的id来自于网页链接

那么如何获取,接下来我们可以进行操作,指定一个新闻的链接http://news.sina.com.cn/c/2018-07-24/doc-ihftenhz3270493.shtml
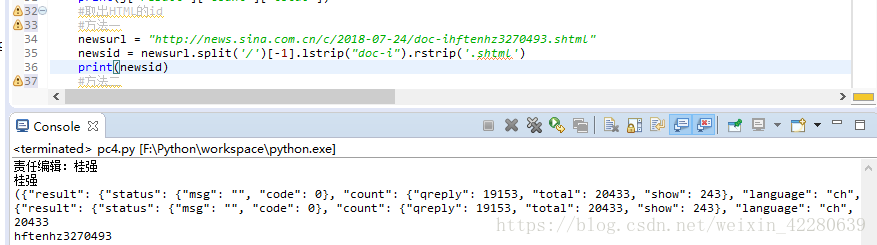
方法一:我们可以透过斜线/ 进行一个分割,取得最后一层[-1],再将doc-去掉,以及右侧的.shtml去掉。就可以获取到新闻的id
方法二: 采用正规表达式,可以使用re这个套件,透过re.search可以直接把包含这个连接页面的位置找寻出来
[code]# 取出HTML的id
# 方法一
newsurl = "http://news.sina.com.cn/c/2018-07-24/doc-ihftenhz3270493.shtml"
newsid = newsurl.split('/')[-1].lstrip("doc-i").rstrip('.shtml')
print(newsid)
# 方法二
import re
m = re.search("doc-i(.+).shtml", newsurl)
newsid2 = m.group(1) # 如果是0,就取得所有里面的所有东西,1就只取得doc-i(.+).shtml括号里的东西
print(newsid2)
阅读更多

相关文章推荐
- Python实现网络爬虫基础学习(四)
- 【Python开发】【神经网络与深度学习】网络爬虫之python实现
- python实现网络爬虫学习总结
- Android基础学习总结(十三)——利用jsoup解析html实现网络爬虫
- Python 基础学习 网络小爬虫
- [Python人工智能] 三.theano实现分类神经网络及机器学习基础
- 【python学习】网络爬虫——基础案例教程
- 【python学习笔记】7:用python实现爬虫-基础
- Python网络爬虫基础知识学习
- Python实现网络爬虫
- python实现网络爬虫
- 【Python开发】【神经网络与深度学习】网络爬虫之图片自动下载器
- 【爬了个爬——学习Python网络爬虫】0.写在前面的话
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
- 用Python实现网络爬虫
- python3实现网络爬虫(5)--模拟浏览器抓取网页
- [Python] 实现网络爬虫
- [Python]网络爬虫学习笔记,爬取豆瓣妹子上妹子的照片
- [Python] 网络爬虫和正则表达式学习总结
- python学习系列之python装饰器基础(4)---装饰器实现token验证功能