python爬虫学习day2-2.遇到js时发生的问题
2018-07-16 15:57
573 查看
学习视频链接:点击打开链接
笔记部分:
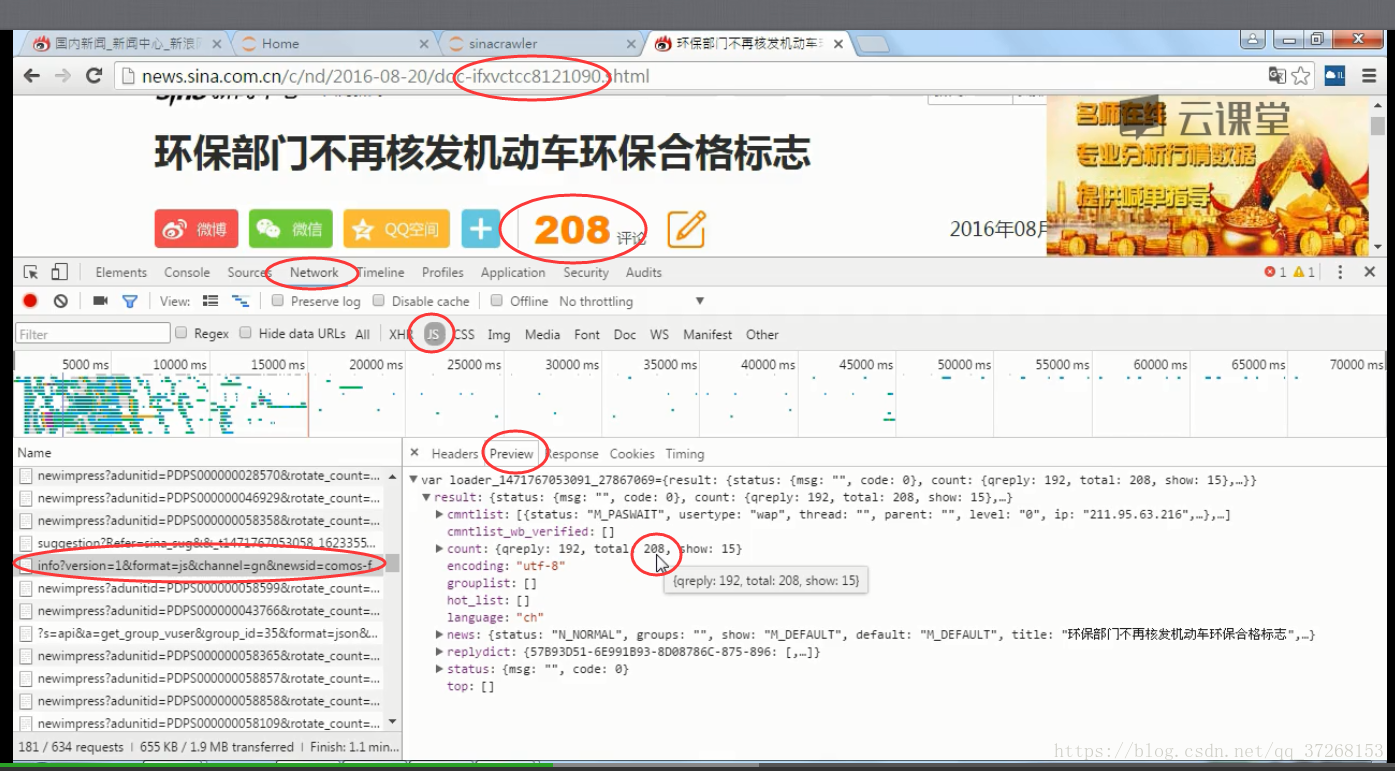
爬到评论数却无法获取到评论数量时,提出猜测是经过js增添上去,所以需要在页面中检查找出提供js的network js链接地址
(即提供js的公网http://链接)
取参考:
然后代码取出相关内容:
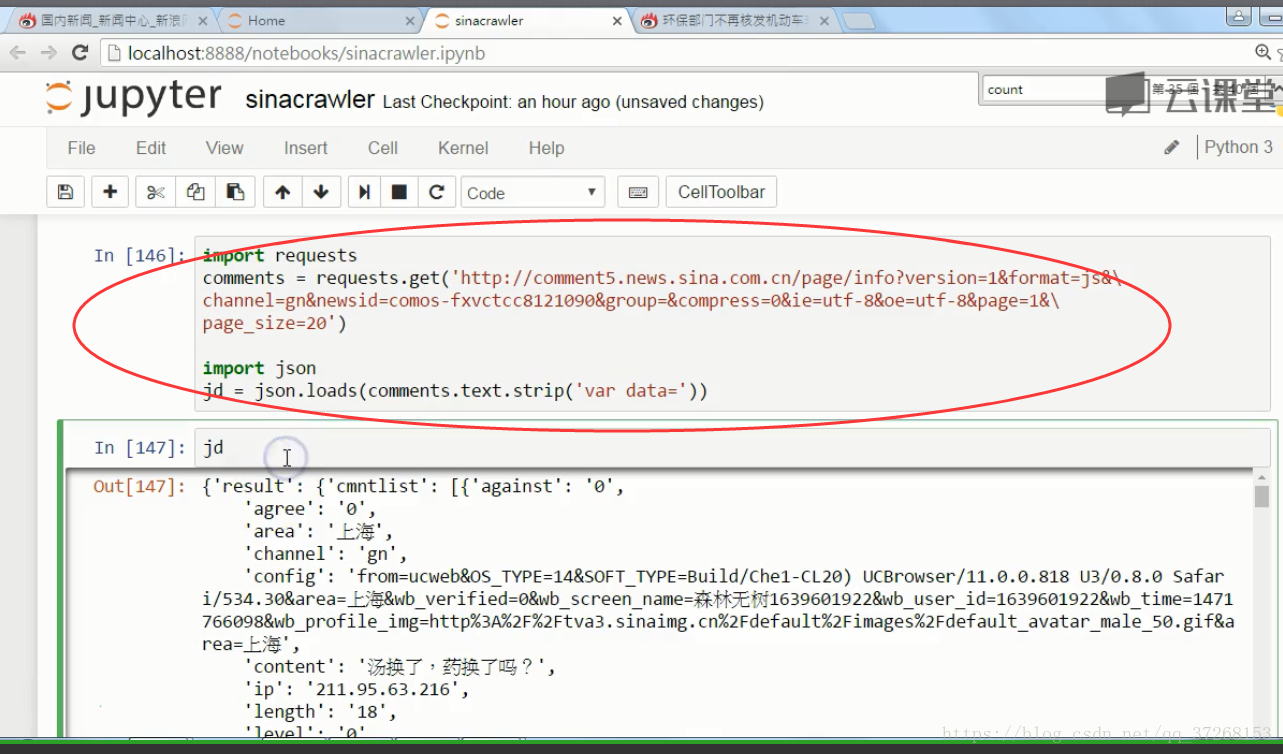
-------------------分割线---------------------------------
取出链接中指定位置的值
#取出链接中指定位置的值newsurl = 'http://comment5.news.sina.com.cn/comment/skin/cos-ai9885256.shtml'newsid = newsurl.split('/')[-1].rstrip('.shtml').lstrip('cos-ai')print(newsid)运行结果为:9885256
理解:
newsid = newsurl
取出链接中指定位置的值之二:(使用正规表达法)


总结:



相关文章推荐
- Python学习笔记:学习爬虫时遇到的问题TypeError: cannot use a string pattern on a bytes-like object 与解决办法
- 【极客学院】-python学习笔记-3-单线程爬虫 (request安装遇到问题及解决,应用requests提取信息)
- Python学习爬虫中遇到点问题
- Python爬虫学习中遇到的问题
- python爬虫学习day2-3 遇到页面有分页,如何爬取数据
- Python学习爬虫时遇到的问题TypeError: cannot use a string pattern on a bytes-like object
- 最近用htmlunit做网络爬虫 遇到拿不到初始化js加载的数据的问题 最近解决了 写个简单的例子
- python 爬虫遇到的网页乱码问题
- python学习中遇到的问题整理
- Python学习中遇到的问题(更新中...)
- OpenCV-Python Tutorials 学习中遇到的问题
- 学习python中map函数遇到的小问题
- python学习中遇到的问题及解决方法
- python学习中,list/tuple/dict格式化遇到的问题
- python爬虫实战(关于工作中遇到的问题)
- 深度学习python库安装经验,Windows下安装Anaconda3 pycharm tensorflow keras theano中遇到的问题
- Python写小爬虫时遇到的问题记录
- python学习总结----遇到的常见问题
- Python Tkinter学习和遇到的问题(二)
- python学习中遇到的问题