数组/矩阵/广义表
2018-07-14 09:35
211 查看
1 数组
二维数组的行优先与列优先对于一个矩阵,在内存中有两种存储顺序: 对于下面的矩阵:

可以有两种存储方式:左为列优先,右为行优先。
Column-major order e.g., Fortran
| Row-major order e.g., C
|
举个栗子:
设二维数组A[6][10],每个数组元素占4个存储单元,若按行优先顺序存放的数组元素A[3][5]的存储地址为1000,求A[0][0]的存储地址?
答案:860
2 矩阵
稀疏矩阵稀疏矩阵的定义:
对于那些零元素远远多于非零元素数目,并且非零元素的分布没有规律的矩阵称为稀疏矩阵(sparse)。
稀疏矩阵的压缩存储
由于稀疏矩阵中非零元素较少,零元素较多,因此可以采用只存储非零元素的方法进行压缩存储。
(1)稀疏矩阵的顺序存储及相关操作
常用的稀疏矩阵顺序存储方法有三元组表示法和伪地址表示法。
①三元组表示法
三元组数据结构为一个长度为n,表内每个元素都有3个分量的线性表,其3个分量分别为值、行下标和列下标。元素结构体表示如下:

为了简便起见可以不使用上述结构体定义的方法来定义三元组,直接申请一个如下的数组即可:

举个栗子:
给定一个稀疏矩阵A(float型),其尺寸为mxn,建立其对应的三元组存储,并通过三元组打印矩阵A。

算法分析:建立一个三元组的核心问题在于求原矩阵的非零元素个数、非零元素的值以及在原数组中的位置,本题算法比较简单,扫描矩阵A即可得到相关数据,进而建立三元组,名为B,最后进行打印,代码如下:

建立后的三元组如下:


② 伪地址表示法
伪地址即元素在矩阵中按照行优先或者列优先存储的相对位置。用伪地址方法存储稀疏矩阵和三元组方法相似,只是三元组每一行中有两个存储单元存放位置,而伪地址只需要一个,对于一个mxn的稀疏矩阵A,元素A[i][j]的伪地址计算方法为n(i-1)+j。根据这个公式,不仅可以计算矩阵中一个给定元素的伪地址,还可以反推出给定元素在原矩阵中的真实地址。
(2)稀疏矩阵的链式存储及相关操作
在稀疏矩阵的链式存储方法中,最常用的有两种:邻接表表示法和十字链表表示法。
①邻接表表示法
邻接表表示法将矩阵中每一行的非零元素连成一个链表,链表结点中有两个分量,分别表示该结点对应的元素值及其列号。
对于上面的矩阵A,用邻接表表示如下:

②十字链表表示法
在稀疏矩阵的十字链表存储结构中,矩阵的每一行用一个带头结点的链表表示,每一列也用一个带头结点的链表表示,这种存储结构中的链表结点都有五个分量:行分量、列分量、数据域分量、指向下方结点的指针,指向右方结点的指针,
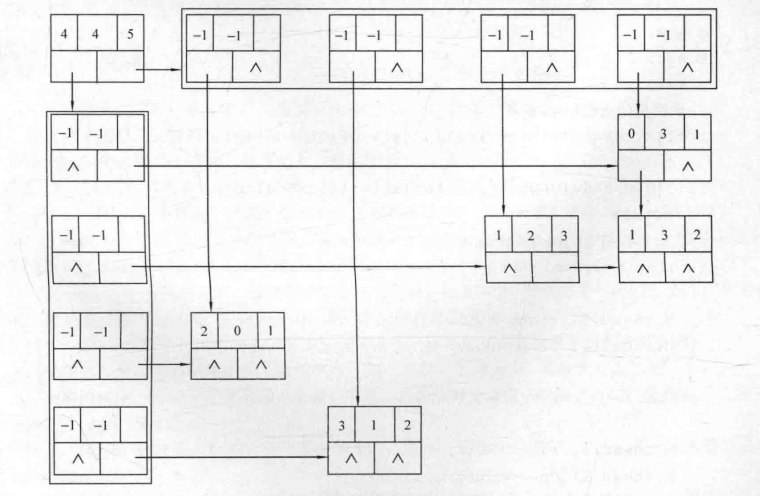
十字链表是由一些单链表纵横交织而成的,其中最左边和最上边是头结点数组,不存储数据信息,左上角的结点可以视为整个十字链表的头结点,它有五个分量,分别存储矩阵的行数,列数、非零元素个数以及指向两个头结点数组的指针。十字链表结点中除头结点以外的结点就是存储矩阵非零元素相关信息的普通结点。
十字链表的两种结点的结构定义如下:


3 广义表
一句话概括广义表:表元素可以是原子或者广义表的一种线性表的拓展结构。
广义表的存储结构:
由于广义表的元素类型不一定相同,因此难以用顺序存储结构存储表中元素,通常采用链接存储方式来存储广义表元素,并称之为广义链表。
采用链式存储结构,每个数据元素可用一个节点表示:
(1)表结点,用以表示子表
(2)元素结点,用以表示单元素
为区别表结点和元素结点,可用一个标志位tag来区分,节点的结构可以设计成如下形式

当tag=0元素结点由标志域,值域构成,当tag=1时,表结点由标志域,头指针域和尾指针域三部分组成。头指针域指向原子或者广义表结点,尾指针域为空或者指向本层中的下一个广义表结点。
typedef struct GenealNode{
int tag;
union{
Datatype data;
struct{
struct GenenealNode *hp,*tp;
}ptr;
};
}*Glist;下图展示了1)到5)中广义表的头尾链表存储结构的存储情况。

此外还有一种拓展线性表存储结构。其中也有两种结点,即原子结点和广义表结点,不同的是原子结点有是三个域:标记域、数据域和尾指针域;广义表结点也有3个域:标记域、头指针域与尾指针域。其中,标记域用于区分当前节点是原子(用0表示),还是广义表(用1表示)。这种存储结构类似于带头结点的单链表存储结构(而上一种类似于不带头结点的单链表存储结构),每一个子表都有一个不带存储信息的头结点来标记其存在,如表A。

广义表的基本操作
取广义表的表头GetHead()和取广义表的表尾GetTail()
任何一个非空广义表的表头是第一个元素,它可能是原子,也可能是广义表,而其表尾必定是广义表。
例如上面的例子中
GetHead(C)=b GetTail(C)=((c,d))
GetHead(D)=B GetTail(D)=(C)
取表头算法为
GList GetHead(GList p)
{//表空时返回NULL,否则返回头指针
if(!p||p->tag==0)//空表或单个元素,函数无意义
{
printf("空表或单个元素");
return NULL;
}
else
{
return p->ptr.hp;
}
}取表尾算法为
GList GetTail(GList p)
{//表空时返回NULL,否则返回头指针
if(!p||p->tag==0)//空表或单个元素,函数无意义
{
printf("空表或单个元素");
return NULL;
}
else
{
return p->ptr.tp;
}
}求广义表的深度
设非空广义表为Ls=(a1,a2,a3...an),其中ai(i=1,2,3...)是原子或者Ls的子表。求Ls的深度可以用递归算法来处理。
具体过程:把原问题转化为求n个子问题ai的深度,Ls的深度为ai(i=1,2,3..)的深度中最大值加1,对于每个子问题,若ai是原子,则由定义知其深度为0,若ai为空表,其深度为1,若ai为非空广义表,则采用与上述同样的处理方法。
int depth(Glist ls)
{
int max;
Glist tmp=ls;
if(tmp==NULL)
{
return 1;
}
if(tmp->tag==0)
{
return 0;
}
max=0;
while(tmp!=NULL)
{
dep=depth(tmp->ptr.hp)
if(dep>max)
max=dep;
tmp=tmp->ptr.tp;
}
return max+1;
}

相关文章推荐
- 解析在main函数之前调用函数以及对设计的作用详解
- C++如何调用matlab函数
- 详解Matlab中 sort 函数用法
- WPF调用Matlab函数的方法
- java和matlab画多边形闭合折线图示例讲解
- C#调用Matlab生成的dll方法的详细说明
- Ubuntu 16.04 LTS下安装MATLAB 2014B的方法教程
- Matlab实现数据的动态显示方法
- 在ubuntu16.04上创建matlab的快捷方式(实现方法)
- 简述Matlab中size()函数的用法
- ubuntu下Matlab_Linux添加工具包操作步骤
- 从java中调用matlab详细介绍
- Ubuntu 如何建立Matlab快捷方式
- 详解如何在python中读写和存储matlab的数据文件(*.mat)
- matlab中实现矩阵删除一行或一列的方法
- 稀疏自动编码器 (Sparse Autoencoder)
- 详解Matlab中 sort 函数用法
- 简述Matlab中size()函数的用法