初识python爬虫 Python网络数据采集1.0 BeautifulSoup通过网站css爬取信息
*文章说明这个学习资料是Ryan Mitchel的著作<Web Scraping with Python: Collecting Data from the Modern Web>我算是一步一步跟着一起去学习。分享自及遇到的问题。总结
下面让我们创建一个网络爬虫来抓取 http://www.pythonscraping.com/pages/warandpeace.html这个网页
按下F12进入开发者模式

可以看到在这个页面里,小说人物的对话内容都是红色的,人物名称都是绿色的。
<span class="red"><span class="green">这是两个css样式标签,那么接下来我们通过css样式标签进行网站信息爬取。
首先我们爬取所有的名字[code]from urllib.request import urlopen from bs4 import BeautifulSoup import html5lib html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html") bsObj = BeautifulSoup(html.read(), "html.parser") nameList = bsObj.findAll("span", {"class": "green"}) for name in nameList: print(name.get_text())
#.get_text() 会把你正在处理的 HTML 文档中所有的标签都清除,然后返回一个只包含文字的字符串。
下面是我们的爬取结果

之后我们要去爬取小说的对话内容代码相同我们只需要修改findall函数的参数为findAll("span", {"class":"red"})即可
[code]from urllib.request import urlopen from bs4 import BeautifulSoup import html5lib html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html") bsObj = BeautifulSoup(html.read(), "html.parser") nameList = bsObj.findAll("span", {"class": "red"}) for name in nameList: print(name.get_text())运行结果如下
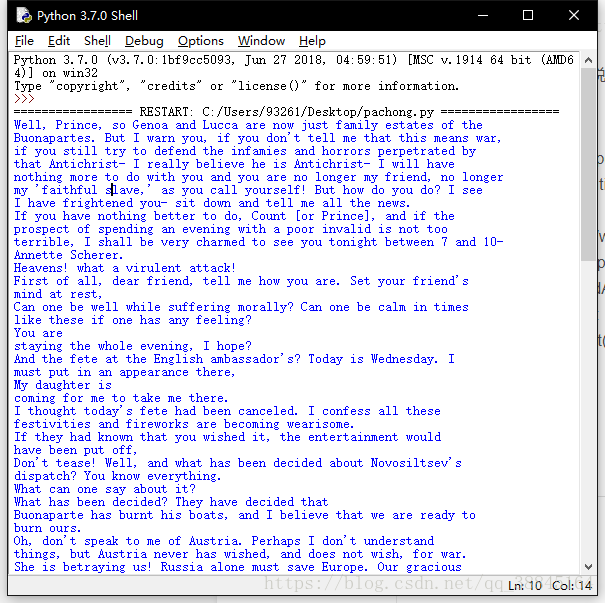
***简单的说明一下:爬取是如果提示远程服务器拒绝访问一类的报错那么可能是网络原因,再次运行即可***
这里还要介绍下find()和findall()
find()找到第一个满足条件的标签就返回,findAll()找到所有满足条件的标签返回。
看一下两个函数的参数,findAll多了一个limit参数。 #参数不是每次用的时候需要把所有参数都要写出来
findAll(tag,atributes,recursive,text,limit,keywords)# recursive 递归的,循环的
find(tag,atributes,recursive,text,keywords)
实例中多用findAll()函数,因为find()函数只返回一个,没有代表性。
①参数tag,可以使用参数tag表明需要查找的标签类型,tag可以是多个:
.findAll({'h1'}) #返回h1标签列表
.findAll({'h1','h2','h3'}) #返回h1-h3标题标签列表
.findAll({'h1','h2','h3','h4','h5','h6','h7'}) #返回所有标题标签的列表
②参数attribute,使用标签内的若干属性对应的属性值进行标签查找,属性值可以是多个
.findAll('span',{'class':{'green','red'}}) #返回class属性为red和green的span标签列表
③参数recursive,是否使用递归方法遍历每一个子标签,默认是开启,True。如果设置为False,findAll()只查找文档的一级标签。一般使用中,不用去动这个参数
④参数text,根据标签的文本内容去查找标签列表,通常配合正则表达式使用
nameList = bsObj.findAll(text='the prince') #匹配所有标签文本内容为‘the prince’的标签列表
nameList = bsObj.findAll(text=re.compile('the*')) #匹配所有标签文本内容为‘the’开头的标签列表,使用了正则表达式re,正则表达式在此文中不做讲解
⑤参数limit,范围限制参数,显然只能用于findAll()函数。就是限定返回的个数,比如要抽取多少个标签信息做样本之类的
⑥参数keyword,标签内指定属性的标签列表#与attribute参数相似,有一个例外就是用class属性查找标签的时候,直接findAll(class=‘green’)会报错,因为class是保留字
bsObj.findAll(id='text')
bsObj.findAll(class='text') #会报错
bsObj.findAll(class_='text')解决方案

- python网络数据采集学习范例—利用CSS爬取网站特定标签,BeautifulSoup函数介绍及子标签
- Python网络数据采集13:用爬虫测试网站
- python爬虫(1)利用BeautifulSoup进行网络数据采集
- python网络数据采集实例-在一个网站上随机地从一个链接跳到另一个链接&采集整个网站
- Python网络数据采集-创建爬虫
- Python 网络爬虫 007 (编程) 通过网站地图爬取目标站点的所有网页
- Python网络数据采集1:初见网络爬虫
- 数据可视化 三步走(一):数据采集与存储,利用python爬虫框架scrapy爬取网络数据并存储
- Python网络数据采集——BeautifulSoup
- python网络数据采集学习范例-通过互联网采集
- Python 网络爬虫 007 (编程) 通过网站地图爬取目标站点的所有网页
- 动态网站数据采集 - 时光网电影信息爬虫
- Python3 大型网络爬虫实战 004 — scrapy 大型静态商城网站爬虫项目编写及数据写入数据库实战 — 实战:爬取淘宝
- 人工智能系统通过网络提高其性能 “信息提取”系统转换纯文本为可以统计分析的数据
- Python网络编程小例子:使用python获取网站域名信息
- Python爬虫实战(4):豆瓣小组话题数据采集―动态网页
- python3实现网络爬虫(3)--BeautifulSoup使用(2)
- 基于scrapy爬虫的天气数据采集(python)
- python 爬虫获取网站信息(一)
- python 爬虫网站分答的json数据