关于语音端点检测(Voice Activity Detection,VAD)的一些汇总
转载于:https://blog.csdn.net/c602273091/article/details/44340451 《语音识别之端点检测》
https://blog.csdn.net/ffmpeg4976/article/details/52349007 《详解语音处理检测技术中的热点--端点检测、降噪和压缩》
https://www.zhihu.com/question/20398418 《语音识别的技术原理是什么? --知乎》
https://www.cnblogs.com/talkaudiodev/p/7041477.html 《音频开发基础知识介绍》
https://blog.csdn.net/kevindgk/article/details/52924779 《音频(一)-音频基础知识》
http://www.doc88.com/p-150262550007.html 《端点检测几种方法比较》
完整的amr编码器还包括语音激活检测(VAD)和丢帧、错帧的消除。VAD的作用是检测当前输入信号中是否有语音,它的输入是输入信号本身和AMR编码器计算出来的参数集,VAD用这个信息来决定每20ms语音帧中是否包括语音。在VAD没有检测到语音的情况下,AMR采用8种速率之外的低速率噪声编码模式,以节省移动台的功率,降低整个网络的干扰和负载。此外,当语音帧由于传输错误而丢失时,为了使接听者感觉不到丢帧,应完成丢帧和错帧的消除,并用预测的参数集进行语音合成。
在语音增强中,我们希望从带噪语音信号中剔除噪音,得到纯净的语音信号,第一步就是提取噪音信息。通常的思路是通过VAD函数得到非语音片段,而非语音片段可以认为是纯噪音片段。从而可以从纯噪音信号中提取出有用信息,例如进行傅里叶变换得到噪音频谱等,再进而做下一步处理。例如谱减法,维纳滤波。此处不作讨论。
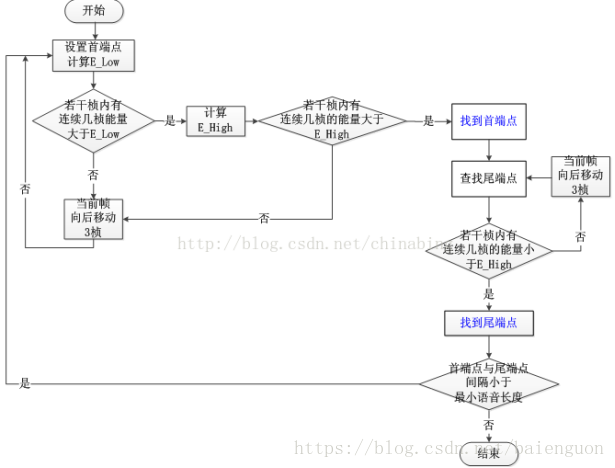
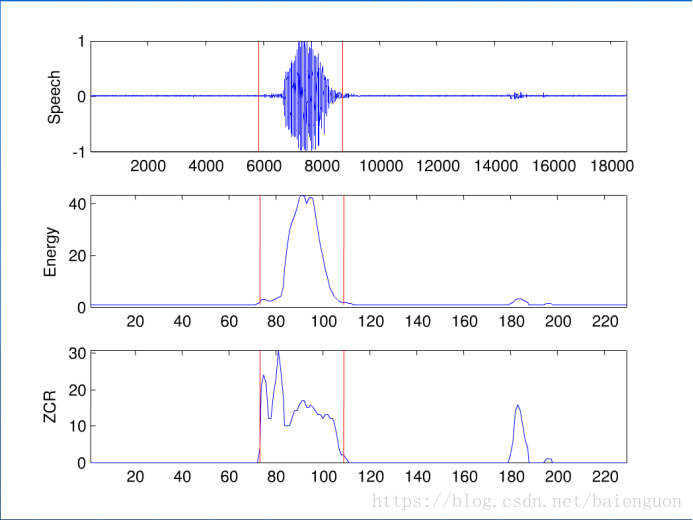
VAD有很多种方法,此处介绍一种最简单直接的办法。 通过short timeenergy (STE)和zero cross counter (ZCC) 来测定。(实际上精确度高的VAD会提取4种或更多的特征进行判断,这里只介绍两种特征的基本方法)。
l STE: 短时能量,即一帧语音信号的能量
l ZCC: 过零率,即一帧语音时域信号穿过0(时间轴)的次数。
理论基础是在信噪比(SNR)不是很低的情况下,语音片段的STE相对较大,而ZCC相对较小;而非语音片段的STE相对较小,但是ZCC相对较大。因为语音信号能量绝大部分包含在低频带内,而噪音信号通常能量较小且含有较高频段的信息。
故而可以通过测量语音信号的这两个特征并且与两个门限(阈值)进行对比,从而判断语音信号与非语音信号。
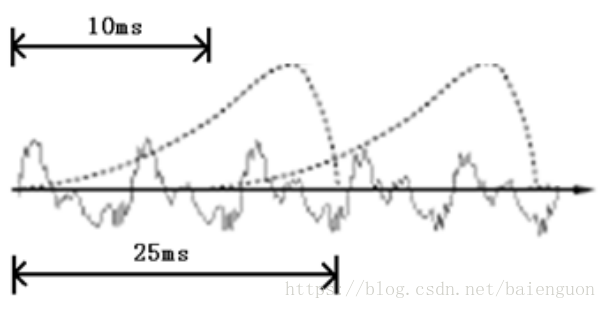
通常对语音信号分帧时取一帧20ms (因为一般会进行短时傅里叶变换,时域和频域的分辨率需要一个平衡,20ms为平衡点,此处不用考虑)。此处输入信号采样率为8000HZ。因此每一帧长度为160 samples.
STE的计算方法是 , 即帧内信号的平方和。
在本文中ZCC的计算方法是,将帧内所有sample平移1,再对应点做乘积,符号为负的则说明此处过零,只需将帧内所有负数乘积数目求出则得到该帧的过零率。VAD(Voice Activity Detection)基于能量的特征常用硬件实现,谱(频谱和倒谱)在低信噪比(SNR)可以获得较好的效果。当SNR到达0dB时,基于语音谐波和长时语音特征更具有鲁棒性。
当前的判决准则可以分为三类:基于门限,统计模型和机器学习。基于能量的准则是检测信号的强度,并且假设语音能量大于背景噪声能量,这样当能量大于某一门限时,可以认为有语音存在。然而当噪声大到和语音一样时,能量这个特征无法区分语音还是纯噪声。
早先基于能量的方法,将宽带语音分成各个子带,在子带上求能量;因为语音在2KHz以下频带包含大量的能量,而噪声在2~4KHz或者4KHz以上频带比0~2HKz频带倾向有更高的能量。这其实就是频谱平坦度的概念,webrtc中已经用到了。在信噪比低于10dB时,语音和噪声的区分能力会加速下降。





阅读更多

- 语音端点检测(voice activity detection,VAD)
- 关于webrtc的VAD(voice activity dectctor)算法说明
- 关于webrtc的VAD(voice activity dectctor)算法说明
- webrtcvad python——语音端点检测
- 关于内表数据汇总的一些算法
- 关于Activity一些技巧
- 在安装并使用tensorflow中的Object-detection模块时遇到的一些问题汇总及解决方法
- STM32中关于检测按键的一些问题(关于采用传统的延时消抖方式和采用中断方式)
- 关于项目中的一些经验:封装activity、service的基类,封装数据对象
- 如何设置dialog下面的activity不变灰色。关于dialog的一些属性设置。
- 关于windows下的一些常用操作、功能的汇总,偶尔更新
- 关于 C++ 框架、库和资源的一些汇总列表
- 关于新版本微信分享的一些汇总
- [行为检测]R-C3D-Resgion Convolutional 3D Network for Temporal Activity Detection
- 【转】关于onActivityResult方法不执行的问题汇总
- 目标检测(Object Detection)资料汇总
- 文章汇总:关于java的finalize,引用和引用队列,自动释放系统外部资源的一些文章
- 关于黑屏时启动Activity的一些方法
- 关于软件的使用中的一些小问题的记录汇总(长期更新)
- 关于onActivityResult方法不执行的问题汇总