如约而至,Java 10 正式发布! Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十四)Redis缓存正确的使用姿势 努力的孩子运气不会太差,跌宕的人生定当更加精彩 优先队列详解(转载)
如约而至,Java 10 正式发布!
3 月 20 日,Oracle 宣布 Java 10 正式发布。
官方已提供下载:http://www.oracle.com/technetwork/java/javase/downloads/index.html 。
在 Java 9 之后,Java 采用了基于时间发布的策略,每 6 个月一个版本。这是采用新的发布策略之后的第一个版本。
Java 10 主要有 12 个新特性。

具体来看看。
JEP 286: Local-Variable Type Inference
局部变量的类型推导。
很多人都会吐槽 Java 代码写起来太过繁琐,特别是涉及泛型的时候。就像 C++,也基于 auto 关键字引入了类型推导功能。
Java 也计划引入类似特性,语法是这样的:
var list = new ArrayList<String>(); // infers ArrayList<String> var stream = list.stream(); // infers Stream<String>
该特性只能用于三种场景:
带有初始化信息的局部变量
增强 for 循环中的索引
传统 for 循环中的局部变量
看个复杂点的例子:

对该特性感兴趣的读者可以参考:https://developer.oracle.com/java/jdk-10-local-variable-type-inference 。
JEP 296: Consolidate the JDK Forest into a Single Repository
将 JDK 的多个代码仓库合并到一个代码仓库中。
看过 JDK 代码的应该知道,JDK 的不同功能分布在不同代码仓库中。以 JDK 9 为例,代码仓库有 8 个: root, corba, hotspot,jaxp, jaxws, jdk, langtools 和 nashorn。其中 hotspot 是虚拟机实现代码,jdk 是 Java 类库和相关工具,langtools 是 javac 等工具,nashorn 是 JavaScript 引擎。
JEP 304: Garbage Collector Interface
垃圾收集器接口。
在 hotspot/gc 代码实现方面,引入一个干净的垃圾收集器接口,改进不同垃圾收集器源代码的隔离性。这样添加新的或者删除旧的 GC,都会更容易。
JEP 307: Parallel Full GC for G1
为 G1 垃圾收集器引入并行 Full GC。
JEP 310: Application Class-Data Sharing
Java 之前就引入了类数据共享机制,Class data sharing (CDS) ,以减少 Java 程序的启动时间,降低内存占用。简单来说,Java 安装程序会把 rt.jar 中的核心类提前转化成内部表示,转储到一个共享的文件中(shared archive)。多个 Java 进程(或者说 JVM 实例)可以共享这部分数据。
现在,希望更近一步,支持应用类的数据共享。
JEP 312: Thread-Local Handshakes
修改安全点机制,使得部分回调操作只需要停掉单个线程,而不像以前那样,只能选择或者停掉所有线程,或者都不停止。
JEP 313: Remove the Native-Header Generation Tool (javah)
去掉 javah 工具。
从 JDK 8 开始,javah 的功能已经集成到了 javac 中。所以,javah 可以删掉了。
JEP 314: Additional Unicode Language-Tag Extensions
额外的 Unicode 语言标签扩展。
增强 java.util.Locale 和相关 API,实现 BCP 47 语言标签中额外的 Unicode 扩展。
JEP 316: Heap Allocation on Alternative Memory Devices
在可选内存设备上分配堆内存。
支持将 Java 对象堆分配到 NV-DIMM 等内存设备上。随着 NV-DIMM 越来越便宜,未来的系统可能会搭载异构内存架构。
JEP 317: Experimental Java-Based JIT Compiler
实验性的基于 Java 的 JIT 编译器。
支持基于 Java 的 JIT 编译器。相关工作主要基于 Graal。Graal 也是 Java 9 中引入的 AOT 编译器的基础。
JEP 319: Root Certificates
根证书。
在 JDK 中提供一组默认的根证书。
JEP 322: Time-Based Release Versioning
基于时间的版本字符串。修改 Java SE 平台和 JDK 版本字符串机制。考虑和之前版本号的兼容等问题,新的版本命名机制是: $FEATURE.$INTERIM.$UPDATE.$PATCH
$FEATURE,每次版本发布加 1,不考虑具体的版本内容。(之前的主版本号部分)2018 年 3 月的版本是 JDK 10,9 月的版本是 JDK 11,依此类推。
$INTERIM,中间版本号,在大版本中间发布的,包含问题修复和增强的版本,不会引入非兼容性修改。
Spring+SpringMVC+MyBatis+easyUI整合进阶篇(十四)Redis缓存正确的使用姿势
作者:13
GitHub:https://github.com/ZHENFENG13
版权声明:本文为原创文章,未经允许不得转载。
简介
这是一篇关于Redis使用的总结类型文章,会先简单的谈一下缓存的应用场景、缓存的使用逻辑及注意事项,然后是Redis缓存与数据库间结合以进行系统优化,当然文章的最后也会给出具体的代码实现,不至于看到文章的你一头雾水,理论要讲,项目代码也要分享,这是我写博客的基本出发点。
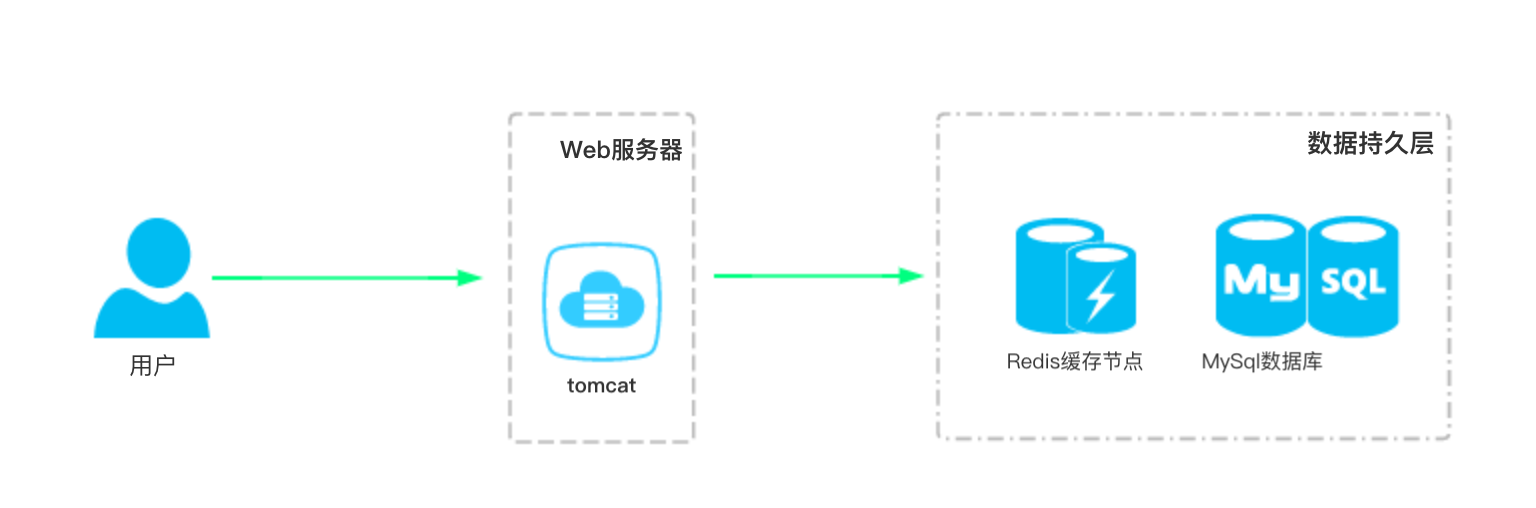
应用场景
Redis能做什么呢?
这是个好问题,不同的人可能会给出不同的答案,因为它的应用场景真的很多,作为一个优秀的nosql数据库可以结合其他产品做很多事情,比如:tomcat集群的session同步、与nginx和lua结合做限流工具、基于Redis的分布式锁实现、分布式系统唯一主键生成策略、秒杀场景中也会看到它、它还能够作为一个消息队列.....
Redis的应用场景很多很多,以上也只是列举了一部分而已,由于本文是围绕我的开源项目perfect-ssm来写的,所以在本文的场景就是一个缓存中间层,对于读多写少的应用场景,我们经常使用缓存来进行优化以提高系统性能。
我曾经写过一篇《一次线上Mysql数据库崩溃事故的记录》的文章,里面记录了Web请求是如何毫不留情的摧垮mysql数据库,进而导致网站应用无法正常运转。当时的情况就是数据库读请求太多,事故的主要原因也是这个,后续的解决方案也就是在项目中添加缓存层,使得热点数据得以存入缓存,不会重复的去读取mysql,将大部分请求压力转移至Redis缓存中以减轻mysql的负担。

接入缓存后的处理逻辑
请求过来后,首先判断Redis里面有没有,有数据则直接返回Redis中的数据给用户,没有则查询数据库,如果数据库中也没有则返回空或者提醒语句即可。
当然,针对不同的操作,对于Redis和mysql的操作也是不同的:
添加操作
如果是需要放入缓存的数据,那么在向mysql数据库中插入成功后,生成对应的key至,并存入Redis中。
修改操作
向mysql数据库中修改成功后,修改Redis中的数据,但是Redis并没有更新语句,所以只能先删除,再添加完成更新操作。
需要注意的是,考虑到程序对于Redis的操作可能会失败,这时mysql中的数据已经修改,但是Redis中的数据依然是上一次的数据,导致数据不一致的问题,所以是先操作Redis还是先操作mysql需要慎重考虑。
删除操作
与修改操作相同,先删除数据,再更新缓存,但是同样会有出现数据不一致问题的可能性需要注意,如果数据库中的数据删除了,但是Redis中的数据没删除,又会出现业务问题。
查询操作
首先通过Redis查询,如果缓存中已经存在数据则直接返回即可,此时就不再需要通过mysql数据库来获取数据,减少对mysql的请求,如果缓存中不存在数据,则依然通过mysql数据库查询,查询到数据后,存入Redis缓存中。
本项目中的代码是先操作mysql,再操作Redis,有概率会出现上文中提到的数据库与缓存数据不一致的情况,所以需要注意,本文的代码只做参考,用到实际项目中还是需要根据具体的业务逻辑进行合理的修改。
使用缓存的建议
缓存存储策略:
可以缓存的数据的特征基本上是以下几点:
- 热点数据
- 实时性要求不高的数据
- 业务逻辑简单的数据
至于什么数据,不同的系统、不同的项目要求肯定不同,这里不做过多讨论,只简单的说一下自己的想法,结合以上的特征总结如下:
- 1.首页数据、分类数据这些数据属于热点数据,首页数据更是热得发烫,而且这类数据一般实时性不高,不会频繁的去操作,比较适合放入缓存。
- 2.详情数据,比如文章详情、商品详情、广告详情、个人信息详情,这些数据库中单条的的数据可以以其id生成不同的key保存到Redis,操作比较简单明了,在更新或者删除的时候需要同步更新Redis中的数据,这类数据也适合放入缓存中。
- 3.列表数据不是特别推荐,除非是实时性和改变频率真的很低的情况下,因为列表往往牵涉的数据和操作很多,处理起来比较复杂,如果对实时性要求低的话、或者部分字段更新频率低的话,可以换成这部分数据。
缓存存储策略的制定说难也难,说容易也容易,主要是根据具体的业务场景合理的操作即可,以上只是做了一个简单的总结。
缓存失效策略:
失效策略一定要做好,血的教训。
- 定时删除
含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
优点:保证内存被尽快释放
缺点:
若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
- 惰性删除
含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期则删除,返回null。
优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
- 定期删除
含义:每隔一段时间执行一次删除过期key操作
优点:
通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点
定期删除过期key--处理"惰性删除"的缺点
缺点
在内存友好方面,不如"定时删除"
在CPU时间友好方面,不如"惰性删除"
难点
合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
参考《Redis设计与实现》
缓存操作顺序策略:
在上文中已经讲到了操作顺序的问题,是先操作mysql呢?还是先操作Redis呢?这个需要根据自己的业务逻辑来考量,尽量选择影响较小且结合友好的方案来做。
代码实现:
这里只贴出主要的逻辑代码,想要完整实现的可以到代码仓库去取。
//添加
@Override
public int addArticle(Article article) {
if (articleDao.insertArticle(article) > 0) {
log.info("insert article success,save article to Redis");
RedisUtil.put(Constants.ARTICLE_CACHE_KEY + article.getId(), article);
return 1;
}
return 0;
}
//修改
@Override
public int updateArticle(Article article) {
if (article.getArticleTitle() == null || article.getArticleContent() == null || getTotalArticle(null) > 90 || article.getArticleContent().length() > 50000) {
return 0;
}
if (articleDao.updArticle(article) > 0) {
log.info("update article success,delete article in Redis and save again");
RedisUtil.del(Constants.ARTICLE_CACHE_KEY + article.getId());
RedisUtil.put(Constants.ARTICLE_CACHE_KEY + article.getId(), article);
return 1;
}
return 0;
}
//删除
@Override
public int deleteArticle(String id) {
RedisUtil.del(Constants.ARTICLE_CACHE_KEY + id);
return articleDao.delArticle(id);
}
//查询
@Override
public Article findById(String id) {
log.info("get article by id:" + id);
Article article = (Article) RedisUtil.get(Constants.ARTICLE_CACHE_KEY + id, Article.class);
if (article != null) {
log.info("article in Redis");
return article;
}
Article articleFromMysql = articleDao.getArticleById(id);
if (articleFromMysql != null) {
log.info("get article from mysql and save article to Redis");
RedisUtil.put(Constants.ARTICLE_CACHE_KEY + articleFromMysql.getId(), articleFromMysql);
return articleFromMysql;
}
return null;
}
结语
首发于我的个人博客,新的项目演示地址:perfect-ssm,登录账号:admin,密码:123456

如果有问题或者有一些好的创意,欢迎给我留言,也感谢向我指出项目中存在问题的朋友。
如果你想继续了解该项目可以查看整个系列文章Spring+SpringMVC+MyBatis+easyUI整合系列文章,也可以到我的GitHub仓库或者开源中国代码仓库中查看源码及项目文档。
努力的孩子运气不会太差,跌宕的人生定当更加精彩
一直以来,我始终坚信这个理念,努力一定会有收获,如果没有收获或者收获很小的话,那就只能说明你不够努力。其实,只要在这个世界上生存的人,都需要为自己的人生,自己的事业,学业拼搏着,努力着,不努力就会在社会的激烈竞争中被淘汰,任何人都在为之努力奋斗着,谁敢说自己不曾努力呢。曾经有很多粉丝私信我说,你哪里来的这么多的时间去学这些东西。其实啊,你只要愿意去挤,时间总会有的。我只不过是把你们打游戏的时间拿来学习,把你们上课听讲的时间用到学其他领域上面,把你们放假的时间拿来加班,仅此而已。成功并非一蹴而就,需要经历时间的拷打与历练,做一行就要热爱一行,有一颗探索未知的好奇心很重要,找对方法,不懈奋斗,一直不断的坚持下去,你的人生一定会非常的独特与精彩。
曾经也看了@张善友的一篇文章,题为十年微软MVP路(如何成为一个MVP?),他是腾讯的大BOSS级别的人物,到现在为止连续十二年获得微软MVP,算是国内ASP.NET方向上的权威专家了,我们撇开他的成绩不谈,单从他的工作历程来看,十多年来始终坚守在.ASP.NET方向,一直在博客园里向国内的开发社区推广开源技术,没有考虑过换成其他的方向(客观原因是因为有个和他一直并肩作战的开发团队),无私的为这个圈子分享着自己的知识和经验,他荣获MVP头衔定当实至名归,这或许是我一直以来坚持继续写博客,分享自己知识的动力源泉吧。向比你优秀的人看齐,站在比你优秀的人一边,自然而然你也会变得更加优秀。
知识本就有个半衰期,特别是在新型的互联网行业,现在所学的知识,意味着毕业以后,我所学的一半的知识是毫无价值的。在这个行业里面,知道知识的半衰期实际上是件极好的事情,这使你永远不会变成沉舟病树。我们将被迫持续学习新东西,而这对于我们未来的工作和生活会因此收益匪浅。
行业上曾这么说过,说程序员一到40岁就会进入淘汰期。这个确实不假,如果我作为一个CEO,我宁愿是去招聘一些年轻的,薪水要求低的,有活力,创造力,学习能力强的程序员,而并非是需要像这种知识老化,思想固化,不愿去学习,薪水要求很高的老年人,即使他们的编程能力还不错。在这个行业里,仅靠一纸文凭,终将变得毫无价值,老板会把他们像用过的纸巾一样抛弃掉,千万不要变成这样的人。我们能做的就是不断的学习学习再学习,而最好的学习方式无疑是和你的同僚分享知识,经常讨论技术前沿,让你的思维长期处于活跃状态。
曾经也有粉丝私信我说,为什么付出和回报不成正比?原因很简单,有些东西不是光靠努力就能达得到的,个人天赋悟性也是极其的重要。不要总是去责怪老天爷的不公,多去思考自己到底为此付出了多少汗水?社会本来就是不公平的,从高考的那一刻起,多多少少就已经把能力不同的人用一个名叫大学的容器给区分开来。能力强的人被分到985,211的那个容器里面,能力弱的分到所谓的三流学校的容器里面。当录取通知书到来的那一刻起,你应该明白,你不是属于那个能力强的容器里面的人,你只是呆在一个普通的不能再普通的高等院校,为何总是期望予自己能力能够达到甚至超越他们呢?
每每看到粉丝们找我求助、热切地想要改变自己命运的时候,我就想起了曾经的那个我。记得曾经聆听过刘媛媛关于寒门贵子的演说,感受最深的一句话是:命运给你一个比别人低的起点,是想告诉你,让你用你的一生去奋斗出一个绝地反击的故事。我出身寒门,没有哥哥姐姐弟弟妹妹,体弱多病。一直以来,我爸我妈为了供我读书看病,拼死拼活的在外面赚钱。我又何尝不去努力学习呢?小时候我也是非常羡慕别人家的孩子有父母接送,有爷爷奶奶的疼爱,每次放学的时候都是我一个人回家,一个人洗衣做饭,十几年一直是在这种风波摇曳中度过的,可这又有什么办法呢? 我一直也不会拿自己跟那些比如说家庭富裕的小孩做比较,说我们之间有什么不同,或者有什么不平等,但是我们必须要承认这个世界是有一些不平等的,他们有很多优越的条件我们都没有,他们有很多的捷径我们也没有,但是我们不能抱怨。每一个人的人生都不尽相同的,有些人出生就含着金钥匙,有些人出生连爸妈都没有,人生跟人生是没有可比性的,我们的人生是怎么样完全决定于自己的感受。你一辈子都在感受抱怨,那你的一生就是抱怨的一生;你一辈子都在感受感动,那你的一生就是感动的一生;你一辈子都立志于改变这个社会,那你的一生就是斗士的一生。
当我们遭遇失败的时候,我们不能把所有的原因都归结到出生上去,更不能抱怨自己的父母为什么不如别人的父母,因为家境不好,并没有斩断一个人他成功的所有的可能。当我在人生终于到很大的困难的时候,这时候我会去想,我真的是一无所依,我能依靠的只是我自己,我什么都没有,我现在能做的就是单枪匹马的,在这个社会上杀出一条路来,只有自己强大了才能真正的赢得别人的尊重。
我知道很多acmer的苦衷,把大学宝贵的四年时光投入到acm竞赛上,放弃了很多本该可以做的更好的事情上,学业成绩不景气,挂了很多科目,想退坑又不敢退,退了就真的一无所有了。acm是一件快乐的事情,快乐到上瘾;快乐到能够写题写一通宵而不觉得累;快乐到至今也无法忘记登上领奖台紧张到手抖的样子。,不是每个人都是有清北学生的潜质,有的话你也不会沦落至此。不要整天去幻想既要学习成绩优秀,又想在自己喜欢的领域取得优异的成绩,醒醒吧,骚年,现实一点。每个行业都有值得尊敬的地方,并不是有些人的片面观点说,有了acm就有了一切。不管哪个行业,你只要认真的尝试融入进去,你就会发现这个世界真的很大,大到自己都不敢相信。你会看到比自己强的人,他们比你还努力。我的很多朋友,有挂了近20科即将拿不到毕业证的,他们同样是拿到了金牌银牌的,取得了十分优异的成绩,最后同样去了BAT之类的大场子上班,就业前景一点都不比清北毕业的学生差。如果世界上有后悔药,如果老天爷再给你一次选择的机会,我相信大多数人都会选择认真学习。自己选择的路,跪着也要走完。
我不是一位作家,我只是一个在互联网行业爱分享的奋斗小青年。
时2018年5月17日作
优先队列详解(转载)
1 优先队列:顾名思义,首先它是一个队列,但是它强调了“优先”二字,所以,已经不能算是一般意义上的队列了,它的“优先”意指取队首元素时,有一定的选择性,即根据元素的属性选择某一项值最优的出队~
2 百度百科上这样描述的:
3 优先级队列 是不同于先进先出队列的另一种队列。每次从队列中取出的是具有最高优先权的元素
4 优先队列的类定义
5 优先队列是0个或多个元素的集合,每个元素都有一个优先权或值,对优先队列执行的操作有1) 查找;2) 插入一个新元素;3) 删除.在最小优先队列(min priorityq u e u e)中,查找操作用来搜索优先权最小的元素,删除操作用来删除该元素;对于最大优先队列(max priority queue),查找操作用来搜索优先权最大的元素,删除操作用来删除该元素.优先权队列中的元素可以有相同的优先权,查找与删除操作可根据任意优先权进行.
6 优先队列,其构造及具体实现我们可以先不用深究,我们现在只需要了解其特性,及在做题中的用法,相信,看过之后你会收获不少。
7 使用优先队列,首先要包函STL头文件"queue",
8 以一个例子来解释吧(呃,写完才发现,这个代码包函了几乎所有我们要用到的用法,仔细看看吧):
9 view plaincopy to clipboardprint?
10 /*优先队列的基本使用 2010/7/24 dooder*/
11 #include<stdio.h>
12 #include<functional>
13 #include<queue>
14 #include<vector>
15 using namespace std;
16 //定义结构,使用运算符重载,自定义优先级1
17 struct cmp1{
18 bool operator ()(int &a,int &b){
19 return a>b;//最小值优先
20 }
21 };
22 struct cmp2{
23 bool operator ()(int &a,int &b){
24 return a<b;//最大值优先
25 }
26 };
27 //定义结构,使用运算符重载,自定义优先级2
28 struct number1{
29 int x;
30 bool operator < (const number1 &a) const {
31 return x>a.x;//最小值优先
32 }
33 };
34 struct number2{
35 int x;
36 bool operator < (const number2 &a) const {
37 return x<a.x;//最大值优先
38 }
39 };
40 int a[]={14,10,56,7,83,22,36,91,3,47,72,0};
41 number1 num1[]={14,10,56,7,83,22,36,91,3,47,72,0};
42 number2 num2[]={14,10,56,7,83,22,36,91,3,47,72,0};
43
44 int main()
45 { priority_queue<int>que;//采用默认优先级构造队列
46
47 priority_queue<int,vector<int>,cmp1>que1;//最小值优先
48 priority_queue<int,vector<int>,cmp2>que2;//最大值优先
49
50 priority_queue<int,vector<int>,greater<int>>que3;//注意“>>”会被认为错误, 51//这是右移运算符,所以这里用空格号隔开 52 priority_queue<int,vector<int>,less<int>>que4;////最大值优先 5354 priority_queue<number1>que5;55 priority_queue<number2>que6;5657int i;58for(i=0;a[i];i++){59 que.push(a[i]);60 que1.push(a[i]);61 que2.push(a[i]);62 que3.push(a[i]);63 que4.push(a[i]);64}65for(i=0;num1[i].x;i++)66 que5.push(num1[i]);67for(i=0;num2[i].x;i++)68 que6.push(num2[i]);697071 printf("采用默认优先关系:\n(priority_queue<int>que;)\n");72 printf("Queue 0:\n");73while(!que.empty()){74 printf("%3d",que.top());75 que.pop();76}77 puts("");78 puts("");7980 printf("采用结构体自定义优先级方式一:\n(priority_queue<int,vector<int>,cmp>que;)\n");81 printf("Queue 1:\n");82while(!que1.empty()){83 printf("%3d",que1.top());84 que1.pop();85}86 puts("");87 printf("Queue 2:\n");88while(!que2.empty()){89 printf("%3d",que2.top());90 que2.pop();91}92 puts("");93 puts("");94 printf("采用头文件\"functional\"内定义优先级:\n(priority_queue<int,vector<int>,greater<int>/less<int> >que;)\n");95 printf("Queue 3:\n");96while(!que3.empty()){97 printf("%3d",que3.top());98 que3.pop();99}100 puts("");101 printf("Queue 4:\n");102while(!que4.empty()){103 printf("%3d",que4.top());104 que4.pop();105}106 puts("");107 puts("");108 printf("采用结构体自定义优先级方式二:\n(priority_queue<number>que)\n");109 printf("Queue 5:\n");110while(!que5.empty()){111 printf("%3d",que5.top());112 que5.pop();113}114 puts("");115 printf("Queue 6:\n");116while(!que6.empty()){117 printf("%3d",que6.top());118 que6.pop();119}120 puts("");121return0;122}123/*124运行结果 :
125采用默认优先关系:
126(priority_queue<int>que;)
127Queue 0:
12883 72 56 47 36 22 14 10 7 3
129130采用结构体自定义优先级方式一:
131(priority_queue<int,vector<int>,cmp>que;)
132Queue 1:
133 7 10 14 22 36 47 56 72 83 91
134Queue 2:
13583 72 56 47 36 22 14 10 7 3
136137采用头文件"functional"内定义优先级:
138(priority_queue<int,vector<int>,greater<int>/less<int> >que;)
139Queue 3:
140 7 10 14 22 36 47 56 72 83 91
141Queue 4:
14283 72 56 47 36 22 14 10 7 3
143144采用结构体自定义优先级方式二:
145(priority_queue<number>que)
146Queue 5:
147 7 10 14 22 36 47 56 72 83 91
148Queue 6:
14983 72 56 47 36 22 14 10 7 3
150*/151运行结果:152采用默认优先关系:153(priority_queue<int>que;)154Queue0:155837256473622141073156采用结构体自定义优先级方式一:157(priority_queue<int,vector<int>,cmp>que;)158Queue1:1597101422364756728391160Queue2:161837256473622141073162采用头文件"functional"内定义优先级:163(priority_queue<int,vector<int>,greater<int>/less<int>>que;)164Queue3:1657101422364756728391166Queue4:167837256473622141073168采用结构体自定义优先级方式二:169(priority_queue<number>que)170Queue5:1717101422364756728391172Queue6:173837256473622141073174好了,如果你仔细看完了上面的代码,那么你就可以基本使用优先队列了,下面给出一些我做题中有过的一些应用,希望能给大家带来一些启175示~1761、先来一个我们最近做的题吧,http://acm.hdu.edu.cn/showproblem.php?pid=1242177题意:某人被关在囚笼里等待朋友解救,问能否解救成功,最少需要多少时间~178具体:可同时有几个朋友,每走一格消耗一分钟的时间,地图上还存在着卫兵,卫兵可以解决掉,但是要另外花费一分钟~179分析:从“a”出发,此题可以用回溯法进行深搜,但那样做的话,效率还是不能让人满意,但是广搜的话,由于入队后每次出队时,根据地180图情况的不同,出队元素所记忆的时间并不是层次递增的,因此使用简单广搜的话,同样需要全部搜索才能找到正确答案。有没有一种方法能181让某一步因为遇到士兵而多花时间的结点在队列中向后推迟一层出队呢?答案是肯定的,在这里我们可以用优先队列来实现,总体思想上是,182根据时间进行优先性选择,每次都要出队当前队列元素中记录时间最少的出队,而入队处理时,我们可以按顺序对四个方向上的各种情况按正183常处理入队就行了,出队顺序由优先队列根据预设优先性自动控制。这样,我们就可以从“a”进行基于优先队列的范围搜索了,并且在第一184次抵达有朋友的位置时得到正确结果~具体实现代码:185 view plaincopy to clipboardprint?186/*HDU 1242 基于优先队列的范围搜索,16ms dooder*/187188#include<stdio.h>189#include<queue>190usingnamespace std;191192#define M 201193typedefstruct p{194int x,y,t;195booloperator<(const p &a)const196{197return t>a.t;//取时间最少优先 198}199}Point;200201char map[M][M];202Point start;203int n,m;204int dir[][2]={{1,0},{-1,0},{0,1},{0,-1}};205206int bfs()207{208 priority_queue<Point>que;209Point cur,next;210int i;211212 map[start.x][start.y]='#';213 que.push(start);214while(!que.empty()){215 cur=que.top();//由优先队列自动完成出队时间最少的元素 216 que.pop();217for(i=0;i<4;i++){218next.x=cur.x+dir[i][0];219next.y=cur.y+dir[i][1];220next.t=cur.t+1;221if(next.x<0||next.x>=n||next.y<0||next.y>=m)222continue;223if(map[next.x][next.y]=='#')224continue;225if(map[next.x][next.y]=='r')226returnnext.t;227if(map[next.x][next.y]=='.'){228 map[next.x][next.y]='#';229 que.push(next);230}231elseif(map[next.x][next.y]=='x'){232 map[next.x][next.y]='#';233next.t++;234 que.push(next);235}236}237}238return-1;239}240int main()241{242int i,ans;243char*p;244while(scanf("%d%d",&n,&m)!=-1){245for(i=0;i<n;i++){246 scanf("%s",map[i]);247if(p=strchr(map[i],'a')){248 start.x=i;249 start.y=p-map[i];250 start.t=0;251}252}253 ans=bfs();254 printf(ans+1?"%d\n":"Poor ANGEL has to stay in the prison all his life.\n",ans);255}256return0;257}2582、http://acm.hdu.edu.cn/showproblem.php?pid=1053259题意:给出一行字符串,求出其原编码需要的编码长度和哈夫曼编码所需的长度,并求其比值260分析:根据哈夫曼生成树的生成过程可知,其生成树的权值是固定的而且这个值是最小的,而且其值根据生成树的顺序,我们可以找出规律而261不需要真的去生成一棵树然后再求出权值,其模拟过程为取出队列中权值最小的两个元素,将其值加入结果中,然后将这两个元素的权值求和262即得出其父节点的权值,将生成元素作为结点入队~~如此循环,直至取出队列中最后两个元素加入结果,实现代码如下:263 view plaincopy to clipboardprint?264/*HDU 1053 采用广搜求哈夫曼生成树的权值 0ms dooder*/265#include<stdio.h>266#include<string.h>267#include<ctype.h>268#include<functional>269#include<queue>270usingnamespace std;271#define M 1000050272char str[M];273int list[27];274275 priority_queue<int,vector<int>,greater<int>>que;276277int main()278{279int ans,sum;280int i,a,b,c;281while(scanf("%s",str),strcmp(str,"END")){282 memset(list,0,sizeof(list));283for(i=0;str[i];i++){284if(isalpha(str[i]))285 list[str[i]-'A']++;286else287 list[26]++;288}289 sum=i*8;ans=i;c=0;290for(i=0;i<27;i++){291if(list[i]){292 que.push(list[i]);293 c++;294}295}296if(c>1){ans=0;//注意只有一种字符的情况 297while(que.size()!=1){298 a=que.top();299 que.pop();300 b=que.top();301 que.pop();302 ans+=a+b;303 que.push(a+b);304}305while(!que.empty())//使用后清空队列 306 que.pop();307}308 printf("%d %d %.1f\n",sum,ans,1.0*sum/ans);309}310return0;311}3123、http://acm.pku.edu.cn/JudgeOnline/problem?id=2263313这是第二次练习赛时,我们做过的最后一题,这里采用优先队列进行实现,在《谁说不能这样做题》中已提到这种方法,在这里再次放出代314码,~315题意:给出各城市间道路的限制载重量,求出从一个城市到另外一个城市的贷车能够运载的最大货物重量。316分析:采用优先队列,每次取出当前队列中结点的minheavy最大值出队,对它的连接结点搜索入队,这样,从出发点开始就可以317在到达终点时求出结果,即最大载货物重,实现代码如下:318 view plaincopy to clipboardprint?319/*POJ 2263 16ms dooder*/320321#include<stdio.h>322#include<string.h>323#include<queue>324usingnamespace std;325#define M 201326typedefstruct w{327int city;328int mintons;329booloperator<(const w &a)const{330return mintons < a.mintons;331}//优先性定义 332}Way;333char citys[M][31];334int map[M][M];335bool mark[M][M];336int n,m,from,to,ans,k;337 priority_queue <Way> que;338int min(int a,int b)339{340return a>b?b:a;341}342void bfs()343{344Way cur,next;345int i;346while(!que.empty()){347 cur=que.top();348 que.pop();349if(cur.city==to){350if(cur.mintons>ans)351 ans=cur.mintons;352while(!que.empty())353 que.pop();354return;355}356for(i=0;i<n;i++){357if(map[cur.city][i]&&!mark[cur.city][i]){358next.city=i;359next.mintons=min(cur.mintons,map[cur.city][i]);360361 mark[cur.city][i]=mark[i][cur.city]=1;362 que.push(next);363}364}365}366}367void run()368{369int i,temp,index;370Way cur;371 ans=0;372 memset(mark,0,sizeof(mark));373 temp=0;374for(i=0;i<n;i++){375if(map[from][i]>temp){376 temp=map[from][i];377 index=i;378}379}380 cur.city=index;381 cur.mintons=temp;382 que.push(cur);383 bfs();384}385int main()386{387int k1,k2,tons,t=1;388char s1[31],s2[31];389while(scanf("%d%d",&n,&m),n||m){390 k=0;391while(m--){392 scanf("%s%s%d",s1,s2,&tons);393for(k1=0;strcmp(s1,citys[k1])&&k1<k;k1++);394if(k1==k)395 strcpy(citys[k++],s1);396for(k2=0;strcmp(s2,citys[k2])&&k2<k;k2++);397if(k2==k)398 strcpy(citys[k++],s2);399 map[k1][k2]=map[k2][k1]=tons;400}401 scanf("%s%s",s1,s2);402for(from=0;strcmp(citys[from],s1);from++);403for(to=0;strcmp(citys[to],s2);to++);404 run();405 printf("Scenario #%d\n",t++);406 printf("%d tons\n\n",ans);407}408return0;409}410当然了,优先队列的用法决不是仅仅提到的这些,各种应用还需要大家去发现,给道题大家可以练习一下hdu 2066\
411相信大家已经学到不少了,还有一点可以告诉大家,优先队列是启发式搜索的数据结构基础,希望好好理解,并逐步掌握其用法~412加:失策啊,竟然忘了说优先队列的效率了,其时间复杂度为O(logn).n为队列中元素的个数,存取都需要消耗时间~

- 如约而至,Java 10 正式发布:包含 109 项新特性
- 如约而至,Java 10 正式发布:包含 109 项新特性
- 如约而至,Java 10 正式发布:包含 109 项新特性
- 10、Spring技术栈-整合Redis,使用RedisTemplate实现数据缓存实战
- 详解redis与spring的整合(使用缓存)
- Redis全方位详解--数据类型使用场景和redis分布式锁的正确姿势
- Java中vector的使用详解 (转载)
- Redis系列-JAVA与redis整合-Spring Data Redis实现一个订阅/发布系统
- 优先队列详解(转载)
- 优先队列详解(转载)
- 优先队列详解(转载)
- java 注解的几大作用及使用方法详解(转载)
- Java中如何使用Redis做缓存
- 【转载】java枚举使用详解
- java redis使用之利用jedis实现redis消息队列
- 高阶Java-Java注解 Java annotation 使用详解【转载的】
- 基于JAVA中使用Axis发布/调用Webservice的方法详解
- Redis系列-JAVA与redis整合-JedisPool的使用
- 使用Redis构建消息队列和发布订阅系统
- 使用 Eclipse 调试 Java 程序的 10 个技巧(转载)