《机器学习实战》第8章学习笔记(回归)之预测乐高玩具套装的价格
2018-05-07 17:02
260 查看
原文中通过Google提供的API来抓取价格,但由于现在访问不了Google,所以,直接通过文本给的html文件直接读取价格信息。然后进一步进行分析预测。
代码实现:
# -*- coding: utf-8 -*-
"""
Created on Mon May 7 09:55:34 2018
@author: lizihua
"""
#from time import sleep
#import json
#import urllib
#from BeautifulSoup import BeautifulSoup
from bs4 import BeautifulSoup
from numpy import random,zeros,mat,var, mean,array,nonzero,multiply,linalg,eye,shape,exp,ones
import numpy as np
import matplotlib.pyplot as plt
"""
#由于Google购物API关闭,采用下一段读取网页文件代码代替此爬虫过程
def searchForSet(retX,retY,setNum,yr,numPce,origPrc):
sleep(10)
myAPIstr = 'get from code.google.com'
searchURL = 'https://www.googleapis.com/shopping/search/v1/public/products?key=%s&country=US&q=lego+%d&alt=json' % (myAPIstr, setNum)
pg = urllib.request.urlopen(searchURL)
retDict = json.loads(pg.read())
for i in range(len(retDict['items'])):
try:
currItem = retDict['items'][i]
if currItem['product']['condition'] == 'new':
newFlag = 1
else: newFlag = 0
listOfInv = currItem['product']['inventories']
for item in listOfInv:
sellingPrice = item['price']
if sellingPrice > origPrc * 0.5:
print ("%d\t%d\t%d\t%f\t%f" % (yr,numPce,newFlag,origPrc, sellingPrice))
retX.append([yr, numPce, newFlag, origPrc])
retY.append(sellingPrice)
except: print ('problem with item %d' % i)
def setDataCollect(retX, retY):
searchForSet(retX, retY, 8288, 2006, 800, 49.99)
searchForSet(retX, retY, 10030, 2002, 3096, 269.99)
searchForSet(retX, retY, 10179, 2007, 5195, 499.99)
searchForSet(retX, retY, 10181, 2007, 3428, 199.99)
searchForSet(retX, retY, 10189, 2008, 5922, 299.99)
searchForSet(retX, retY, 10196, 2009, 3263, 249.99)
"""
def scrapePage(inFile,outFile,yr,numPce,origPrc):
fr = open(inFile,encoding = 'utf-8'); fw=open(outFile,'a') #a is append mode writing
soup = BeautifulSoup(fr.read())
i=1
currentRow = soup.findAll('table', r="%d" % i)
while(len(currentRow)!=0):
title = currentRow[0].findAll('a')[1].text
lwrTitle = title.lower()
if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1):
newFlag = 1.0
else:
newFlag = 0.0
soldUnicde = currentRow[0].findAll('td')[3].findAll('span')
if len(soldUnicde)==0:
print ("item #%d did not sell" % i)
else:
soldPrice = currentRow[0].findAll('td')[4]
priceStr = soldPrice.text
priceStr = priceStr.replace('$','') #strips out $
priceStr = priceStr.replace(',','') #strips out ,
if len(soldPrice)>1:
priceStr = priceStr.replace('Free shipping', '') #strips out Free Shipping
print ("%s\t%d\t%s" % (priceStr,newFlag,title))
fw.write("%d\t%d\t%d\t%f\t%s\n" % (yr,numPce,newFlag,origPrc,priceStr))
i += 1
currentRow = soup.findAll('table', r="%d" % i)
fw.close()
def setDataCollect(outFile):
scrapePage('setHtml\lego8288.html',outFile, 2006, 800, 49.99)
scrapePage('setHtml\lego10030.html',outFile, 2002, 3096, 269.99)
scrapePage('setHtml\lego10179.html',outFile, 2007, 5195, 499.99)
scrapePage('setHtml\lego10181.html',outFile, 2007, 3428, 199.99)
scrapePage('setHtml\lego10189.html',outFile, 2008, 5922, 299.99)
scrapePage('setHtml\lego10196.html',outFile, 2009, 3263, 249.99)
#加载数据
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t'))-1
xMat = [];yMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
xMat.append(lineArr)
yMat.append(float(curLine[-1]))
return xMat, yMat
#计算最佳拟合直线
#w的最优解的表达式:w=(X.T*X).I*(X.T*y)
def standRegres(xArr,yArr):
xMat = mat(xArr); yMat = mat(yArr).T
xTx = xMat.T*xMat
#若矩阵的行列式不为零,则该矩阵一定可逆
#Numpy中的linalg库中的det()方法可以计算矩阵的行列式
if linalg.det(xTx) == 0.0:
print("This matrix is singular, cannot do inverse")
return
#矩阵A.I代表求矩阵A的逆矩阵
ws = xTx.I *(xMat.T * yMat)
return ws
#岭回归
#给定lambda,计算回归系数
def ridgeRegres(xMat,yMat,lam=0.2):
xTx = xMat.T * xMat #shape(xTx): (8, 8) shape(xMat): (4177, 8)
denom = xTx + eye(shape(xMat)[1])*lam #shape(denom): (8, 8)
#因为当lam=0时,可能出现问题,所以,仍需要检查行列式是否为0
if linalg.det(denom) == 0.0:
print("This matrix is singular, cannot do inverse")
return
##下面函数在使用yMat时,对其进行的转置,因此,这里不需要转置
ws = denom.I * (xMat.T * yMat) #shape(yMat): (1, 4177)
return ws
#在一组lambda上测试结果
def ridgeTest(xArr,yArr):
xMat = mat(xArr);yMat = mat(yArr).T
yMean = mean(yMat,axis=0)
#标准化处理(归一化处理),使得每维特征具有相同的重要性
#归一化公式是:x=(x-mean)/var,最终X符合正态分布
yMat = yMat-yMean
xMeans = mean(xMat)
xVar = var(xMat,0)
xMat = (xMat-xMeans)/xVar
numTestPts = 30
wMat = zeros((numTestPts,shape(xMat)[1]))
for i in range(numTestPts):
ws = ridgeRegres(xMat,yMat,exp(i-10))
wMat[i,:]=ws.T
return wMat
#定义函数,用于分析预测误差的大小
def rssError(yArr,yHat):
return ((yArr-yHat)**2).sum()
#交叉验证测试岭回归 ##numVal:交叉验证的次数
def crossValidation(xArr,yArr,numVal=10):
m = len(yArr)
indexList = list(range(m))
#创建numVal*30的误差矩阵
##30的由来:ridgeTest()使用了30个不同的lambda值来创建不同的回归系数,即numTestPts = 30
errorMat = zeros((numVal,30))
for i in range(numVal):
#创建测试集和训练集容器
trainX=[]; trainY=[]
testX = []; testY = []
#打乱索引顺序,实现随机选取训练集和测试集数据点
random.shuffle(indexList)
#90%训练+10%测试
for j in range(m):
if j < m*0.9:
trainX.append(xArr[indexList[j]])
trainY.append(yArr[indexList[j]])
else:
testX.append(xArr[indexList[j]])
testY.append(yArr[indexList[j]])
wMat = ridgeTest(trainX,trainY) #获得30组ws向量
for k in range(30):
matTestX = mat(testX); matTrainX=mat(trainX)
#用训练集参数将测试集数据标准化
meanTrain = mean(matTrainX,0)
varTrain = var(matTrainX,0)
matTestX = (matTestX-meanTrain)/varTrain
yEst = matTestX * mat(wMat[k,:]).T + mean(trainY)
errorMat[i,k]=rssError(yEst.T.A,array(testY))
#print errorMat[i,k]
#计算不同岭回归ws下errorMat的平均值,观察平均性能 #meanErrors:1*30矩阵
meanErrors = mean(errorMat,0)
minMean = float(min(meanErrors))
#nonzero(meanErrors==minMean)返回的是误差最小的索引,因此bestWeights为误差最小的那个w向量
bestWeights = wMat[nonzero(meanErrors==minMean)]
#岭回归使用了数据标准化,而standRegres没有,为了比较可视化,因此需要将数据还原
#标准化后 Xreg = (x-meanX)/var(x),预测y=Xreg*w+meanY
#因此,利用未标准化的x来计算y= x*w/var(x) - meanX*w/var(x) +meanY
#其中unReg=w/var
xMat = mat(xArr); yMat=mat(yArr).T
meanX = mean(xMat,0); varX = var(xMat,0)
unReg = bestWeights/varX
#print ("the best model from Ridge Regression is:\n",unReg)
#特别注意这里的sum函数,一定是np.sum,因为一般的sum只能对list求和,而这里的参数是matrix
#print ("with constant term: ",-1*np.sum(multiply(meanX,unReg)) + mean(yMat))
yHat=xMat*unReg.T-1*np.sum(multiply(meanX,unReg)) + mean(yMat)
return yHat
#测试
if __name__ == "__main__":
setDataCollect('result.txt')
xMat, yMat = loadDataSet('result.txt')
#print(shape(xMat))
#print(shape(yMat))
#插入一列X0=1
xMat1=np.insert(xMat,0,values = ones((1,63)) ,axis=1)
#确认一下数据是否插入成功
print(xMat[0])
print(xMat1[0])
#比较两种方法的效果
ws = standRegres(xMat1,yMat)
yHat = crossValidation(xArr,yArr,numVal=10) print("标准回归:",xMat1[0]*ws)
print("岭回归:",yHat[0])结果显示:
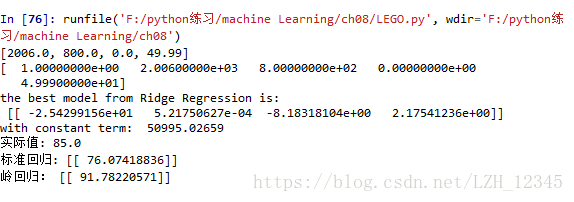

相关文章推荐
- 机器学习实战——ch8.2 回归之预测乐高玩具价格
- 计算广告学习笔记 4.6竞价广告系统-点击率预测与逻辑回归
- 【机器学习实战】第8章 预测数值型数据:回归
- 《机器学习实战》学习笔记---Logister回归
- logistic回归算法学习笔记-从疝气症预测病马死亡率
- 【机器学习实战】第8章 预测数值型数据:回归(Regression)
- 《机器学习实战》和Udacity的ML学习笔记之线性回归
- 《机器学习实战》学习笔记-[10]-回归-岭回归
- 《机器学习实战》第九章学习笔记(分类树回归CART)
- 【学习笔记】用SAS做回归预测和区间预测
- 《机器学习实战》学习笔记-[9]-回归-加权最小二乘LWLR
- 《机器学习实战》学习笔记-[12]-回归-树回归
- 《机器学习实战》学习笔记-[8]-回归-普通最小二乘OLS
- 机器学习-学习笔记2-监督学习中回归方程的建立以及预测
- 代码注释:机器学习实战第8章 预测数值型数据:回归
- tensorflow学习笔记四——回归预测
- 《机器学习实战》笔记(第二部分 利用回归预测数值型数据)
- 《机器学习实战》笔记之八——预测数值型数据:回归
- Spark学习笔记——房屋价格预测
- 机器学习实战——ch8.2 回归之预测乐高玩具价格