近期学习内容
2018-05-04 21:57
42 查看
LR:它是一种二分类算法,取值只能为0或1。 它的函数:
=%5Cfrac%7B1%7D%7B1+e%5E%7B-%5Ctheta&space;%5ETx%7D%7D) 对应的损失函数:
对应的损失函数:
=-%5Cfrac%7B1%7D%7Bm%7D%5Cleft&space;%5B&space;%5Csum_%7Bi=1%7D%5E%7Bm%7Dy%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7Dlog%5C;&space;h_%5Ctheta%5Cleft&space;(&space;x%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D&space;%5Cright&space;)+%5Cleft&space;(&space;1-y%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D&space;%5Cright&space;)log%5C;&space;%5Cleft&space;(&space;1-h_%5Ctheta%5Cleft&space;(&space;x%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D&space;%5Cright&space;)&space;%5Cright&space;)&space;%5Cright&space;%5D) 它会有俩个概率
它会有俩个概率
softmax:它是LR的扩展,能进行多分类问题。他可以有多个值,但所有的结果加起来等于1。%7D&space;%5Cright&space;)=%5Cbegin%7Bpmatrix%7D&space;P%5Cleft&space;(&space;y%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D=1%5Cmid&space;x%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D;%5Ctheta&space;%5Cright&space;)%5C%5C&space;P%5Cleft&space;(&space;y%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D=2%5Cmid&space;x%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D;%5Ctheta&space;%5Cright&space;)%5C%5C&space;%5Ccdots&space;%5C%5C&space;P%5Cleft&space;(&space;y%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D=k%5Cmid&space;x%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D;%5Ctheta&space;%5Cright&space;)&space;%5Cend%7Bpmatrix%7D=%5Cfrac%7B1%7D%7B%5Csum_%7Bj=1%7D%5E%7Bk%7De%5E%7B%5Ctheta&space;_j%5ETx%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D%7D%7D%5Cbegin%7Bbmatrix%7D&space;e%5E%7B%5Ctheta&space;_1%5ETx%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D%7D%5C%5C&space;e%5E%7B%5Ctheta&space;_2%5ETx%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D%7D%5C%5C&space;%5Ccdots&space;%5C%5C&space;e%5E%7B%5Ctheta&space;_k%5ETx%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D%7D&space;%5Cend%7Bbmatrix%7D)
此时的损失函数:=-%5Cfrac%7B1%7D%7Bm%7D%5Cleft&space;%5B&space;%5Csum_%7Bi=1%7D%5E%7Bm%7D%5Csum_%7Bj=1%7D%5E%7Bk%7DI%5Cleft&space;%5C%7B&space;y%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D=j&space;%5Cright&space;%5C%7Dlog%5C;&space;%5Cfrac%7Be%5E%7B%5Ctheta&space;_j%5ETx%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D%7D%7D%7B%5Csum_%7Bl=1%7D%5
7ff7
E%7Bk%7De%5E%7B%5Ctheta&space;_l%5ETx%5E%7B%5Cleft&space;(&space;i&space;%5Cright&space;)%7D%7D%7D&space;%5Cright&space;%5D)
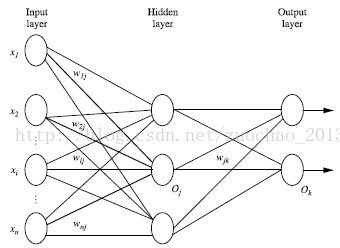
神经网络:它分为输入层(Input layer),隐藏层(Hidden layer),输出层(Output layer)三个部分。 输入层是由训练集的实际特征向量传入。经过连接点的权重一层一层传入,上一层的输出是下一层的输入,经过隐藏层的处理,最后输出。
 梯度爆炸:梯度爆炸是指机器学习时,选择的学习率设置不合理,导致梯度值过大引起。
梯度爆炸:梯度爆炸是指机器学习时,选择的学习率设置不合理,导致梯度值过大引起。
softmax:它是LR的扩展,能进行多分类问题。他可以有多个值,但所有的结果加起来等于1。
此时的损失函数:
神经网络:它分为输入层(Input layer),隐藏层(Hidden layer),输出层(Output layer)三个部分。 输入层是由训练集的实际特征向量传入。经过连接点的权重一层一层传入,上一层的输出是下一层的输入,经过隐藏层的处理,最后输出。
梯度爆炸:梯度爆炸是指机器学习时,选择的学习率设置不合理,导致梯度值过大引起。梯度消失:为什么会出现梯度消失的现象呢?因为通常神经网络所用的激活函数是sigmoid函数,这个函数有个特点,就是能将负无穷到正无穷的数映射到0和1之间,并且对这个函数求导的结果是f(x)=f(x)(1-f(x))因此两个0到1之间的数相乘,得到的结果就会变得很小了。神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重没有更新,这就是梯度消失。
正则化:正则化的目的:防止过拟合!正则化的本质:约束(限制)要优化的参数。正则化看着名字挺复杂,其实说它是限制化也不错感觉。池化:最常见的池化操作为平均池化mean pooling和最大池化max pooling:
平均池化:计算图像区域的平均值作为该区域池化后的值。
最大池化:选图像区域的最大值作为该区域池化后的值。

相关文章推荐
- 近期需要学习的内容
- java基础近期学习的内容总结2。
- java基础近期学习的内容总结1。
- 近期学习内容
- 近期学习内容
- 近期需要学习的内容
- 近期需要学习并且形成成果的内容
- Python是近期学习的主要内容。
- 近期学习方向和内容!
- 近期准备学习的内容
- 近期学习内容for mobile
- [置顶] 近期将要学习的内容(flag)
- 近期学习内容(2006年下)
- 近期要学习内容记录
- 近期要学习的内容
- 【Android学习之道】 四大组件之ContentProvider内容提供器
- web前端开发的学习内容:致那些有意学习web前端开发的人
- Android json解析有关内容学习笔记
- 2017学习内容
- EtherCAT学习笔记:EEPROM存储内容结构(从站配置信息接口SII)