爬取BBC评选21世纪电影TOP100
水利dog自学python之爬虫初体验目标:爬取"bbc评选21世纪电影TOP100"电影信息url 链接:http://movie.mtime.com/list/1449.html技术路线: requests-bs4-xlwt库基本思路:通过requests库获取html内容,通过BeautifulSoup库对html进行解析。理解html树形标签,通过find_all()以及find()方法提取电影相关内容。通过xlwt库将数据输出到excel文件。通过url拼接处理翻页。定义三个函数。分别是获取网页内容getHTMLText();对网页进行解析并提取电影信息的parse_html();以及主函数main()先导入相关库,主要用到requests库,BeautifulSoup库以及xlwt库
'''获取时光网BBS评选的TOP100'''
import requests
from bs4 import BeautifulSoup
import xlwt
START_URL='http://movie.mtime.com/list/1449'
wbk = xlwt.Workbook() #创建一个excel工作簿
sheet = wbk.add_sheet('sheet1') #创建一个sheet
n=1 #全局变量n 用于控制输出到excel时换行1.getHTMLText()函数。通过requests库获取网页内容,采用try-except形式的固定模板:def getHTMLText(url): try: r = requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return ""2.parse_html()函数通过BeautifulSoup()库解析网页内容。首先打开要解析的url链接,通过F12观察html树形结构。发现每部电影信息都包含在dd标签下。每一页有10个dd标签,对应10部电影。
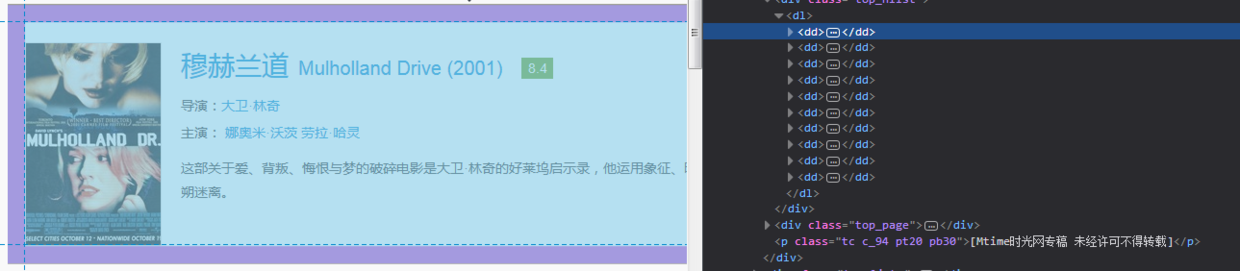
打开<dd>标签观察具体结构。可以看到<dd>标签下包含了<div>标签,标签下还包含了<a>标签,<h3>标签等。其中电影中文名在<h3>标签下<a>标签内,英文名在<a>标签内的<i>标签内。在<div>标签内还有三个并列的<p>标签,分别对应了电影的导演,主演以及简介。
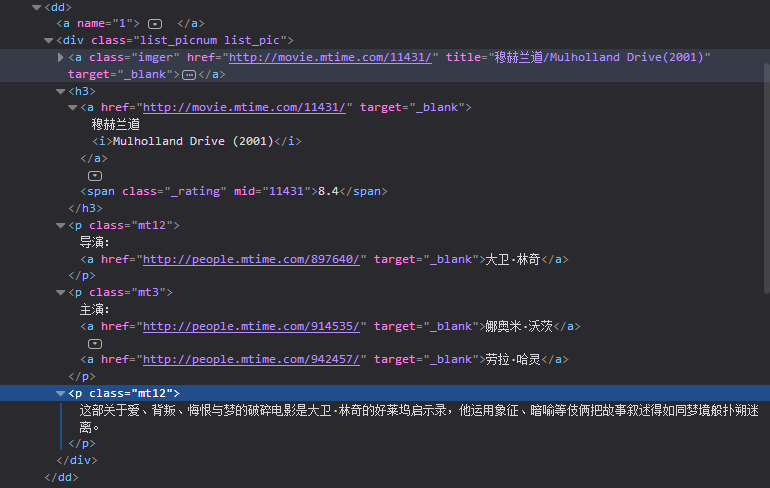
理解了电影的各项内容在标签中的位置以及各标签的关系就可以通过BeautifulSoup库中的find_all()以及find()方法进行标签定位查找,提取相关信息。需要注意的是find_all()方法返回的是一个标签列表,类型是Resultset,不能对find_all()方法提取.attrs等操作。find()方法返回的是满足查找条件的第一个标签。如find('a'),则遇到第一个<a>标签即返回,后续若还有a标签则差找不到,要找到所有的<a>标签应该采用find_all('a'),返回的是包含所有的<a>标签的列表。若照找到第一个<a>标签,可以find_all('a')[0],表示取列表的第一个元素。
def parse_html(html):
global n #要对全局变量进行修改需要采用global关键字
soup = BeautifulSoup(html,'html.parser') #对html页面进行解析
tag_div = soup.find('div',attrs ={'class':'top_nlist'}) #获取属性名为top_nlist的div标签
tags_dd = tag_div.find_all('dd') #每一页10部电影,每部电影信息储存在dd标签下,获取dd便签列表
for dd in tags_dd:
div = dd.find('div',attrs={'class':'list_picnum list_pic'})
h3=div.find('h3')
nameMixed = h3.find('a')
nameEnglish = nameMixed.find('i').extract().string #获取英文名 英文名在a标签下的i标签内通过extract()函数进行抽取
nameChinese = nameMixed.string #获取中文名 将i标签内英文名抽取后,可以获取a标签内的中文名
director = div.find('p',attrs={'class':'mt12'}).find('a').getText()#导演名
protagonist1 = div.find('p',attrs={'class':'mt3'}).find_all('a')[0].string#第一个主演名
protagonist2 = div.find('p',attrs={'class':'mt3'}).find_all('a')[1].string#第二个主演名
protagonists = protagonist1 + ' ' + protagonist2 #每部电影两个主演,将他们放在一起
description = div.find_all('p',attrs={'class':'mt12'})[-1].getText()#描述 电影的描述位于div标签下的最后一个p标签内所以用[-1]
rating=h3.span._rating #获取评分 查询源代码发现其评分被影藏,且class='rating none'
sheet.write(n,0,nameChinese) #写入excel中,第n行第0列中文名
sheet.write(n,1,nameEnglish) #英文名
sheet.write(n,2,rating) #评分(暂时为空)
sheet.write(n,3,director) #d导演
sheet.write(n,4,protagonists) #主演
sheet.write(n,5,description) #电影简介
wbk.save('times.xls') #保存表格
n=n+1代码第35-42行将内容输出到excel文件中。注意excel文件中的行列均需要从0开始。采用一个变量n来控制输出到excel中时的换行。由于自始至终n都是递增的,将n设置为全局变量。采用global关键字,可以对全局变量进行修改操作。3.main()函数用处前期处理,以及翻页操作观察页面发现,第一页url链接为:http://movie.mtime.com/list/1449.html;第二页为http://movie.mtime.com/list/1449-2.html;第三页为http://movie.mtime.com/list/1449-3.html因此除了第一页之外,每一个页面的url链接都是通过 http://movie.mtime.com/list/1449 +“-”+“第几页”+“.html”组成或者说从第二页开始,都是在第一页基础上拼接而成的。可以将前半部分链接设置为常量START_URL='http://movie.mtime.com/list/1449'通过一个循环拼接每一个页面的url
def main(): url=START_URL+'.html' #url拼接 sheet.write(0,0,'中文名') sheet.write(0,1,'英文名') sheet.write(0,2,'评分') sheet.write(0,3,'导演') sheet.write(0,4,'主演') sheet.write(0,5,'简介') html=getHTMLText(url) parse_html(html) #for循环处理翻页问题,一共11页,从第二页开始拼接 for i in range(2,12): url = START_URL+'-'+str(i)+'.html' html = getHTMLText(url) parse_html(html) if __name__ == '__main__': main()一共只有12页,定义range(2,12),从第二页开始拼接,并将拼接好的url传递给相关函数,获取html内容,对html进行解析。对第一页可以进行单独处理。
输出结果样式为

可以看到评分这一项并没有显示出来。
通过F12查看元素评分在<h3>—<a>—<span>标签下
<span class="_rating" mid="11431">8.4</span>打开源代码发现变成了<span class="_rating none" mid="11431"></span>在源代码中并没有评分项。且class属性为“_rating none”,导致通过源代码提取标签内容为空。如何处理目前尚未解决。可能的情况是该评分是通过js加载完成的,不在源代码中,爬取静态页面不起作用。需要考虑如何爬取加载后的页面。
完整代码如下:
'''获取时光网BBS评选的TOP100'''
import requests
from bs4 import BeautifulSoup
import xlwt
START_URL='http://movie.mtime.com/list/1449'
wbk = xlwt.Workbook() #创建一个excel工作簿
sheet = wbk.add_sheet('sheet1') #创建一个sheet
n=1 #全局变量n 用于控制输出到excel时换行
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def parse_html(html):
global n #要对全局变量进行修改需要采用global关键字
soup = BeautifulSoup(html,'html.parser') #对html页面进行解析
tag_div = soup.find('div',attrs ={'class':'top_nlist'}) #获取属性名为top_nlist的div标签
tags_dd = tag_div.find_all('dd') #每一页10部电影,每部电影信息储存在dd标签下,获取dd便签列表
for dd in tags_dd:
div = dd.find('div',attrs={'class':'list_picnum list_pic'})
h3=div.find('h3')
nameMixed = h3.find('a')
nameEnglish = nameMixed.find('i').extract().string #获取英文名 英文名在a标签下的i标签内通过extract()函数进行抽取
nameChinese = nameMixed.string #获取中文名 将i标签内英文名抽取后,可以获取a标签内的中文名
director = div.find('p',attrs={'class':'mt12'}).find('a').getText()#导演名
protagonist1 = div.find('p',attrs={'class':'mt3'}).find_all('a')[0].string#第一个主演名
protagonist2 = div.find('p',attrs={'class':'mt3'}).find_all('a')[1].string#第二个主演名
protagonists = protagonist1 + ' ' + protagonist2 #每部电影两个主演,将他们放在一起
description = div.find_all('p',attrs={'class':'mt12'})[-1].getText()#描述 电影的描述位于div标签下的最后一个p标签内所以用[-1]
rating=h3.span._rating #获取评分 查询源代码发现其评分被影藏,且class='rating none'
sheet.write(n,0,nameChinese) #写入excel中,第n行第0列中文名
sheet.write(n,1,nameEnglish) #英文名
sheet.write(n,2,rating) #评分(暂时为空)
sheet.write(n,3,director) #d导演
sheet.write(n,4,protagonists) #主演
sheet.write(n,5,description) #电影简介
wbk.save('times.xls') #保存表格
n=n+1
def main():
url=START_URL+'.html' #url拼接
sheet.write(0,0,'中文名')
sheet.write(0,1,'英文名')
sheet.write(0,2,'评分')
sheet.write(0,3,'导演')
sheet.write(0,4,'主演')
sheet.write(0,5,'简介')
html=getHTMLText(url)
parse_html(html)
#for循环处理翻页问题,一共11页,从第二页开始拼接
for i in range(2,12):
url = START_URL+'-'+str(i)+'.html'
html = getHTMLText(url)
parse_html(html)
if __name__ == '__main__':
main()遗留问题:1.
nameMixed.find('i').extract().stringextract()函数不太能理解2. <tag>.string与<tag>.getText()函数区别
3.如何爬取加载后的页面获取电影评分
以上三个问题还请网友指点。
阅读更多
- Python 爬取 猫眼 top100 电影例子
- 转发 2013豆瓣电影【口碑榜】Top100
- 亚洲最佳电影TOP100出炉 你看过几部?
- 亚洲最佳电影TOP100出炉 你看过几部?
- python 爬虫项目-爬取猫眼top100电影
- 一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
- 爬取猫眼TOP100的电影信息 urllib+mongdb
- 2016最受欢迎国产开源软件评选,2016 年度开源中国新增开源软件排行榜 TOP 100
- Python爬虫,用于抓取豆瓣电影Top前100的电影的名称
- 3、计数排序,电影top100
- 【Python简单爬虫设计】对豆瓣TOP100的电影名及简要的爬取
- Re+Selenium新手爬取猫眼Top 100
- 【MRO】麦思博:MSUP2017 TOP 100 全球经典案例 -《江泽浩:基于物联网智能分析的设备预测性维护》
- 全球最强人工智能创新公司Top100榜单重磅发布!
- 四六级词汇查询频率top100,你不认识多少?
- 精彩开发网站TOP100(持续更新中!)
- MapReducer 求Top key 100最大值
- 爬取某电影网站排名前100的电影
- 科幻-奇幻小说TOP100
- 08年TOP100