scikit-learn机器学习(六)--朴素贝叶斯分类原理及python实现
2018-04-04 22:54
537 查看
朴素贝叶斯分类原理:
关于贝叶斯定理,参考上一篇博客:scikit-learn机器学习(五)–条件概率,全概率和贝叶斯定理及python实现
贝叶斯分类,个人理解,通俗的说:
假设各个特征之间都是独立存在的,根据这些特征来判断一个事件所属的类别的概率,该事件属于概率最大的类别
给定各个特征的情况下,计算这个事件属于某一类的概率,最大概率即属于该类别
比如结婚的时候嫁人,要考虑长相,性格,身高和上进心,这时一个长得不帅,性格不好,不高收入低的人对你求婚,你考虑嫁给他还是不嫁,这个时候把这个问题转化到数学上就是:
P(嫁|不帅,性格不好,不高,收入低)
但是这个我们没法直接求得,根据贝叶斯定理,我们可以根据三个已知的事件发生概率来求得这个事件发生的概率,
P(嫁|不帅,性格不好,不高,收入低)=P(不帅,性格不好,不高,收入低|嫁)*P(嫁)/P(不帅,性格不好,不高,收入低)
而其他三个概率可以通过样本求得
这个例子具体可参考:
带你搞懂朴素贝叶斯分类算法
数据
我把他的数据重新做了一下: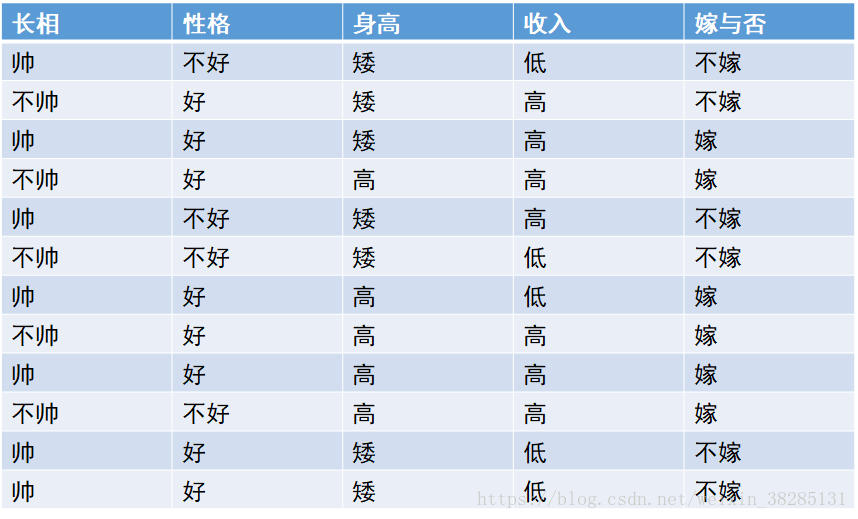
我们需要根据以上数据,来求出要不要嫁给一个不帅,性格不好,个子矮,收入低的男生,
即求出:
P(嫁|不帅,性格不好,不高,收入低)
根据贝叶斯定理,我们就把这个问题拆成了求其他三个概率的问题:
1.P(不帅,性格不好,不高,收入低|嫁)
2.P(嫁)
3.P(不帅,性格不好,不高,收入低)
1)P(不帅,性格不好,不高,收入低|嫁)
这个概率就是在嫁给他的情况下他长得不帅,性格不好,不高,收入低的概率,从数据中我们可以得出
P(不帅,性格不好,不高,没有上进心|嫁)=P(嫁)*P(不帅|嫁)*P(性格不好|嫁)*P(不高|嫁)*P(收入低|嫁)
从数据表中我们可知此事件发生概率为:P1=1/2*1/2*1/6*1/6*1/6
2)P(嫁)
从表中可知P(嫁)=1/2
3)P(不帅,性格不好,不高,收入低)
P(不帅,性格不好,不高,收入低)=P(不帅)*P(性格不好)*P(矮)*P(收入低)
从数据表总我们可知此事件发生的概率为:P2=5/12*1/3*7/12*5/12
根据上述三个概率,我们可得出在四种情况都不好的情况下要不要嫁给他的概率:
P(嫁|不帅,性格不好,不高,收入低)=P1*P(嫁)/P2=0.017
所以这种情况下嫁给他的概率只有0.017,自然是不嫁给他了啊 ,
这种问题就相当于分类了,嫁和不嫁是两种类别,长相,性格,身高,收入就是用于分类的四个特征,我们根据已知数据样本,根据贝叶斯定理,来计
4000
算出给定特征下属于某一类别的概率,这就是贝叶斯分类的原理
python代码实现
1)随机生成一个样本:
import random def create_MarriageData(): looks=['帅','不帅'] characters=['好','不好'] heights=['高','矮'] incomes=['高','低'] marriages=['嫁','不嫁'] datasets=[] for i in range(0,12): dataset = []#创建样本 dataset.append(random.choice(looks))#每个样本随机选择长相 dataset.append(random.choice(characters))#同理,随机选择性格 dataset.append(random.choice(heights))#同理 dataset.append(random.choice(incomes))#同理 dataset.append(random.choice(marriages))#同理 print(dataset) datasets.append(dataset)#将每一组样本加入到样本集中 print(datasets) return datasets create_MarriageData()
结果:

2)计算三个概率
def compute_threeProb(datasets,c1,c2,c3,c4,c5):#数据集,特征1,2,3,4,类别c5
p2_count=0
p1_count=0
p3_count=0
l1=len(datasets)
for dataset in datasets:
if dataset[4]==c5:
p2_count+=1#该类别的数量
if dataset[0]==c1 and dataset[1]== c2 and dataset[2]==c3 and dataset[3]==c4:
p1_count+=1#该类别下满足这四个特征的个数
#计算样本中符合四个特征的数量
if dataset[0] == c1 and dataset[1] == c2 and dataset[2] == c3 and dataset[3] == c4:
p3_count+=1
p1=(p2_count/l1)*(p1_count/p2_count)
p2=p2_count/l1
p3=p3_count/l1
if p3!=0:
prob_marriage=p1*p2/p3
print(prob_marriage)
return prob_marriage
else:
print("这些特征组合不存在!")
return 03)输出结果
datasets=create_MarriageData() compute_threeProb(datasets,c1='帅',c2='不好',c3='矮',c4='低',c5='嫁')
结果如下:
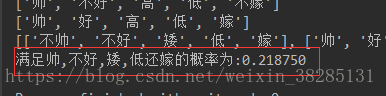
这是我自己随便举的例子,下一篇博客利用机器学习库scikit-learn中的数据集进行计算,看看他们的效果

相关文章推荐
- 机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用
- Python 文本分类:使用scikit-learn 机器学习包进行文本分类
- 机器学习之朴素贝叶斯(NB)分类算法与Python实现
- 机器学习经典算法详解及Python实现---朴素贝叶斯分类及其在文本分类、垃圾邮件检测中的应用
- 机器学习—— 基于朴素贝叶斯分类算法构建文本分类器的Python实现
- 朴素贝叶斯分类算法原理与Python实现与使用方法案例
- Python机器学习:通过scikit-learn实现集成算法
- Python实现基于朴素贝叶斯的垃圾邮件分类 标签: python朴素贝叶斯垃圾邮件分类 2016-04-20 15:09 2750人阅读 评论(1) 收藏 举报 分类: 机器学习(19) 听说
- 用Python Scikit-learn 实现机器学习十大算法--朴素贝叶斯算法(文末有代码)
- 分类算法-----朴素贝叶斯原理和python实现
- Python机器学习:通过scikit-learn实现集成算法
- scikit-learn机器学习(五)--条件概率,全概率和贝叶斯定理及python实现
- Python机器学习 scikit-learn机器学习库
- k-means+python︱scikit-learn中的KMeans聚类实现( + MiniBatchKMeans)
- 基于python的scikit-learn库实现决策树、贝叶斯、K近邻
- windows 64位机器安装python机器学习环境scikit_learn
- python机器学习包 Windows下 pip安装 scikit-learn numpy scipy
- 在win7 32位系统中安装配置Python的机器学习包scikit-learn
- 基于 Python 和 Scikit-Learn 的机器学习介绍
- 朴素贝叶斯分类的Python实现