学习Python爬虫(三):Requests库入门级使用
2018-04-04 20:22
731 查看
之前我们学习了urllib库,那是Python3.x自带的内置库,而本文要介绍的Requests库(在单词后面有个s),是Python的第三方库——此requests非彼request!
包:Python模块的集合
库:这是参考其他语言的用法,可以是包,也可以是模块
这是Requests库的官方网站:Requests库官方文档
1)安装Requests库
2)使用Request库(新手入门级)
导入库
构造对象
调用方法
好简单哦……不急,我们循序渐进
2)Responce对象:包含爬虫返回的所有内容
Responce对象包含服务器返回的所有信息,也包含用户向服务器请求的Request对象的信息
Responce对象的属性:1)
(说明)r.encoding和r.apparent_encoding的区别:前者从HTTP header中的charset字段中解析出饿编码方式,如果没有找到默认为ISO-8859-1编码;后者根据HTTP内容而不是根据头部解析出应该的编码方式,所以当encoding解析不能正确读取时可以尝试用apparent_encoding编码
2)requests.HTTPError:HTTP错误异常
3)requess.URLRequired:URL确实失败
4)requests.ConnectTimeout:连接远程服务器超时异常
5)requests.Timeout:请求URL超时,产生超时异常
源代码
head方法可以用很少的网络流量获得网络资源的概要信息

当我们向URL POST一个字典,会被自动编码提交到FORM字段下
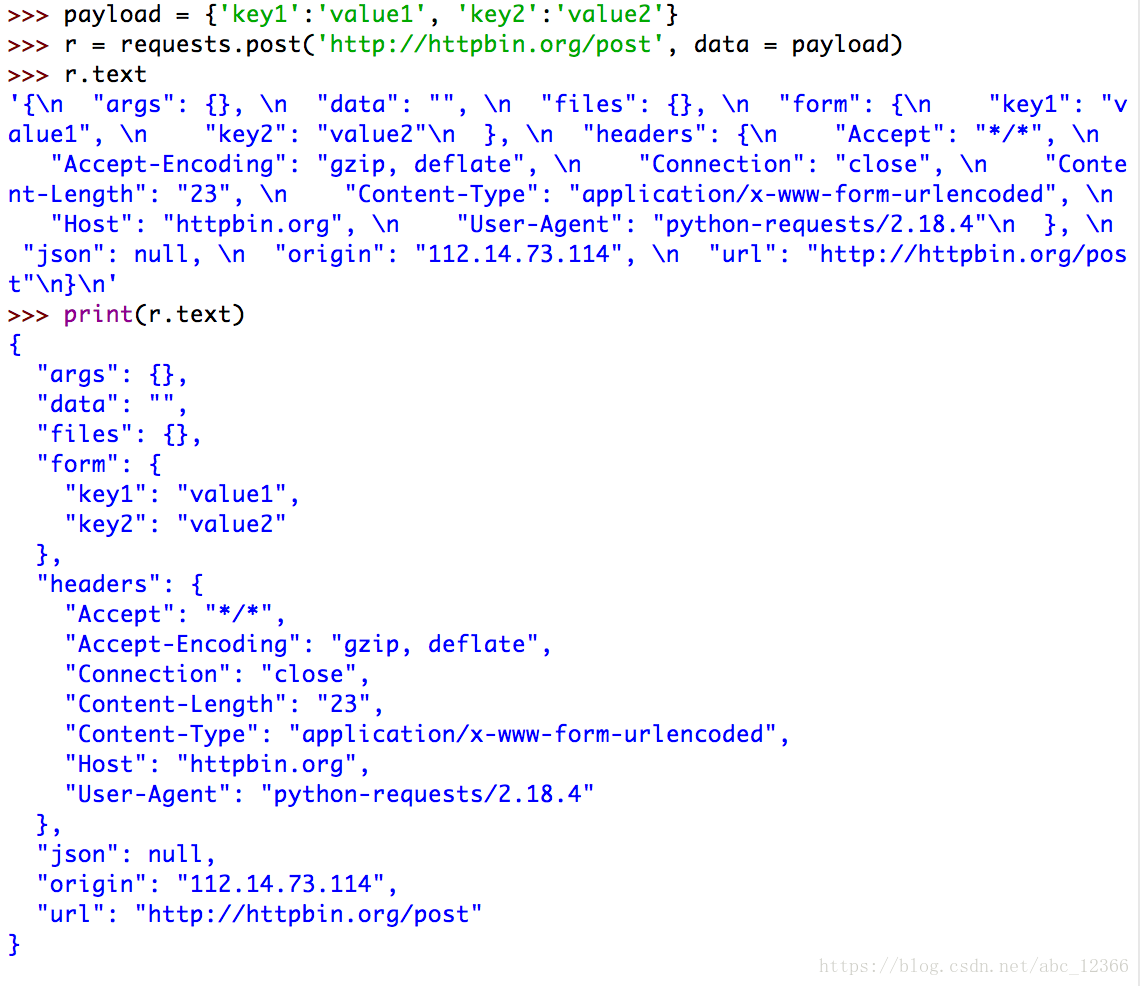
另外,PUT方法和POST方法类似,不过会把原来的数据覆盖掉
1)
构造一个请求,是支撑以下个各种方法的基础方法
2)
4000
获取HTML网页的主要方法,对应HTTP的GET
3)
获取HTML网页的头部信息,对应HTTP的HEAD
4)
向HTML网页提交POST请求,对应HTTP的POST
5)
向HTML网页提交PUT请求,对应HTTP的PUT
6)
向HTML网页提交局部请求,对应HTTP的PATCH
7)
向HTML网页提交删除请求,对应HTTP的DELETE
下面具体讲解上面的方法
看到这里,对前面熟悉的同学就知道了:要模拟一个客户端,我们既可以通过
举栗子

以上的举例,仅仅作为抛砖引玉的作用,具体的操作还得靠自己上机实践,从细节上体验每一个方法的使用;看完本文,希望大家能够熟练掌握GET方法GET方法在requests库中十分常用(在request库中最常使用的就是get方法,入门级掌握 requests.get和requests.head就可以了)
写在前面:库、包、和模块的关系
模块:Python文件包:Python模块的集合
库:这是参考其他语言的用法,可以是包,也可以是模块
Requests库介绍
Requests库是一个Python第三方库,也是目前公认的最好的Python爬虫第三方库这是Requests库的官方网站:Requests库官方文档
1)安装Requests库
pip3 install requests
2)使用Request库(新手入门级)
导入库
import requests
构造对象
>>> r = requests.get('http://www.baidu.com')调用方法
>>> r.status_code 200 >>> r.encoding = 'utf-8' >>> r.text #网页内容
好简单哦……不急,我们循序渐进
Requests库的两个重要对象(通过返回的Responce对象获取信息)
1)Request对象:向服务器请求的对象2)Responce对象:包含爬虫返回的所有内容
Responce对象包含服务器返回的所有信息,也包含用户向服务器请求的Request对象的信息
Responce对象的属性:1)
r.status_code:HTTP请求的返回状态,200表示连接成功,404表示失败(不是200都是请求失败);2)
r.text:HTTP相应内容的字符串形式,即url对应的页面内容;3)
r.encoding:从HTTP header中猜测的相应内容编码方式;4)
r.apparent_encoding:从内容分析出的相应内容编码方式(备选编码方式);5)
r.content:HTTP相应内容的二进制形式——这五点属性非常重要,务必牢记!
(说明)r.encoding和r.apparent_encoding的区别:前者从HTTP header中的charset字段中解析出饿编码方式,如果没有找到默认为ISO-8859-1编码;后者根据HTTP内容而不是根据头部解析出应该的编码方式,所以当encoding解析不能正确读取时可以尝试用apparent_encoding编码
Requests库的异常类型及通用代码框架
1)requests.ConnectionError:网络连接异常,如DNS查询失败、拒绝连接等2)requests.HTTPError:HTTP错误异常
3)requess.URLRequired:URL确实失败
4)requests.ConnectTimeout:连接远程服务器超时异常
5)requests.Timeout:请求URL超时,产生超时异常
import requests def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r,encoding = r.apparent_encoding return r.text except: return "An Exception raised!"
Requests库的方法(简单使用)
前一章讲过,HTTP对网络资源的操作刚好对应Requests库提供的五种方法(不过实际上有更多方法)r. get方法(常用,获取网页HTML信息)
参数requests.get(url, params = None, **kwargs) #url:拟获取页面的url链接;params:url中俄额外参数,字典或字节流格式,可选;**kwargs:12个控制访问的参数
源代码
def get(url, params=None, **kwags):
"""Send a GET request"""
kwargs.setdefault('allow_redirects', True)
return request('get', url, params=params, **kwargs)
"""可以看出requests.get()实际上通过request方法进行封装——事实上,requests库提供的七个方法都是通过requests.request()方法进行的封装"""r. head方法
head方法用于获取网页的头部信息head方法可以用很少的网络流量获得网络资源的概要信息
r. post方法
post方法向服务器提交新增信息当我们向URL POST一个字典,会被自动编码提交到FORM字段下
另外,PUT方法和POST方法类似,不过会把原来的数据覆盖掉
Requests库的方法(request方法详解)
前面讲到,Requests库提供了一些和HTTP对网络资源操作相对应的方法,当然Request库提供的方法还有另外一些……1)
requests.request()
构造一个请求,是支撑以下个各种方法的基础方法
2)
4000
requests.get()
获取HTML网页的主要方法,对应HTTP的GET
3)
requests.head()
获取HTML网页的头部信息,对应HTTP的HEAD
4)
requests.post()
向HTML网页提交POST请求,对应HTTP的POST
5)
requests.put()
向HTML网页提交PUT请求,对应HTTP的PUT
6)
requests.patch()
向HTML网页提交局部请求,对应HTTP的PATCH
7)
requests.delete()
向HTML网页提交删除请求,对应HTTP的DELETE
下面具体讲解上面的方法
requests.request(method, url, **kwargs)
method是请求方式,可选的请求方式有:
GET、
HEAD、
POAT、
PUT、
PATCH、
delete、
OPTIONS,一种七种(服务器和客户端打交道的七种方式)
看到这里,对前面熟悉的同学就知道了:要模拟一个客户端,我们既可以通过
requests.对应方法()来实现,也可以通过
request.request(method=对应方法, url, **kwargs)来实现——那么这两种模拟请求的方式有什么区别呢?区别或者说联系,就是前者是通过后者封装起来的
举栗子
以上的举例,仅仅作为抛砖引玉的作用,具体的操作还得靠自己上机实践,从细节上体验每一个方法的使用;看完本文,希望大家能够熟练掌握GET方法GET方法在requests库中十分常用(在request库中最常使用的就是get方法,入门级掌握 requests.get和requests.head就可以了)

相关文章推荐
- Python爬虫(入门+进阶)学习笔记 1-8 使用自动化神器Selenium爬取动态网页(案例三:爬取淘宝商品)
- Python爬虫(入门+进阶)学习笔记 1-4 使用Xpath解析豆瓣短评
- Python爬虫(入门+进阶)学习笔记 1-3 使用Requests爬取豆瓣短评
- Python爬虫(入门+进阶)学习笔记 1-5 使用pandas保存豆瓣短评数据
- python爬虫学习笔记——使用requests库编写爬虫(1)
- python爬虫学习---Requests库的使用
- python3 爬虫入门(二)requests库基本使用
- python——爬虫学习——requests库的使用-(1)
- python爬虫从入门到放弃(四)之 Requests库的基本使用
- python的nltk中文使用和学习资料汇总帮你入门提高
- Python 爬虫如何入门学习?
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
- [转载]Python爬虫入门三之Urllib库的基本使用
- Python学习 - 使用BeautifulSoup来解析网页一:基础入门
- python小白入门学习笔记-爬虫入门
- python的nltk中文使用和学习资料汇总帮你入门提高
- Python基础学习-爬虫入门知识
- python python 入门学习之网页数据爬虫搜狐汽车数据库
- python的nltk中文使用和学习资料汇总帮你入门提高
- Python爬虫入门六之Cookie的使用