MySQL系列(十三):核心优化----基础
2018-04-04 00:00
246 查看
一、优化层面
存储层:数据表存储引擎选取、字段选取、逆范式(3范式)设计层:索引、分库、分区/分表
架构层:分布式部署(主从/共享)
SQL层:结果一样的情况下,要选择效率高、速度快、节省资源的sql语句执行
Mysql配置文件优化
MySQL优化-----常用技术
二、存储引擎
MySQL存储引擎是数据表存储数据的一种格式。MySQL中的数据是通过各种不同的技术(格式)存储在文件(或者内存)中的。技术和本身的特性就称为存储引擎。使用不同格式存储数据,不同格式的特性也是不一样的。例如Innodb存储引擎支持事务、支持行级锁、支持外键 。
在进行项目开发的时候,要根据自己业务的特点选择适合存储数据的存储引擎。
MyISAM:写入数据非常快,适合写入、读取操作多的系统。如:dedecms、phpcms、discuz等。
InnoDB:适合业务逻辑比较强的系统。如:ecshop、crm、办公系统、商城系统等。
1.MyISAM
① 存储方式
MyISAM数据表的结构、数据、索引分别存储在不同的文件。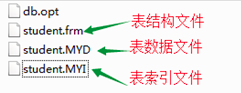
MyISAM支持物理复制、粘贴操作(数据的备份、还原)。
② 数据存入顺序
MyISAM数据的写入顺序与读出顺序保持一致。MyISAM数据表存入数据的时候,不排序,按照写入的顺序进行存储。这样做速度会非常快。
③ 并发性
MyISAM每次有操作都锁住整张数据表,是表锁机制。并发性稍低,并发请求速度稍慢。④ 压缩机制
a)压缩myisampack [选项] 表文件路径
运行myisampack后,必须运行myisamchk以重新创建索引。压缩后的表将会成为只读的,并且myisampack不支持分区表。
b)重建索引
myisamchk -rq 表文件路径
c)解压
压缩的数据表不能再写数据了,因此对数据表进行压缩的时候,一定需要考虑好。
数据不频繁发生变化的数据适合压缩,如全国的邮编信息、用户的收货地址信息。
数据频繁发生变化的就不适合压缩。
对压缩的表进行写操作,要先解压表:
解压的同时,索引会自动重建。
myisamchk --unpack 表文件路径
使用flush可以刷新数据表,自动清除临时文件:
flush table 表名
2.InnoDB
① 存储方式
默认情况下,所有数据库的所有innodb数据表的索引、数据都集合到一个文件,而表结构是单独的一个文件。结构文件:
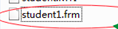
所有数据库的所有InnoDB索引、数据文件:

为每个InnoDB数据表单独设置数据、索引文件:
-- 查看innodb数据表默认数据、索引存储 show variables like 'innodb_file_per_table%'; -- 设置innodb数据表,单独为每个表创建数据、索引文件 set global innodb_file_per_table = 1;
服务器重启之后,innodb_file_per_table的值要归位,不过不影响之前已经创建好的数据表结构。

② 数据存入顺序
Innodb数据表数据的写入顺序与存储的顺序不一致,需要按照主键的顺序把记录摆放到对应的位置上去,速度比Myisam的要稍慢。③ 并发性
InnoDB是行锁,每次只锁住一条记录信息。并发性高,多人同时请求速度快、效率高。3.Memory
内存存储引擎,内部数据运行速度非常快。如果服务器断电,就会清空该存储引擎的全部数据。三、字段选取
1.占空间小字段
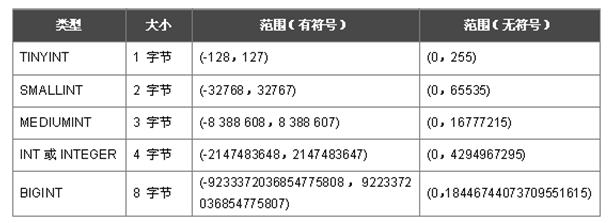
int整型字段的选取:例:
人的年龄适合使用tinyint类型
乌龟的年龄适合使用smallint类型
数据表主键id值在没有超过1600万的时候,就可以使用mediumint类型
2.长度固定字段
varchar:长度:1-65535字节
单字节:近65535个内容,内部保留1-2个字节,保存内容的长度。
汉字:1--2万多汉字(utf-8字符集 3个字节=一个汉字)。
char:
长度:1-255字符
单字节:每个字节等于1个字符
汉字:3个字节等于1个字符
无论单字节内容、汉字都可以存储1-255个.
char() 的运行速度快,如:char(20) 实际存储16个字符,分配20个空间。
varchar()运行速度稍慢,如:varchar(20) 实际存储16个字符,分配16个空间。
例:
手机号码存储:char(11)
存储邮箱:速度快char(40) 、 空间节省 varchar(40)
3.整型存储
整型:时间用整型存储集合:set('篮球','排球','足球','棒球')
枚举:enum('男','女','保密')
ip地址转换为整型存储
建议使用集合、枚举类型,他们底层内部使用的整型进行存储。
IP地址转为整型存储:
mysql: inet_aton(ip) inet_ntoa(数字)
php:ip2long(ip) long2ip(数字)
四、逆范式
数据表的总体设计要遵守三范式,但是有的时候为了整体性能的考虑,需要逆范式设计。会刻意的在某些表中,不去保存另外表的主键(逻辑主键), 而是直接保存想要的数据信,在查询数据的时候,一张表可以直接提供数据,而不需要多表查询(效率较低), 但是会导致数据冗余增加。
五、缓存设置
有的sql语句被频繁执行,比较消耗时间、消耗系统资源,又没有别的优化可做了,并且每次获得数据还不太发生变化,我们把这个sql语句获得信息给缓存起来,供后续执行使用,这样非常节省系统资源。1.具体使用
-- 查看缓存空间 show variables like 'query_cache%'; -- 分配设置缓存空间 set global query_cache_size = 64 * 1024 * 1024; -- 配置文件设置
下次相同的查询会直接从缓存读取。
2.缓存失效
数据表的数据有变化或者数据表结构有变化,则缓存失效。3.何时不使用缓存
sql语句每次获得数据有变化。如:有时间信息、随机数等。4.生成多个缓存
生成缓存的sql语句对空格、大小写比较敏感。相同结果的sql语句,由于空格、大小写问题就会分别生成缓存。5.不使用缓存
-- sql_no_cache select sql_no_cache * from emp where empno = 123;
6.查看缓存空间使用
show status like 'Qcache%';
六、慢查询日志
1.查看参数
show variables like 'slow_query%'; show variables like 'long_query_time';
2.设置配置
全局变量设置:-- set global slow_query_log = 'ON'; set global slow_query_log = 1;
配置文件设置:
[mysqld] slow_query_log = ON slow_query_log_file = /usr/local/mysql/data/slow.log long_query_time = 1
3.慢查询分析工具
pt-query-digestmysqlsla
七、大写入量
例,需要插入一百万条记录信息:方案一:
insert into 表名 values (),(),(),();
分批次分时间把数据写入到数据库中。每次写入1000条,100万的记录,执行1000次insert语句。
时间耗损:
写入数据(1000条)----->为1000条数据维护索引
写入数据(1000条)----->为第2个1000条数据维护索引
......
写入数据(1000条)----->为第1000个1000条数据维护索引
方案二:
方案一时间主要都被维护索引给占据了,如果能减少索引的维护,达到整体运行时间变少更佳(索引维护不需要做1000次,就做一次)。
先把索引给停掉,专门把数据先写入到数据库中,最后在一次性维护索引:
MyISAM表:
a)数据表中已经存在数据(索引已经存在一部分)
alter table 表名 disable keys;
-- 大量写入数据
alter table 表名 enable keys; //最后统一维护索引
b)数据表中没有数据(索引内部没有东西)
alter table 表名 drop primary key ,drop index 索引名称(唯一/普通/全文);
-- 大量写入数据
alter table 表名 add primary key(id),(唯一/全文)index 索引名 (字段);
InnoDB表:
使用事务一次性写入大量sql语句。
start transaction;
-- 大量数据写入(100万条记录信息 insert被执行1000次)
-- 事务内部执行的insert的时候,数据还没有写入到数据库
-- 只有数据真实写入到数据库才会执行"索引"维护
commit;
commit执行完毕后最后会自动维护一次索引。
八、SQL拆分
数据库操作有的时候涉及到连表查询、子查询等操作。复合查询一般要涉及到多个数据表,使sql语句逻辑清晰、简单,但是消耗资源比较多、时间长,不利于数据表的并发处理,因为需要长时间锁住多个表。
SQL拆分:
1.sql语句1
2.sql语句2
......
最后,在语言层面处理通过逻辑代码整合数据
九、limit
1.limit变更为 where与 limit组合:-- 假设empno设置了索引 select * from emp limit 1500000,10; -- where limit select * from emp where empno > 1500001 limit 10;
因为where条件字段使用了索引,执行速度明显加快。
十、order by null
强制不排序,有的sql语句在执行的时候,本身默认会有排序效果。但是有的时候我们的业务不需要排序效果,就可以进行强制限制,节省默认排序带来的资源消耗。例,group by子句会默认根据分组排序:
-- group by 默认根据分组排序 select cate_id,count(*) from goods group by cate_id; -- group by null 强制不排序 select cate_id,count(*) from goods group by cate_id order by bull;
十一、查询优化专题
MYSQL优化-----查询优化
相关文章推荐
- MySQL系列(十四):核心优化----索引
- MySQL 优化系列 --1.基础操作
- java基础巩固系列(十三):java正则表达式中的数量词:Greedy、Reluctant、Possessive
- Javascript基础系列之(八)Javascript的调试与优化
- Mysql系列(六)初学基础
- MySQL优化系列之查询优化
- MySQL查询优化系列讲座之数据类型与效率
- MySQL查询优化系列讲座之查询优化器
- MySQL系列:innodb源码分析之基础数据结构
- MySQL 数据库性能优化之缓存参数优化(这是 MySQL数据库性能优化专题 系列的第一篇文章)
- [MySQL优化案例]系列 -- 频繁创建临时表
- MySQL系列—如何优化你的 SQL SELECT 语句性能
- MySQL多表查询核心优化
- C#基础知识梳理系列十三:线程之美
- MySQL查询优化技术系列讲座之使用索引
- JQuery学习系列(十三)核心
- 【mysql基础系列之二】基本操作
- 数据科学工程师面试宝典系列之四---MySQL基础
- MySQL优化 - 所需了解的基础知识