相关性系数介绍+python代码实现 correlation analysis
2018-04-03 13:34
211 查看
参考文献:
1.python 皮尔森相关系数 https://www.cnblogs.com/lxnz/p/7098954.html
2.统计学之三大相关性系数(pearson、spearman、kendall) http://blog.sina.com.cn/s/blog_69e75efd0102wmd2.html
皮尔森系数
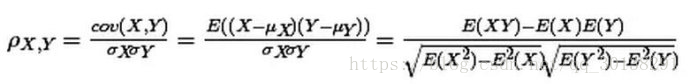
重点关注第一个等号后面的公式,最后面的是推导计算,暂时不用管它们。看到没有,两个变量(X, Y)的皮尔森相关性系数(ρX,Y)等于它们之间的协方差cov(X,Y)除以它们各自标准差的乘积(σX, σY)。
公式的分母是变量的标准差,这就意味着计算皮尔森相关性系数时,变量的标准差不能为0(分母不能为0),也就是说你的两个变量中任何一个的值不能都是相同的。如果没有变化,用皮尔森相关系数是没办法算出这个变量与另一个变量之间是不是有相关性的。
皮尔森相关系数(Pearson correlation coefficient)也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强。
简单的相关系数的分类
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
r描述的是两个变量间线性相关强弱的程度。r的取值在-1与+1之间,若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r 的绝对值越大表明相关性越强,要注意的是这里并不存在因果关系。
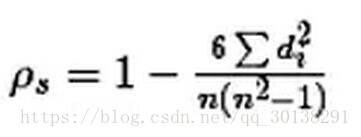
计算过程就是:首先对两个变量(X, Y)的数据进行排序,然后记下排序以后的位置(X’, Y’),(X’, Y’)的值就称为秩次,秩次的差值就是上面公式中的di,n就是变量中数据的个数,最后带入公式就可求解结果
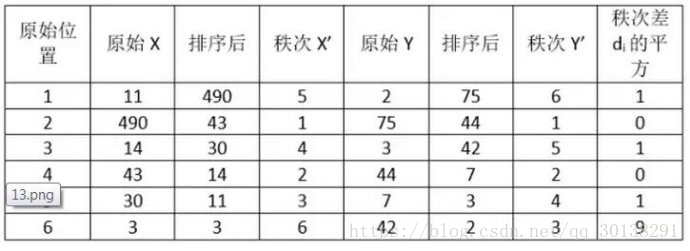
带入公式,求得斯皮尔曼相关性系数:ρs= 1-6*(1+1+1+9)/6*35=0.657
而且,即便在变量值没有变化的情况下,也不会出现像皮尔森系数那样分母为0而无法计算的情况。另外,即使出现异常值,由于异常值的秩次通常不会有明显的变化(比如过大或者过小,那要么排第一,要么排最后),所以对斯皮尔曼相关性系数的影响也非常小!
由于斯皮尔曼相关性系数没有那些数据条件要求,适用的范围就广多了。
分类变量可以理解成有类别的变量,可以分为
无序的,比如性别(男、女)、血型(A、B、O、AB);
有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。
通常需要求相关性系数的都是有序分类变量。
举个例子。比如评委对选手的评分(优、中、差等),我们想看两个(或者多个)评委对几位选手的评价标准是否一致;或者医院的尿糖化验报告,想检验各个医院对尿糖的化验结果是否一致,这时候就可以使用肯德尔相关性系数进行衡量。
DataFrame.corr(method='pearson', min_periods=1)[source]
Compute pairwise correlation of columns, excluding NA/null values
Parameters:
method : {‘pearson’, ‘kendall’, ‘spearman’}
pearson : standard correlation coefficient
kendall : Kendall Tau correlation coefficient
spearman : Spearman rank correlation
min_periods : int, optional
Minimum number of observations required per pair of columns to have a valid result. Currently only available for pearson and spearman correlation
Returns:
y : DataFrameimport pandas as pd
df = pd.DataFrame({'A':[5,91,3],'B':[90,15,66],'C':[93,27,3]})
print(df.corr())
print(df.corr('spearman'))
print(df.corr('kendall'))
df2 = pd.DataFrame({'A':[7,93,5],'B':[88,13,64],'C':[93,27,3]})
print(df2.corr())
print(df2.corr('spearman'))
print(df2.corr('kendall'))
返回Pearson乘积矩相关系数。
cov有关更多详细信息,请参阅文档。相关系数矩阵R和协方差矩阵C之间的关系为
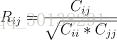
R的值在-1和1之间(含)。
参数:
x:array_like
包含多个变量和观察值的1维或2维数组。x的每一行代表一个变量,每一列都是对所有这些变量的单独观察。另请参阅下面的rowvar。
y:array_like,可选
一组额外的变量和观察。y的形状与x相同。
rowvar:布尔,可选
如果rowvar为True(默认),则每行表示一个变量,并在列中有观察值。否则,该关系将被转置:每列表示一个变量,而行包含观察值。
bias : _NoValue, optional Has no effect, do not use. Deprecated since version 1.10.0.
ddof : _NoValue, optional Has no effect, do not use. Deprecated since version 1.10.0.
返回:
R:ndarray 变量的相关系数矩阵。import numpy as np
vc=[1,2,39,0,8]
vb=[1,2,38,0,8]
print(np.mean(np.multiply((vc-np.mean(vc)),(vb-np.mean(vb))))/(np.std(vb)*np.std(vc)))
#corrcoef得到相关系数矩阵(向量的相似程度)
print(np.corrcoef(vc,vb))
1.python 皮尔森相关系数 https://www.cnblogs.com/lxnz/p/7098954.html
2.统计学之三大相关性系数(pearson、spearman、kendall) http://blog.sina.com.cn/s/blog_69e75efd0102wmd2.html
皮尔森系数
重点关注第一个等号后面的公式,最后面的是推导计算,暂时不用管它们。看到没有,两个变量(X, Y)的皮尔森相关性系数(ρX,Y)等于它们之间的协方差cov(X,Y)除以它们各自标准差的乘积(σX, σY)。
公式的分母是变量的标准差,这就意味着计算皮尔森相关性系数时,变量的标准差不能为0(分母不能为0),也就是说你的两个变量中任何一个的值不能都是相同的。如果没有变化,用皮尔森相关系数是没办法算出这个变量与另一个变量之间是不是有相关性的。
皮尔森相关系数(Pearson correlation coefficient)也称皮尔森积矩相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强。
简单的相关系数的分类
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
r描述的是两个变量间线性相关强弱的程度。r的取值在-1与+1之间,若r>0,表明两个变量是正相关,即一个变量的值越大,另一个变量的值也会越大;若r<0,表明两个变量是负相关,即一个变量的值越大另一个变量的值反而会越小。r 的绝对值越大表明相关性越强,要注意的是这里并不存在因果关系。
spearman correlation coefficient(斯皮尔曼相关性系数)
斯皮尔曼相关性系数,通常也叫斯皮尔曼秩相关系数。“秩”,可以理解成就是一种顺序或者排序,那么它就是根据原始数据的排序位置进行求解,这种表征形式就没有了求皮尔森相关性系数时那些限制。下面来看一下它的计算公式:计算过程就是:首先对两个变量(X, Y)的数据进行排序,然后记下排序以后的位置(X’, Y’),(X’, Y’)的值就称为秩次,秩次的差值就是上面公式中的di,n就是变量中数据的个数,最后带入公式就可求解结果
带入公式,求得斯皮尔曼相关性系数:ρs= 1-6*(1+1+1+9)/6*35=0.657
而且,即便在变量值没有变化的情况下,也不会出现像皮尔森系数那样分母为0而无法计算的情况。另外,即使出现异常值,由于异常值的秩次通常不会有明显的变化(比如过大或者过小,那要么排第一,要么排最后),所以对斯皮尔曼相关性系数的影响也非常小!
由于斯皮尔曼相关性系数没有那些数据条件要求,适用的范围就广多了。
kendall correlation coefficient(肯德尔相关性系数)
肯德尔相关性系数,又称肯德尔秩相关系数,它也是一种秩相关系数,不过它所计算的对象是分类变量。分类变量可以理解成有类别的变量,可以分为
无序的,比如性别(男、女)、血型(A、B、O、AB);
有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。
通常需要求相关性系数的都是有序分类变量。
举个例子。比如评委对选手的评分(优、中、差等),我们想看两个(或者多个)评委对几位选手的评价标准是否一致;或者医院的尿糖化验报告,想检验各个医院对尿糖的化验结果是否一致,这时候就可以使用肯德尔相关性系数进行衡量。
pandas代码实现
pandas.DataFrame.corr()DataFrame.corr(method='pearson', min_periods=1)[source]
Compute pairwise correlation of columns, excluding NA/null values
Parameters:
method : {‘pearson’, ‘kendall’, ‘spearman’}
pearson : standard correlation coefficient
kendall : Kendall Tau correlation coefficient
spearman : Spearman rank correlation
min_periods : int, optional
Minimum number of observations required per pair of columns to have a valid result. Currently only available for pearson and spearman correlation
Returns:
y : DataFrameimport pandas as pd
df = pd.DataFrame({'A':[5,91,3],'B':[90,15,66],'C':[93,27,3]})
print(df.corr())
print(df.corr('spearman'))
print(df.corr('kendall'))
df2 = pd.DataFrame({'A':[7,93,5],'B':[88,13,64],'C':[93,27,3]})
print(df2.corr())
print(df2.corr('spearman'))
print(df2.corr('kendall'))
numpy代码实现
numpy.corrcoef(x,y = None,rowvar = True,bias = <class'numpy._globals._NoValue'>,ddof = <class'numpy._globals._NoValue'> )返回Pearson乘积矩相关系数。
cov有关更多详细信息,请参阅文档。相关系数矩阵R和协方差矩阵C之间的关系为
R的值在-1和1之间(含)。
参数:
x:array_like
包含多个变量和观察值的1维或2维数组。x的每一行代表一个变量,每一列都是对所有这些变量的单独观察。另请参阅下面的rowvar。
y:array_like,可选
一组额外的变量和观察。y的形状与x相同。
rowvar:布尔,可选
如果rowvar为True(默认),则每行表示一个变量,并在列中有观察值。否则,该关系将被转置:每列表示一个变量,而行包含观察值。
bias : _NoValue, optional Has no effect, do not use. Deprecated since version 1.10.0.
ddof : _NoValue, optional Has no effect, do not use. Deprecated since version 1.10.0.
返回:
R:ndarray 变量的相关系数矩阵。import numpy as np
vc=[1,2,39,0,8]
vb=[1,2,38,0,8]
print(np.mean(np.multiply((vc-np.mean(vc)),(vb-np.mean(vb))))/(np.std(vb)*np.std(vc)))
#corrcoef得到相关系数矩阵(向量的相似程度)
print(np.corrcoef(vc,vb))

相关文章推荐
- 深度学习笔记一:BP神经网络的介绍和Python代码实现(1)
- 关于高斯模糊的详细介绍及python代码实现
- 机器学习与神经网络(二):感知器的介绍和Python代码实现
- 深度学习笔记一:BP神经网络的介绍和Python代码实现(2)
- 朴素贝叶斯分类算法介绍及python代码实现案例
- HMM原理介绍 示例 python代码实现
- python kmeans聚类简单介绍和实现代码
- 关于高斯模糊的详细介绍及python代码实现
- 机器学习与神经网络(四):BP神经网络的介绍和Python代码实现
- K-means聚类算法介绍与利用python实现的代码示例
- 机器学习与神经网络(三):自适应线性神经元的介绍和Python代码实现
- 转:PAMIE- Python实现IE自动化的模块(附 网易注册代码)
- python中将阿拉伯数字转换成中文的实现代码
- PAMIE- Python实现IE自动化的模块(附 网易注册代码)
- Python中的文件和目录操作实现代码
- 最近在研究enigma2的代码,那叫个庞大,C/C++写中间件,上层应用全部用python实现,可以学习一下plugin的实现机制了.
- 将C++代码全部写到头文件:)python脚本帮助自动生成相应的实现文件初始框架
- python 定时器具体的使用代码介绍
- Python代码实现Java本地化资源字符串的检查,防止出现空指针异常