Scala基础总结(三)
2018-04-01 15:45
155 查看
Scala总结
抽象类和抽象成员
与java相似,scala中abstract声明的类是抽象类,抽象类不可以被实例化。
在scala中,抽象类和特质中的方法、字段和类型都可以是抽象的。示例如下:
trait MyAbstract {
type T // 抽象类型
def transform(x: T): T // 抽象方法
val initial: T // 抽象val
var current: T // 抽象var
}
抽象方法:抽象方法不需要(也不允许)有abstract修饰符,一个方法只要是没有实现(没有等号或方法体),它就是抽象的。
抽象类型:scala中的类型成员也可以是抽象的。抽象类型并不是说某个类或特质是抽象的(特质本身就是抽象的),抽象类型永远都是某个类或特质的成员。
抽象字段:没有初始化的val或var成员是抽象的,此时你需要指定其类型。抽象字段有时会扮演类似于超类的参数这样的角色,这对于特质来说尤其重要,因为特质缺少能够用来传递参数的构造器。因此参数化特质的方式就是通过在子类中实现抽象字段完成。如对于以下特质:
trait MyAbstract {
val test: Int
println(test)
def show() {
println(test)
}
}
你可以使用如下匿名类语法创建继承自该特质的匿名类的实例,如下:
new MyAbstract {
val test = 1
}.show()
你可以通过以上方式参数化特质,但是你会发现这和“new 类名(参数列表)”参数化一个类实例还是有区别的,因为你看到了对于test变量的两次println(第一次在特质主体中,第二次是由于调用了方法show),输出了两个不同的值(第一次是0,第二次是1)。这主要是由于超类会在子类之前进行初始化,而超类抽象成员在子类中的具体实现的初始化是在子类中进行的。为了解决这个问题,你可以使用预初始化字段和懒值。
预初始化字段:
预初始化字段,可以让你在初始化超类之前初始化子类的字段。预初始化字段用于对象或有名称的子类时,形式如下:class B extends {
val a = 1
} with A
预初始化字段用于匿名类时,形式如下:
new {
val a = 1
} with A
需要注意的是:由于预初始化的字段在超类构造器调用之前被初始化,因此它们的初始化器不能引用正在被构造的对象。
懒值:
加上lazy修饰符的val变量称为懒值,懒值右侧的表达式将直到该懒值第一次被使用的时候才计算。如果懒值的初始化不会产生副作用,那么懒值定义的顺序就不用多加考虑,因为初始化是按需的。
继承与覆盖(override)
继承:
继承时,如果父类主构造器带有参数,子类需要把要传递的参数放在父类名之后的括号里即可,如下:class Second(a: Int, b: Int) extends First(a) {…}
scala继承层级:
如上图所示:Any是所有其他类的超类。Null是所有引用类(继承自AnyRef的类)的子类,Null类型的值为null。Nothing是所有其他类(包括Null)的子类,Nothing类型没有任何值,它的一个用处是它标明了不正常的终止(例如抛出异常,啥也不返回)。AnyVal是scala中内建值类(共9个)的父类。AnyRef是scala中所有引用类的父类,在java平台上AnyRef实际就是java.lang.Object的别名,因此java里写的类和scala里写的类都继承自AnyRef,你可以认为java.lang.Object是scala在java平台上实现AnyRef的方式。scala类与java类的不同之处在于,scala类还继承了一个名为ScalaObject的特别记号特质,目的是想让scala程序执行得更高效。
覆盖:
由于scala里字段和方法属于相同的命名空间,这让字段可以覆盖无参数方法或空括号方法,但反过来好像不可以啊。另外,你也可以用空括号方法覆盖无参数方法,反之亦可。在scala中,若子类覆盖了父类的具体成员则必须带override修饰符;若是实现了同名的抽象成员时则override是可选的;若并未覆盖或实现基类中的成员则禁用override修饰符。特质(trait)
特质相当于接口,不能被实例化。特质定义使用trait关键字,与类相似,你同样可以在其中定义而不仅是声明字段和方法等。你可以使用extends或with将多个特质“混入”类中。注意当在定义特质时,使用extends指定了特质的超类,那么该特质就只能混入扩展了指定的超类的类中。
特质与类的区别在于:①特质不能带有“类参数”,也即传递给主构造器的参数;②不论在类的哪个地方,super调用都是静态绑定的,但在特质中,它们是动态绑定的,因为在特质定义时,尚且不知道它的超类是谁,因为它还没有“混入”,由于在特质中使用super调用超类方法是动态绑定的,因此你需要对特质中相应的方法加上abstract声明(虽然加上了abstract声明,但方法仍可以被具体定义,这种用法只有在特质中有效),以告诉编译器特质中的该方法只有在特质被混入某个具有期待方法的具体定义的类中才有效。你需要非常注意特质被混入的次序:特质在构造时顺序是从左到右,构造器的顺序是类的线性化(线性化是描述某个类型的所有超类型的一种技术规格)的反向。由于多态性,子类的方法最先起作用,因此越靠近右侧的特质越先起作用,如果最右侧特质调用了super,它调用左侧的特质的方法,依此类推。
Ordered特质:
Ordered特质扩展自java的Comparable接口。Ordered特质用于排序,为了使用它,你需要做的是:首先将其混入类中,然后实现一个compare方法。需要注意的是:Ordered并没有为你定义equals方法,因为通过compare实现equals需要检查传入对象的类型,但是因为类型擦除,导致它无法做到。因此,即使继承了Ordered,也还是需要自己定义equals。Ordering特质:
Ordering特质扩展自java的Comparator接口。Ordering特质也用于排序,为了使用它,你需要做的是:定义一个该特质的子类的单独的实例,需要实现其中的compare方法,并将其作为参数传递给排序函数。此乃策略模式也。Application特质:
特质Application声明了带有合适签名的main方法。但是它存在一些问题,所以只有当程序相对简单并且是单线程的情况下才可以继承Application特质。Application特质相对于APP特质来说,有些陈旧,你应该使用更新的APP特质。APP特质:
APP特质同Application特质一样,都提供了带有合适签名的main方法,在使用时只需将它混入你的类中,然后就可以在类的主构造器中写代码了,无需再定义main方法。如果你需要命令行参数,可以通过args属性得到1ca55
。
显式类型转换
正如之前所述的,scala中类型转换使用方法实现,以下是显式类型测试和显式类型转换的示例:
a.isInstanceOf[String] // 显式类型测试
a.asInstanceOf[String] // 显式类型转换
隐式转换、隐式参数
隐式转换:
隐式转换只是普通的方法,唯一特殊的地方是它以修饰符implicit开始,implicit告诉scala编译器可以在一些情况下自动调用(比如说如果当前类型对象不支持当前操作,那么scala编译器就会自动添加调用相应隐式转换函数的代码,将其转换为支持当前操作的类型的对象,前提是已经存在相应的隐式转换函数且满足作用域规则),而无需你去调用(当然如果你愿意,你也可以自行调用)。隐式转换函数定义如下:implicit def functionName(…) = {…}
隐式转换满足以下规则:
作用域规则:scala编译器仅会考虑处于作用域之内的隐式转换。隐式转换要么是以单一标识符的形式(即不能是aaa.bbb的形式,应该是bbb的形式)出现在作用域中,要么是存在于源类型或者目标类型的伴生对象中。
单一调用规则:编译器在同一个地方只会添加一次隐式操作,不会在添加了一个隐式操作之后再在其基础上添加第二个隐式操作。
显式操作先行规则:若编写的代码类型检查无误,则不会尝试任何隐式操作。
隐式参数:
柯里化函数的完整的最后一节参数可以被隐式提供,即隐式参数。此时最后一节参数必须被标记为implicit(整节参数只需一个implicit,并不是每个参数都需要),同时用来提供隐式参数的相应实际变量也应该标记为implicit的。对于隐式参数,我们需要注意的是:① 隐式参数也可以被显式提供;
② 提供隐式参数的实际变量必须以单一标识符的形式出现在作用域中;
③ 编译器选择隐式参数的方式是通过匹配参数类型与作用域内的值类型,因此隐式参数应该是很稀少或者很特殊的类型(最好是使用自定义的角色确定的名称来命名隐式参数类型),以便不会被碰巧匹配;
④ 如果隐式参数是函数,编译器不仅会尝试用隐式值补足这个参数,还会把这个参数当作可用的隐式操作而使用于方法体中。
视界:
视界使用“<%”符号,可以用来缩短带有隐式参数的函数签名。比如,“T <% Ordered[T]”是在说“任何的T都好,只要T能被当作Ordered[T]即可”,因此只要存在从T到Ordered[T]的隐式转换即可。注意视界与上界的不同:上界“T <: Ordered[T”是说T是Ordered[T]类型的。
隐式操作调试:
隐式操作是scala的非常强大的特性,但有时很难用对也很难调试。有时如果编译器不能发现你认为应该可以用的隐式转换,你可以把该转换显式地写出来,这有助于发现问题。
另外,你可以在编译scala程序时,使用“-Xprint:typer”选项来让编译器把添加了所有的隐式转换之后的代码展示出来。
类型参数化
在scala中,类型参数化(类似于泛型)使用方括号实现,如:Foo[A],同时,我们称Foo为高阶类型。如果一个高阶类型有2个类型参数,则在声明变量类型时可以使用中缀形式来表达,此时也称该高阶类型为中缀类型,示例如下:
class Foo[A,B]
val x: Int Foo String = null // Int Foo String 等同于 Foo[Int,String]
与java相似,scala的类型参数化也使用类型擦除实现(类型擦除是很差劲的泛型机制,不过可能是由于java的原因,scala也这样做了),类型擦除的唯一例外就是数组,因为在scala中和java中,它们都被特殊处理,数组的元素类型与数组值保存在一起。在scala中,数组是“不变”的(这点与java不同),泛型默认是“不变”的。
协变、逆变与不变:
拿Queue为例,如果S是T的子类型,那么Queue[S]是Queue[T]的子类型,就称Queue是协变的;相反,如果Queue[T]是Queue[S]的子类型,那么Queue是逆变的;既不是协变又不是逆变的是不变的,不变的又叫严谨的。在scala中,泛型默认是不变的。当定义类型时,你可以在类型参数前加上“+”使类型协变,如Queue[+A]。类似地,你可以在类型参数前加上“-”使类型逆变。在java中使用类型时可以通过使用extends和super来达到协变逆变的目的,它们都是“使用点变型”,java不支持“声明点变型”。而scala中同时提供了声明点变型(“+”和“-”,它们只能在类型定义时使用)和使用点变型(“<:”和“>:”,类似于java中的extends和super,在使用类型时声明)。不管是“声明点变型”还是“使用点变型”,都遵循PECS法则,详见java泛型。需要注意的是:变型并不会被继承,父类被声明为变型,子类若想保持仍需要再次声明。
继承中的协变逆变:
c++、java、scala都支持返回值协变,也就是说在继承层次中子类覆盖超类的方法时,可以指定返回值为更具体的类型。c#不支持返回值协变。允许参数逆变的面向对象语言并不多——c++、java、scala和c#都会把它当成一个函数重载。
更多信息参见java泛型。
集合
scala的集合(collection)库分为可变(mutable)类型与不可变(immutable)类型。以Set为例,特质scala.collection.immutable.Set和scala.collection.mutable.Set都扩展自scala.collection.Set。
scala集合的顶层抽象类和特质:
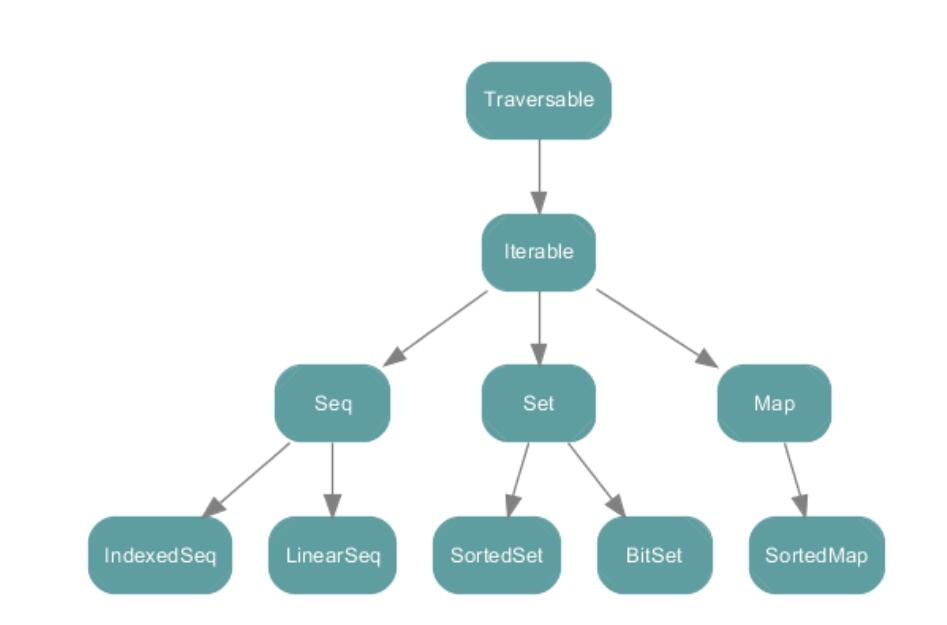
scala.collection.immutable:
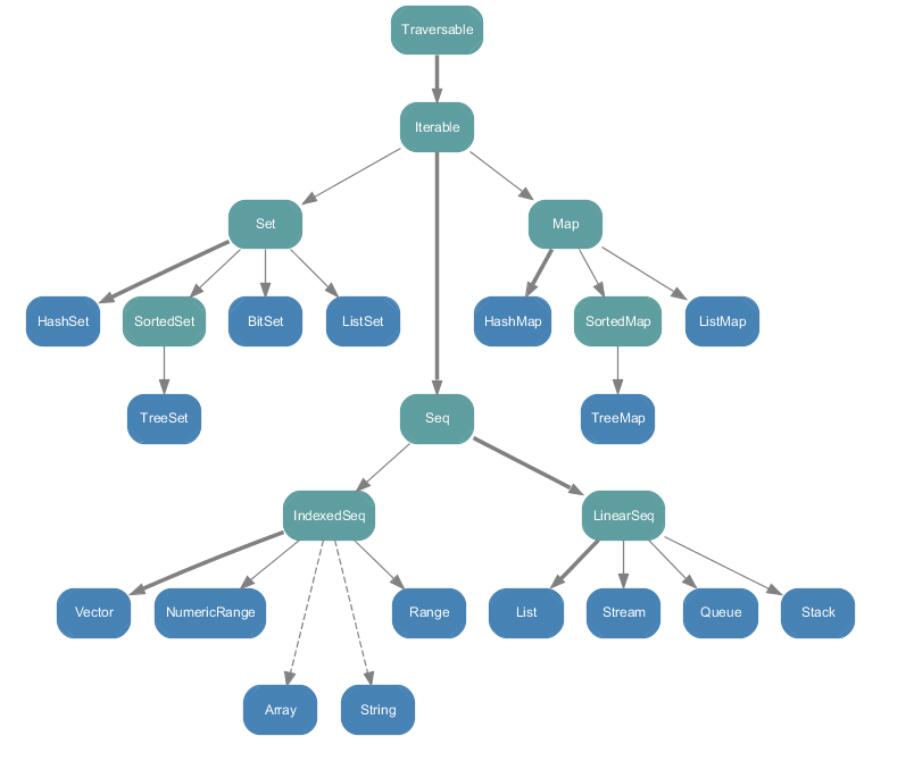
scala.collection.mutable:
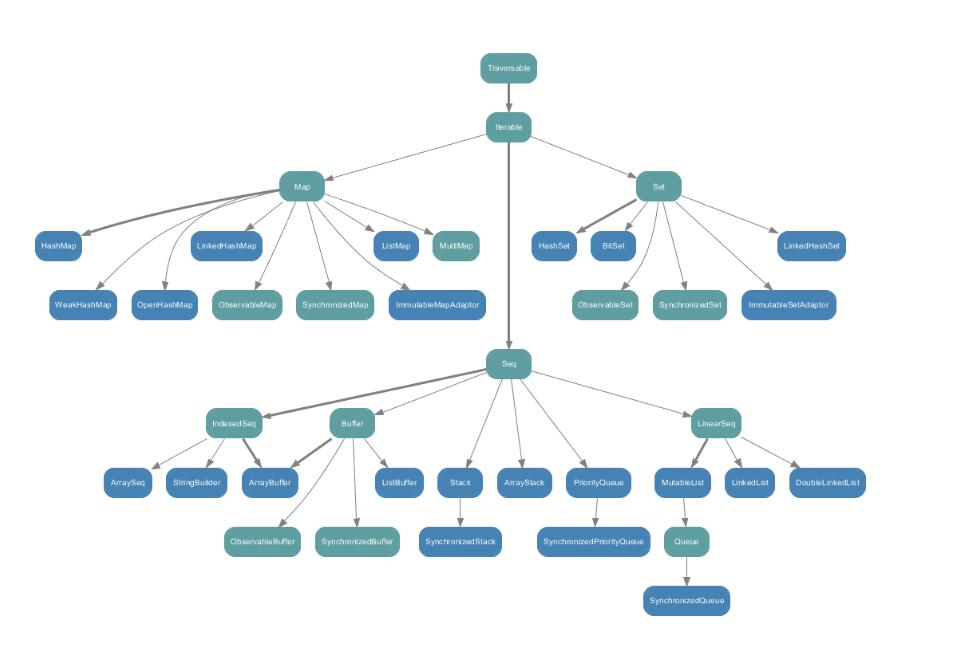
不可变集合与可变集合之间的对应关系:
| 不可变(collection.immutable._) | 可变(collection.mutable._) |
| Array | ArrayBuffer |
| List | ListBuffer |
| String | StringBuilder |
| - | LinkedList, DoubleLinkedList |
| List | MutableList |
| Queue | Queue |
| Array | ArraySeq |
| Stack | Stack |
| HashMap HashSet | HashMap HashSet |
| - | ArrayStack |
Iterable与Iterator:
Iterable是可变和不可变序列、集、映射的超特质。集合对象可以通过调用iterator方法来产生迭代器Iterator。Iterable与Iterator之间的差异在于:前者指代的是可以被枚举的类型,而后者是用来执行枚举操作的机制。尽管Iterable可以被枚举若干次,但Iterator仅能使用一次。数组:
在scala中,数组保存相同类型的元素,其中包含的元素值是可变的。数组也是对象,访问数组使用小括号。在JVM中,scala的数组以java数组方式实现。scala中数组是非协变的。定长数组使用Array,创建之后长度不可改变。变长数组使用ArrayBuffer。
与java一样,scala中多维数组也是通过数组的数组来实现的。构造多维数组可以使用ofDim方法或者直接使用for循环来new。示例如下:
val matrix = Array.ofDim[Double](3,4) // ofDim方法创建多维数组
matrix(1)(2) = 12.36
val mutliarr = new Array[Array[Int]](10) // for循环方式创建多维数组
for(i <- 0 until mutliarr.length)
mutliarr(i) = new Array[Int](5)
列表:
列表保存相同类型的元素。scala里的列表类型是协变的,这意味着如果S是T的子类,那么List[S]也是List[T]的子类。不可变列表使用List,一旦创建之后就不可改变。可变列表使用ListBuffer。
List是抽象类,它有两个子类型:Nil和::。Nil是空列表对象,类型是List[Nothing]。::是样本类,可以创建非空列表,::的伴生对象可以以中缀标注的形式用于模式匹配。所以在scala中存在两个::,一个是样本类,另一个是List的方法,因此在构造一个列表时,我们就有了多种方法,如下:
val list1 = List("A") // 这里List是伴生对象,相当于 List.apply()
val list2 = ::("A",Nil) // 这里::是伴生对象, 相当于 ::.apply()
val list3 = "A" :: Nil // 这里::是方法, 相当于 Nil.::()
List类没有提供append操作(向列表尾部追加),因为随着列表变长,效率将逐渐低下。List提供了“::”做前缀插入,因为这将消耗固定时间。如果你想通过添加元素来构造列表,你的选择是先把它们前缀插入,完成之后再调用reverse;或者使用ListBuffer,一种提供append操作的可变列表,完成之后调用toList。
栈和队列:
scala集合库提供了可变和不可变的栈类Stack,也提供了可变和不可变的队列类Queue。元组与对偶:
元组Tuple也是不可变的,但元组可以包含不同类型的元素,并且因此而不能继承自Iterable。元组实例化之后,可以使用点号、下划线和从1开始的索引访问其中的元素。因为元组可以保存不同类型的元素,所以不能使用apply方法访问其元素(apply返回同样的类型)。元组的索引从1开始,是因为对于拥有静态类型元组的其他语言,如Haskell和ML,从1开始是传统的设定。
scala的任何对象都可以调用“->”方法,并返回包含键值对的二元组(也叫对偶,是元组的最简单形态),比如 “hello” -> 100 则创建出 (“hello”, 100)。
元组相应操作示例如下:
val t = (1400, “Jim”, “haha”, 3.14) // 定义一个元组
val second = t._2 // 引用元组第二个组元
val (first, second, third, fourth) = t // 分别获取元组的第1、2、3、4个组元
val (first, secong, _) = t // 只获取前两个组元
集和映射:
集中保存着不重复的元素。映射可以把键和值关联起来保存。拉链操作:
val symbols = Array(“<”, “-”, “>”)val counts = Array(2, 10, 2)
val pairs = symbols.zip(counts)
以上代码生成对偶类型的数组,如下:
Array((<,2), (-,10), (>,2))
可变集合vs不可变集合:
可变集合性能更好,不可变集合更易于理清头绪。对于某些问题来说,可变集合能够很好的处理;而另一些,不可变集合更为合适。如果在使用可变集合时,你发现需要担忧何时复制可变集合的副本,或者思考很多关于谁“主宰”或“拥有”可变集合的时候,那么请考虑是否可用不可变集合代替。异常
scala的异常工作机制与java的类似,但也有区别。区别如下:
① scala没有“受检”异常——你不需要声明函数或方法可能会抛出某种异常。
② throw表达式是有值的,其值是Nothing类型。
③ try-catch-finally表达式也是有值的,但是情况有些特殊。当没有抛出异常时,try子句为表达式值;如果抛出异常并被捕获,则对应于相应的catch子句;如果没有被捕获,表达式就没有返回值。finally子句计算得到的值,总是被抛弃(除非使用return语句),所以你应该在finally子句中干一些它应该干的事,比如说:关闭文件、套接字、数据库连接等,而最好别干什么其他事。
断言、检查
scala里,断言使用assert函数,检查使用ensuring函数,如果条件不成立,它们将会抛出AssertionError。它们都在Predef中定义。你可以使用JVM的-ea和-da命令行标志来开放和禁止断言以及检查。
包和引用
打包:
scala的代码采用了java平台完整的包机制。你可以使用两种方式把代码放进包里:① 使用放在文件顶部的package子句来把整个文件放入包中;
② 使用package子句把要放入到包中的代码用花括号括起来,这种方式像C#的命名空间。使用这种方式,你可以定义出嵌套的包,注意:scala的包可以嵌套,java则不可以。任何你自己写的顶层包都被隐含地包含在_root_包中,因此你可以在多层嵌套的包代码中通过_root_来访问顶层包中的代码。
引用:
与java类似,scala使用import来引用,与java不同的是,scala的import子句:① 可以出现在任何地方,而不仅仅在文件开始处;
② 可以引用对象和包;
③ 可以重命名或隐藏一些被引用的成员。这可以通过在被引用成员的对象之后加上括号里的引用选择器子句来做到,示例如下(令p为包名):
import p.{x} // 从p中引入x,等价于 import p.x
import p.{x => y} // 从p中引入x,并重命名为y
import p.{x => _, _} // 从p中引入除了x之外的所有东东。注意单独的“_”称作全包括,必须位于选择器的最后。import p.{_} 等价于 import p._
隐式引用:
scala隐含地为每个源文件都加入如下引用:import java.lang._
import scala._
import Predef._
包scala中的Predef对象包含了许多有用的方法。例如:通常我们所使用的println、readLine、assert等。
scala I/O
由于scala可以和java互操作,因此目前scala中的I/O类库并不多,你可能需要使用java中的I/O类库。下面介绍scala中有的东东:
scala.Console对象可以用于终端输入输出,其中终端输入函数有:readLine、readInt、readChar等等,终端输出函数有:print、println、printf等等。其实,Predef对象中提供的预定义的readLine、println等等方法都是Console对象中对应方法的别名。
scala.io.Source可以以文本的方式迭代地读取源文件或者其他数据源。用完之后记得close啊。
对象序列化:
为了让对象可序列化,你可以这样定义类:@SerialVersionUID(42L) class Person extends Serializable {…}
其中,@SerialVersionUID注解指定序列化ID,如果你能接受缺省的ID,也可省去该注解;Serializable在scala包中,因此你无需引入。你可以像java中一样对对象进行序列化。scala集合类都是可以序列化的,因此你可以把它们作为你的可序列化类的成员。
Actor和并发
与java的基于共享数据和锁的线程模型不同,scala的actor包则提供了另外一种不共享任何数据、依赖消息传递的模型。设计并发软件时,actor是首选的工具,因为它们能够帮助你避开死锁和争用状况,这两种情形都是在使用共享和锁模型时很容易遇到的。
创建actor:
actor是一个类似于线程的实体,它有一个用来接收消息的邮箱。实现actor的方法是继承scala.actors.Actor特质并完成其act方法。你可以通过actor的start方法来启动它。actor在运行时都是相互独立的。你也可以使用scala.actors.Actor对象的actor方法来创建actor,不过此时你就无需再调用start方法,因为它在创建之后马上启动。发送接收消息:
Actor通过相互发送消息的方式进行通信,你可以使用“!”方法来发送消息,使用receive方法来接收消息,receive方法中包含消息处理的模式匹配(偏函数)。发送消息并不会导致actor阻塞,发送的消息在接收actor的邮箱中等待处理,直到actor调用了receive方法,如果actor调用了receive但没有模式匹配成功的消息,那么该actor将会阻塞,直到收到了匹配的消息。创建actor并发送接收消息的示例如下:object ScalaTest extends Actor {
def act() {
while (true) {
receive {
case msg => println(msg)
}
}
}
def main(args: Array[String]) {
start()
this ! "hello."
}
}
将原生线程当作actor:
Actor子系统会管理一个或多个原生线程供自己使用。只要你用的是你显式定义的actor,就不需要关心它们和线程的对应关系是怎样的。该子系统也支持反过来的情形:即每个原生线程也可以被当作actor来使用。此时,你应该使用Actor.self方法来将当前线程作为actor来查看,也就是说可以这样使用了:Actor.self ! "message"。通过重用线程获取更好的性能:
Actor是构建在普通java线程之上的,如果你想让程序尽可能高效,那么慎用线程的创建和切换就很重要了。为帮助你节约线程,scala提供了react方法,和receive一样,react带有一个偏函数,不同的是,react在找到并处理消息后并不返回(它的返回类型是Nothing),它在处理完消息之后就结束了。由于react不需要返回,故其不需要保留当前线程的调用栈。因此actor库可以在下一个被唤醒的线程中重用当前的线程。极端情况下,如果程序中所有的actor都使用react,则它们可以用单个线程实现。由于react不返回,接收消息的消息处理器现在必须同时处理消息并执行actor所有余下的工作。通常的做法是用一个顶级的工作方法(比如act方法自身)供消息处理器在处理完消息本身之后调用。编写使用react而非receive的actor颇具挑战性,不过在性能上能够带来相当的回报。另外,actor库提供的Actor.loop函数可以重复执行一个代码块,哪怕代码调用的是react。
良好的actor风格:
良好的actor风格的并发编程可以使你的程序更容易调试并且减少死锁和争用状况。下面是一些actor风格编程的指导意见:actor不应阻塞:编写良好的actor在处理消息时并不阻塞。因为阻塞可能会导致死锁,即其他多个actor都在等待该阻塞的actor的响应。代替阻塞当前actor,你可以创建一个助手actor,该助手actor在睡眠一段时间之后发回一个消息,以告诉创建它的actor。记住一句话:会阻塞的actor不要处理消息,处理消息的actor请不要使其阻塞。
只通过消息与actor通信:Actor模型解决共享数据和锁的关键方法是提供了一个安全的空间——actor的act方法——在这里你可以顺序地思考。换个说法就是,actor让你可以像一组独立的通过异步消息传递来进行交互的单线程的程序那样编写多线程的程序。不过,这只有在消息是你的actor的唯一通信途径的前提下才成立。一旦你绕过了actor之间的消息传递机制,你就回到了共享数据和锁的模型中,所有那些你想用actor模型避开的困难又都回来了。但这并不是说你应该完全避免绕开消息传递的做法,虽然共享数据和锁要做正确很难,但也不是完全不可能。实际上scala的actor和Erlang的actor实现方式的区别之一就是,scala让你可以在同一个程序中混用actor与共享数据和锁两种模型。
优选不可变消息:actor模型提供了每个actor的act方法的单线程环境,你无需担心它使用到的对象是否是线程安全的,因为它们都被局限于一个线程中。但例外的是在多个线程中间传送的消息对象,它被多个actor共享,因此你需要担心消息对象是否线程安全。确保消息对象是线程安全的最佳途径是在消息中只使用不可变对象。如果你发现你有一个可变对象,并且想通过消息发送给另一个actor,你应该制作并发送它的一个副本。
让消息自包含:actor在发送请求消息之后不应阻塞,它继续做着其他事情,当收到响应消息之后,它如何解释它(也就是说它如何能记起它在发送请求消息时它在做着什么呢),这是一个问题。解决办法就是在响应消息中增加冗余信息,比如说可以把请求消息中的一些东东作为响应消息的一部分发送给请求者。
GUI编程
scala图形用户界面编程可以使用scala.swing库,该库提供了对java的Swing框架的GUI类的访问,对其进行包装,隐藏了大部分复杂度。示例如下:
object MyScalaGUI extends SimpleSwingApplication {
def top = new MainFrame {
title = "My Scala GUI"
location = new Point(600, 300)
preferredSize = new Dimension(400, 200)
val button = new Button {
text = "Click me"
}
val label = new Label {
text = "Who am I?"
}
contents = new BoxPanel(Orientation.Vertical) {
contents += button
contents += label
}
listenTo(button)
reactions += {
case ButtonClicked(b) => label.text = "Hello, I'm Tom."
}
}
}
要编写图形界面程序,你可以继承SimpleSwingApplication类,该类已经定义了包含一些设置java Swing框架代码的main方法,main方法随后会调用top方法,而top方法是抽象的,需要你来实现。top方法应当包含定义顶级GUI组件的代码,这通常是某种Frame。
GUI类库:
Frame:即可以包含任意数据的窗体。Frame有一些属性(也就是getter和setter),其中比较重要的有title(将被写到标题栏)、contents(将被显示在窗体中)。Frame继承自Container,每个Container都有一个contents属性,让你获得和设置它包含的组件,不过,Frame的contents只能包含一个组件,因为框架的contents属性只能通过“=”赋值,而有些Container (如Panel)的contents可以包含多个组件,因为它们的contents属性可以通过“+=”赋值。MainFrame:就像是个普通的Swing的Frame,只不过关闭它的同时也会关闭整个GUI应用程序。
Panel:面板是根据某种固定的布局规则显示所有它包含的组件的容器。面板可以包含多个组件。
处理事件:
为了处理事件,你需要为用户输入事件关联一个动作,scala和java基本上用相同的“发布/订阅”方式来处理事件。发布者又称作事件源,订阅者又称作事件监听器。举例来说,Button是一个事件源,它可以发布一个事件ButtonClicked,表示该按钮被点击。scala中事件是真正的对象,创建一个事件也就是创建一个样本类的实例,样本类的参数指向事件源。事件(样本)类包含在scala.swing.event包中。在scala中,订阅一个事件源source的方法是调用listenTo(source),取消订阅的方法是调用deafTo(source)。比如:你可以让一个组件A监听它其中的一个组件B,以便A在B发出任何事件时得到通知。为了让A对监听到的事件做出响应,你需要向A中名为reactions的属性添加一个处理器,处理器也就是带有模式匹配的函数字面量,可以在单个处理器中用多个样本来匹配多种事件。可使用“+=”向reactions中添加处理器,使用“-=”从中移除处理器。从概念上讲,reactions中安装的处理器形成一个栈,当接收到一个事件时,最后被安装的处理器首先被尝试,但不管尝试是否成功,后续的处理器都会被一一尝试。
结合scala和java
scala和java高度兼容,因此可以进行互操作,大多数情况下结合这两种语言时并不需要太多顾虑,尽管如此,有时你还是会遇到一些结合java和scala的问题。基本上,scala使用java代码相对于java使用scala代码更容易一些。
scala代码如何被翻译:
scala的实现方式是将代码翻译为标准的java字节码。scala的特性尽可能地直接映射为相对等的java特性。但scala中的某些特性(如特质)在java中没有,而还有一些特性(如泛型)与java中的不尽相同,对于这些特性,scala代码无法直接映射为java的语法结构,因此它必须结合java现有的特性来进行编码。这些是一般性的原则,现在我们来考虑一些特例:值类型:类似Int这样的值类型翻译成java有两种不同的方式,只要可能就直接翻译为java的int以获得更好的性能,但有时做不到,就翻译为包装类的对象。
单例对象:scala对单例对象的翻译采用了静态和实例方法相结合的方式。对每一个scala单例对象,编译器都会为这个对象创建一个名称后加美元符号的java类,这个类拥有scala单例对象的所有方法和字段,这个java类同时还有一个名为MODULE$的静态字段,保存该类在运行期创建的一个实例。也就是说,在java中要这样使用scala中的单例对象:单例对象名$.MODULE$.方法名();
特质:编译任何scala特质都会创建一个同名的java接口,这个接口可以作为java类型使用,你可以通过这个类型的变量来调用scala对象的方法。如果特质中还有已经实现的方法,那么还会生成对应的实现类“特质名$class”。
存在类型:
所有java类型在scala中都有对等的概念,这是必要的,以便scala可以访问任何合法的java类。scala中的存在类型实际上主要是用于从scala访问java泛型中的通配类型以及没有给出类型参数的原始类型。存在类型的通用形式如下:type forSome { declarations }
type部分是任意的scala类型,而declarations部分是一个抽象val和type的列表。这个定义解读为:声明的变量和类型是存在但未知的,正如类中的抽象成员那样。这个类型进而被允许引用这些声明的变量和类型,虽然编译器不知道它们具体指向什么。例如对于如下的java语句:
Iterator<?>
Iterator<? extends Component>
在scala中可以用存在类型分别表示为:
Iterator[T] forSome { type T }
Iterator[T] forSome { type T <: Component }
另外,存在类型也可以使用下划线占位符语法以更简短的方式来写。如果在可以使用类型的地方使用了下划线,那么scala会为你做出一个存在类型,每个下划线在forSome语句中都变成一个类型参数。如前我们在介绍scala的泛型时,指定类型参数上界下界时,使用的就是这种简写的语法。作为示例,我们可以将上述两个语句简写为:
Iterator[_]
Iterator[_ <: Component]
隐式转换为java类型:
在scala和java代码之间传递数据时,如果使用的是容器类库(当然包括数组等),那么可能需要进行一些转换,而scala类库本身就提供了这样的隐式转换库,因此你可以方便地在scala和java之间传递数据。你唯一需要做的是:import scala.collection.JavaConversions._。

相关文章推荐
- Scala基础数据格式化输出总结
- Scala 基础总结
- 复习总结08:Scala基础
- scala基础总结(一)
- Scala基础入门(十三 ) 类、函数参数形式、种类、使用方式总结
- scala基础总结
- Scala基础总结(二)
- Scala基础入门(八)Scala 导入包的方式总结
- 总结:程序设计基础
- Scala 基础语法
- 信息安全系统设计基础第七周学习总结
- 基础总结篇之一:Activity生命周期
- 学号20145220《信息安全系统设计基础》第8周学习总结
- 20155330 《信息安全系统设计基础》课程总结
- Struts2基础学习总结
- [算法总结] 基础算法技巧总结
- Byte类型与各种基础类型之间的相互转化函数总结
- Angular1.x 基础总结
- java基础题目总结
- java 基础知识总结2