方差与偏差
2018-04-01 13:10
204 查看
在周志华《机器学习》这本书中,提到了方差与偏差的概念。在后来的学习中越发感觉理解方差与偏差可以从更深层次理解各种学习算法。在书中做了如下表述:在忽略噪声的情况下,泛化误差可分解为偏差、方差两部分。
偏差:度量学习算法的期望预测与真实结果的偏离程度,也叫拟合能力。
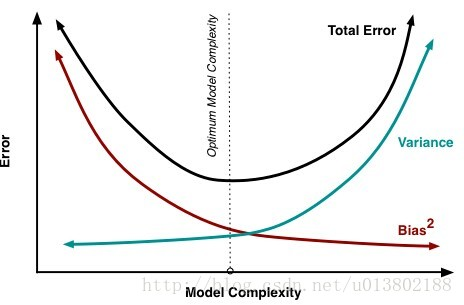
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动造成的影响。神图:

另外节选《机器学习》第45页的公式:
偏差-方差分解试图对学习算法的期望泛化错误率进行拆解。我们知道,算法在不同训练集上学得的结果很可能不同,即便这些训练集是来自同一个分布。对测试样本x,令yD为x在数据集中的标记,y为x的真实标记,f(x;D)为训练集D上学得模型f在x上的预测输出。以回归任务为例,学习算法的期望预测为
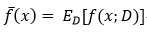
使用样本数相同的不同训练集产生的方差为
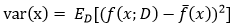
噪声为
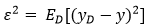
期望输出与真实标记的差别成为偏差,即
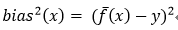
可对算法的期望泛化误差进行分解:
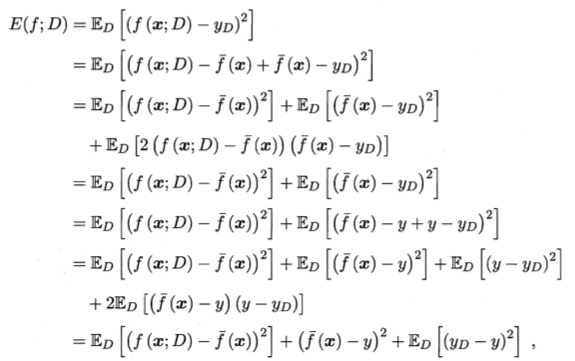
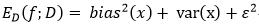
回顾偏差,方差,噪声的含义:
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
偏差-方差分解说明,泛化性能是由学习算法的能力,数据的充分性,以及学习任务本身的难度所共同决定的。
一般来说,偏差与方差是有冲突的,这称为偏差-方差窘境。如下图所示,给定学习任务,假定我们能够控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充分后,学习器的拟合能力已经非常强,训练数据发生的轻微扰动都能导致学习器发生显著变化,若训练数据自身的,非全局的特性被学习器学到了,则发生了过拟合。
对于一些机器学习算法偏差与方差的思考:在机器学习的面试中,能不能讲清楚偏差方差,经常被用来考察面试者的理论基础。偏差方差看似很简单,但真要彻底地说明白,却有一定难度。比如,为什么KNN算法在增大k时,偏差会变大,但RF增大树的数目时偏差却保持不变,GBDT在增大树的数目时偏差却又能变小。作者:milter
链接:https://www.zhihu.com/question/20448464/answer/339471179
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。对于KNN算法,k值越大,表示模型的学习能力越弱,因为k越大,它越倾向于从“面”上考虑做出判断,而不是具体地考虑一个样本 近身的情况来做出判断,所以,它的偏差会越来越大。对于RF,我们实际上是部分实现了多次训练取均值的效果,每次训练得到的树都是一个很强的学习者,每一个的方差都比较大,但综合起来就会比较小。好比一个很强的学习者学习时,刮着西风,它会据此调整自己的瞄准方法,另一个很强的学习者学习时刮着东风,(西风、东风可以理解为不同训练集中的噪声)它也会据此调整自己的瞄准方法,在测试样本时,一个误差向西,一个误差向东,刚好起到互相抵消的作用,所以方差会比较小。但是由于每棵树的偏差都差不多,所以,我们取平均时,偏差不会怎么变化。为什么说是部分实现了多次训练取均值的效果而不是全部呢?因为我们在训练各棵树时,是通过抽样样本集来实现多次训练的,不同的训练集中不可避免地会有重合的情况,此时,就不能认为是独立的多次训练了,各个训练得到的树之间的方差会产生一定的相关性,训练集中重合的样本越多,则两棵树之间的方差的相关性越强,就越难达成方差互相抵消的效果。对于GBDT,N棵树之间根本就不是一种多次训练取均值的关系,而是N棵树组成了相关关联,层层递进的超级学习者,可想而知,它的方差一定是比较大的。但由于它的学习能力比较强,所以,它的偏差是很小的,而且树的棵树越多,学习能力就越强,偏差就越小。也就是说,只要学习次数够多,预测的均值会无限接近于目标。简单讲就是GBDT的N棵树实际上是一个有机关联的模型,不能认为是N个模型。
偏差:度量学习算法的期望预测与真实结果的偏离程度,也叫拟合能力。
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动造成的影响。神图:
另外节选《机器学习》第45页的公式:
偏差-方差分解试图对学习算法的期望泛化错误率进行拆解。我们知道,算法在不同训练集上学得的结果很可能不同,即便这些训练集是来自同一个分布。对测试样本x,令yD为x在数据集中的标记,y为x的真实标记,f(x;D)为训练集D上学得模型f在x上的预测输出。以回归任务为例,学习算法的期望预测为
使用样本数相同的不同训练集产生的方差为
噪声为
期望输出与真实标记的差别成为偏差,即
可对算法的期望泛化误差进行分解:
回顾偏差,方差,噪声的含义:
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力;
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响;
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
偏差-方差分解说明,泛化性能是由学习算法的能力,数据的充分性,以及学习任务本身的难度所共同决定的。
一般来说,偏差与方差是有冲突的,这称为偏差-方差窘境。如下图所示,给定学习任务,假定我们能够控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充分后,学习器的拟合能力已经非常强,训练数据发生的轻微扰动都能导致学习器发生显著变化,若训练数据自身的,非全局的特性被学习器学到了,则发生了过拟合。
对于一些机器学习算法偏差与方差的思考:在机器学习的面试中,能不能讲清楚偏差方差,经常被用来考察面试者的理论基础。偏差方差看似很简单,但真要彻底地说明白,却有一定难度。比如,为什么KNN算法在增大k时,偏差会变大,但RF增大树的数目时偏差却保持不变,GBDT在增大树的数目时偏差却又能变小。作者:milter
链接:https://www.zhihu.com/question/20448464/answer/339471179
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。对于KNN算法,k值越大,表示模型的学习能力越弱,因为k越大,它越倾向于从“面”上考虑做出判断,而不是具体地考虑一个样本 近身的情况来做出判断,所以,它的偏差会越来越大。对于RF,我们实际上是部分实现了多次训练取均值的效果,每次训练得到的树都是一个很强的学习者,每一个的方差都比较大,但综合起来就会比较小。好比一个很强的学习者学习时,刮着西风,它会据此调整自己的瞄准方法,另一个很强的学习者学习时刮着东风,(西风、东风可以理解为不同训练集中的噪声)它也会据此调整自己的瞄准方法,在测试样本时,一个误差向西,一个误差向东,刚好起到互相抵消的作用,所以方差会比较小。但是由于每棵树的偏差都差不多,所以,我们取平均时,偏差不会怎么变化。为什么说是部分实现了多次训练取均值的效果而不是全部呢?因为我们在训练各棵树时,是通过抽样样本集来实现多次训练的,不同的训练集中不可避免地会有重合的情况,此时,就不能认为是独立的多次训练了,各个训练得到的树之间的方差会产生一定的相关性,训练集中重合的样本越多,则两棵树之间的方差的相关性越强,就越难达成方差互相抵消的效果。对于GBDT,N棵树之间根本就不是一种多次训练取均值的关系,而是N棵树组成了相关关联,层层递进的超级学习者,可想而知,它的方差一定是比较大的。但由于它的学习能力比较强,所以,它的偏差是很小的,而且树的棵树越多,学习能力就越强,偏差就越小。也就是说,只要学习次数够多,预测的均值会无限接近于目标。简单讲就是GBDT的N棵树实际上是一个有机关联的模型,不能认为是N个模型。

相关文章推荐
- 方差与偏差的权衡(trade-off)
- 机器学习中的数学(2)-线性回归,偏差、方差权衡
- 机器学习中偏差和方差的区别
- 机器学习中的偏差和方差
- 机器学习:Bias(偏差),Error(误差),和Variance(方差)
- 高偏差、高方差、低精确率与低召回率、混淆矩阵
- [DeeplearningAI笔记]改善深层神经网络1.1_1.3深度学习实用层面_偏差/方差/欠拟合/过拟合/训练集/验证集/测试集
- 机器学习中,如何利用训练集&测试集来判断 方差(varience)& 偏差(bias)
- 机器学习中的数学(2)-线性回归,偏差、方差权衡
- Coursera | Andrew Ng (02-week-1-1.2)—偏差_方差
- 机器学习中的数学(2)-线性回归,偏差、方差权衡
- 机器学习中的数学(2)-线性回归,偏差、方差权衡
- 斯坦福ML公开课笔记9—偏差/方差、经验风险最小化、联合界、一致收敛
- 机器学习中的数学(2)-线性回归,偏差、方差权衡
- 朴素贝叶斯是高偏差低方差
- 机器学习中的Bias(偏差),Error(误差),和Variance(方差)有什么区别和联系?
- 偏差,方差,训练误差,测试误差的区别
- 机器学习中的偏差,方差,训练误差,测试误差相关
- 偏差(bias)和方差(variance)及其与K折交叉验证的关系
- 偏差和方差