[硬货]| 实例介绍TensorFlow的输入流水线
2018-04-01 10:34
176 查看

编辑:赵一帆
前言
在训练模型时,我们首先要处理的就是训练数据的加载与预处理的问题,这里称这个过程为输入流水线(input pipelines,或输入管道,参考)。在TensorFlow中,典型的输入流水线包含三个流程(ETL流程):提取(Extract):从存储介质(如硬盘)中读取数据,可能是本地读取,也可能是远程读取(比如在分布式存储系统HDFS)
预处理(Transform):利用CPU处理器解析和预处理提取的数据,如图像解压缩,数据扩增或者变换,然后会做random shuffle,并形成batch。
加载(load):将预处理后的数据加载到加速设备中(如GPUs)来执行模型的训练。
输入流水线对于加速模型训练还是很重要的,如果你的CPU处理数据能力跟不上GPU的处理速度,此时CPU预处理数据就成为了训练模型的瓶颈环节。除此之外,上述输入流水线本身也有很多优化的地方。比如,一个典型的模型训练过程中,CPU预处理数据时,GPU是闲置的,当GPU训练模型时,CPU是闲置的,这个过程如下所示:
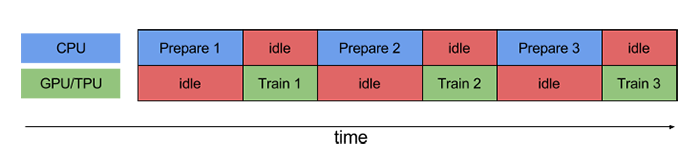
这样一个训练step中所花费的时间是CPU预处理数据和GPU训练模型时间的总和。显然这个过程中有资源浪费,一个改进的方法就是交叉CPU数据处理和GPU模型训练这两个过程,当GPU处于第N个训练阶段,CPU正在准备第N+1步所需的数据,如下图所示:
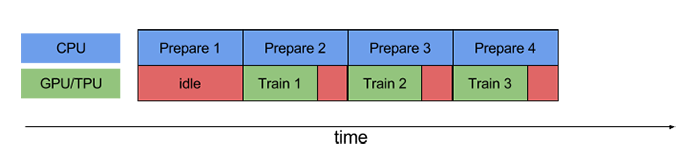
明显上述设计可以充分最大化利用CPU和GPU,从而减少资源的闲置。另外当存在多个CPU核心时,这又会涉及到CPU的并行化技术(多线程)来加速数据预处理过程,因为每个训练样本的预处理过程往往是互相独立的。关于输入流程线的优化可以参考TensorFlow官网上的Input Pipeline Performance Guide,相信你会受益匪浅。
幸运的是,最新的TensorFlow版本提供了
tf.data这一套APIs来帮助我们快速实现高效又灵活的输入流水线。在TensorFlow中最常见的加载训练数据的方式是通过Feeding方式,其主要是定义
placeholder,然后将通过Session.run()的
feed_dict参数送入数据,但是这其实是最低效的加载数据方式。后来,TensorFlow增加了QueueRunner机制,其主要是基于文件队列以及多线程技术,实现了更高效的输入流水线,但是其APIs很是让人难懂,所以就有了现在的
tf.data来替代它。
这里我们通过mnist实例来讲解如何使用
tf.data建立简洁而高效的输入流水线,在介绍之前,我们先介绍如何制作TFRecords文件,这是TensorFlow支持的一种标准文件格式
制作TFRecords文件
TFRecords文件是TensorFlow中的标准数据格式,它是基于protobuf的二进制文件,每个TFRecord文件的基本元素是tf.train.Example,其对应的是数据集中的一个样本数据,每个Example包含Features,存储该样本的各个feature,每个feature包含一个键值对,分别对应feature的特征名与实际值。下面是一个Example实例(参考):
// An Example for a movie recommendation application:
features {
feature {
key: "age"
value { float_list {
value: 29.0
}}
}
feature {
key: "movie"
value { bytes_list {
value: "The Shawshank Redemption"
value: "Fight Club"
}}
}
feature {
key: "movie_ratings"
value { float_list {
value: 9.0
value: 9.7
}}
}
feature {
key: "suggestion"
value { bytes_list {
value: "Inception"
}}
}
feature {
key: "suggestion_purchased"
value { float_list {
value: 1.0
}}
}
feature {
key: "purchase_price"
value { float_list {
value: 9.99
}}
}
}上面是一个电影推荐系统中的一个样本,可以看到它共含有6个特征,每个特征都是key-value类型,key是特征名,而value是特征值,值得注意的是value其实存储的是一个list,根据数据类型共分为三种:
bytes_list,
float_list和
int64_list,分别存储字节、浮点及整数类型(见这里)。
作为标准数据格式,TensorFlow当然提供了创建TFRecords文件的python接口,下面我们创建mnist数据集对应的TFRecords文件。对于mnist数据集,每个Example需要存储两个feature,一个是图像的像素值,这里可以用bytes类型,因为一个像素点正好可以用一个字节存储,另外是图像的标签值,只能用int64类型存储了。因此,我们先定义这两个类型的接口函数:
# int64 def _int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # bytes def _bytes_feature(value): return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
创建TFRecord文件,主要通过TF中的
tf.python_io.TFRecordWriter函数来实现,具体代码如下:
def convert_to_TFRecords(dataset, name):
"""Convert mnist dataset to TFRecords"""
images, labels = dataset.images, dataset.labels
n_examples = dataset.num_examples
filename = os.path.join(DIR, name + ".tfrecords")
print("Writing", filename)
with tf.python_io.TFRecordWriter(filename) as writer:
for index in range(n_examples):
image_bytes = images[index].tostring()
label = labels[index]
example = tf.train.Example(features=tf.train.Features(
feature={"image": _bytes_feature(image_bytes),
"label": _int64_feature(label)}))
writer.write(example.SerializeToString())对于mnist数据集,主要分为train、validation和test,利用上面的函数分别创建三个不同的TFRecords文件:
mnist_datasets = mnist.read_data_sets("mnist_data", dtype=tf.uint8, reshape=False)
convert_to_TFRecords(mnist_datasets.train, "train")
convert_to_TFRecords(mnist_datasets.validation, "validation")
convert_to_TFRecords(mnist_datasets.test, "test")好了,这样我们就创建3个TFRecords文件了。
读取TFRecords文件
上面我们创建了TFRecords文件,但是怎么去读取它们呢,当然TF提供了读取TFRecords文件的接口函数,这里首先介绍如何利用TF中操作TFRecord的python接口来读取TFRecord文件,主要是tf.python_io.tf_record_iterator函数,它输入TFRecord文件,但是得到一个迭代器,每个元素是一个Example,但是却是一个字符串,这里可以用
tf.train.Example来解析它,具体代码如下:
def read_TFRecords_test(name):
filename = os.path.join(DIR, name + ".tfrecords")
record_itr = tf.python_io.tf_record_iterator(path=filename)
for r in record_itr:
example = tf.train.Example()
example.ParseFromString(r)
label = example.features.feature["label"].int64_list.value[0]
print("Label", label)
image_bytes = example.features.feature["image"].bytes_list.value[0]
img = np.fromstring(image_bytes, dtype=np.uint8).reshape(28, 28)
print(img)
plt.imshow(img, cmap="gray")
plt.show()
break # 只读取一个Example上面仅是纯python的读取方式,这不是TFRecords文件的正确使用方式。既然是官方标准数据格式,TF也提供了使用TFRecords文件建立输入流水线的方式。在
tf.data出现之前,使用的是
QueueRunner方式,即文件队列机制,其原理如下图所示:
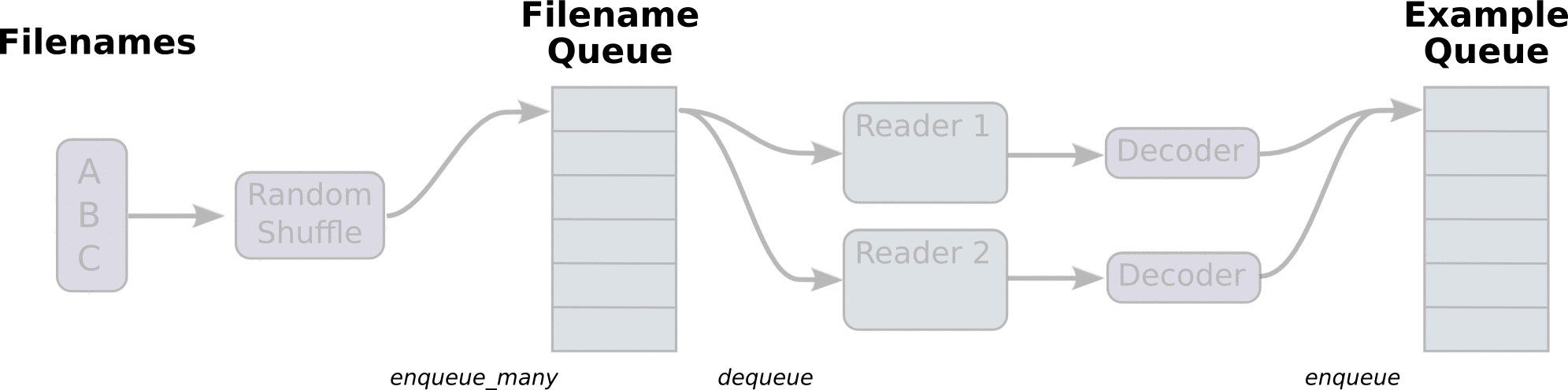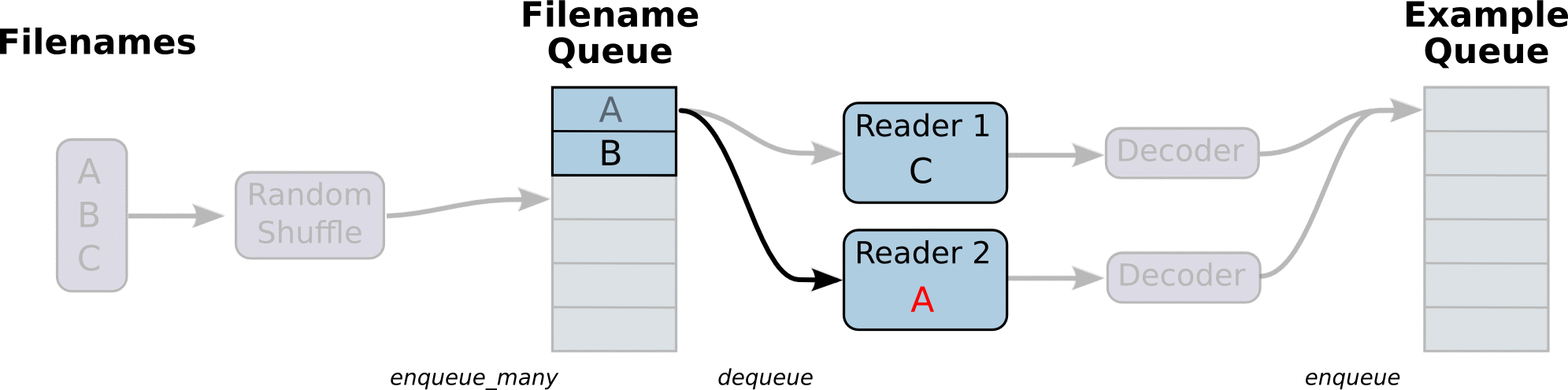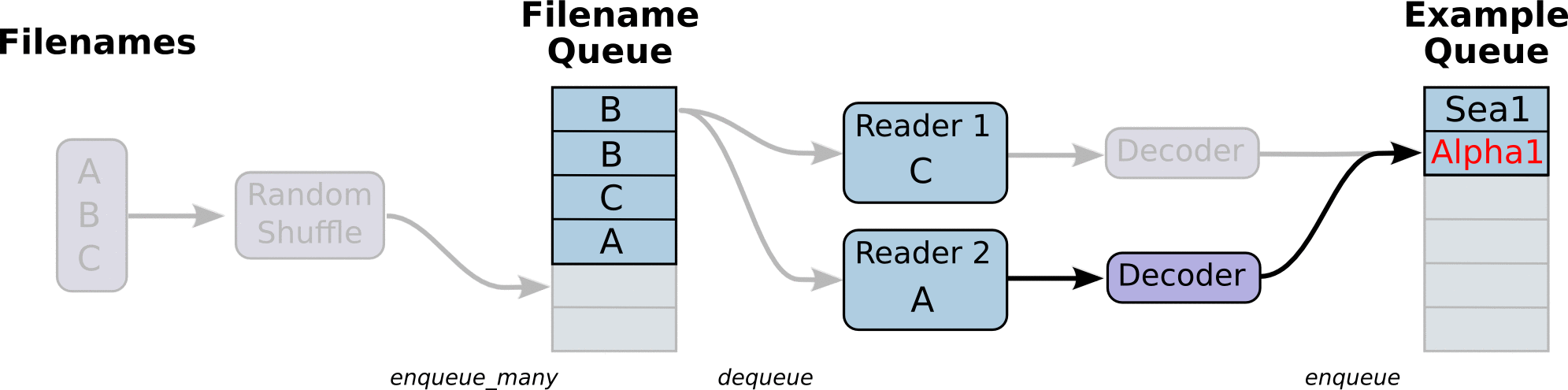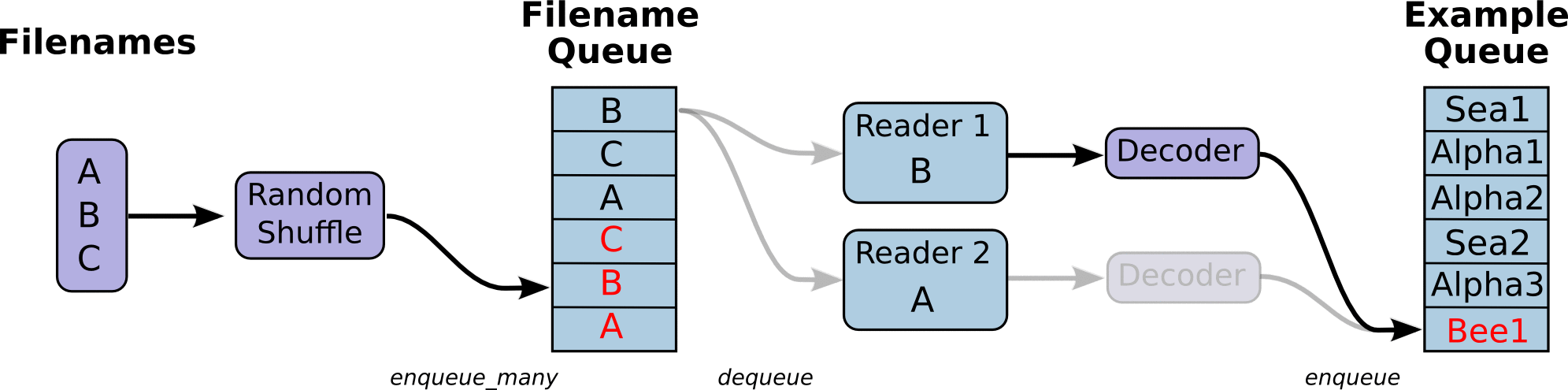
文件队列机制主要分为两个阶段:第一个阶段将输入文件打乱,并在文件队列入列,然后
Reader从文件队列中读取一个文件,同时文件队列出列这个文件,
Reader同时对文件进行解码,然后生产数据样本,并将样本在样本队列中入列,可以定义多个
Reader并发地从多个文件同时读取数据。从样本队列中的出列一定量的样本数据即可以用于一个训练过程。TF提供了配套的API来完成这个过程,注意的是这个输入流水线是直接嵌入训练的Graph中,即是整个图模型的一部分。根据文件的不同,可以使用不同类型的
Reader,对于TFRecord文件,可以使用
tf.TFRecordReader,下面是具体的实现代码:
def read_example(filename_queue):
"""Read one example from filename_queue"""
reader = tf.TFRecordReader()
key, value = reader.read(filename_queue)
features = tf.parse_single_example(value, features={"image": tf.FixedLenFeature([], tf.string),
"label": tf.FixedLenFeature([], tf.int64)})
image = tf.decode_raw(features["image"], tf.uint8)
image = tf.reshape(image, [28, 28])
label = tf.cast(features["label"], tf.int32)
return image, label
if __name__ == "__main__":
queue = tf.train.string_input_producer(["TFRecords/train.tfrecords"], num_epochs=10)
image, label = read_example(queue)
img_batch, label_batch = tf.train.shuffle_batch([image, label], batch_size=32, capacity=5000,
min_after_dequeue=2000, num_threads=4)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
while not coord.should_stop():
# Run training steps or whatever
images, labels = sess.run([img_batch, label_batch])
print(images.shape, labels.shape)
except tf.errors.OutOfRangeError:
print('Done training -- epoch limit reached')
coord.request_stop()
coord.join(threads)对于队列机制,估计大家看的云里雾里的,代码确实让人难懂,但是其实只要按照官方提供的标准代码,还是很容易在自己的数据集上进行修改的。不过现在有了
tf.data,可以更加优雅地实现上面的过程。
tf.data简介
使用tf.data可以更方便地创建高效的输入流水线,但是其相比队列机制API更友好,这主要是因为
tf.data提供了高级抽象。第一个抽象是使用
tf.data.Dataset来表示一个数据集合,集合里面的每个元素包含一个或者多个Tensor,一般就是对应一个训练样本。第二个抽象是使用
tf.data.Iterator来从数据集中提取数据,这是一个迭代器对象,可以通过
Iterator.get_next()从
Dataset中产生一个样本。利用这两个抽象,
Dataset的使用简化为三个步骤:
创建
Dataset实例对象;
创建遍历
Dataset的
Iterator实例对象;
从
Iterator中不断地产生样本,并送入模型中进行训练。
创建Dataset
TF提供了很多方式创建Dataset,下面是几种方式:
# 从Numpy的array dataset1 = tf.data.Dataset.from_tensor_slices(np.random.randn((5, 10)) print(dataset1.output_types) # ==> "tf.float32" print(dataset1.output_shapes) # ==> "(10,)" # 从Tensor dataset2 = tf.data.Dataset.from_tensor_slices((tf.random_uniform([4]), tf.random_uniform([4, 100], maxval=100, dtype=tf.int32))) print(dataset2.output_types) # ==> "(tf.float32, tf.int32)" print(dataset2.output_shapes) # ==> "((), (100,))" # 从文件 filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"] dataset3 = tf.data.TFRecordDataset(filenames)
更重要的是
Dataset可以进行一系列的变换操作,并且支持链式调用,这对于数据预处理很重要:
dataset = tf.data.TFRecordDataset(filenames) dataset = dataset.map(...) # 解析数据或者对数据预处理,如normalize. dataset = dataset.repeat() # 重复数据集,一般设置num_epochs dataset = dataset.batch(32) # 形成batch
创建Iterator
创建了Dataset之后,我们需要创建
Iterator来遍历数据集,返回的是迭代器对象,并从中可以产生数据,以用于模型训练。TF共支持4中迭代器类型,分别是one-shot, initializable, reinitializable和feedable。下面逐个介绍它们。
One-shot Iterator
这是最简单的Iterator,它仅仅遍历整个数据集一次,而且不需要显示初始化,下面是个实例:dataset = tf.data.Dataset.from_tensor_slices(np.arange(10)) iterator = dataset.make_one_shot_iterator() next_element = iterator.get_next() with tf.Session() as sess: for i in range(10): sess.run(next_element) # 0, 1, ..., 9
Initializable Iterator
相比one-shot Iterator,它需要在使用前显示初始化,这样就可以支持参数化,每次初始化时送入不同的参数,就可以支持数据集的简单参数化,下面是一个实例:max_value = tf.placeholder(tf.int64, [])
dataset = tf.data.Dataset.range(max_value)
iterator = dataset.make_initializable_iterator()
next_element = iterator.get_next()
with tf.Session() as sess:
# 需要显示初始化
sess.run(iterator.initializer, feed_dict={max_value: 10})
for i in range(10):
print(sess.run(next_element)) # 0, 1, ..., 9Reinitializable Iterator
相比initializable Iterator,它可以支持从不同的Dataset进行初始化,有时候你需要训练集和测试集,但是两者并不同,此时就可以定义两个不同的
Dataset,并配合reinitializable Iterator来定义一个通用的迭代器,在使用前只需要送入不同的
Dataset进行初始化就可以,下面是一个实例:
train_data = np.random.randn(100, 5) test_data = np.random.randn(20, 5) train_dataset = tf.data.Dataset.from_tensor_slices(train_data) test_dataset = tf.data.Dataset.from_tensor_slices(test_data) # 创建一个reinitializable iterator re_iterator = tf.data.Iterator.from_structure(train_dataset.output_types, train_dataset.output_shapes) next_element = re_iterator.get_next() train_init_op = re_iterator.make_initializer(train_dataset) test_init_op = re_iterator.make_initializer(test_dataset) with tf.Session() as sess: # 训练 n_epochs = 2 for i in range(n_epochs): sess.run(train_init_op) for j in range(100): print(sess.run(next_element)) # 测试 sess.run(test_init_op) for i in range(20): print(sess.run(next_element))
c3b4
[/code]
Feedable Iterator
对于reinitializable iterator,它可以支持送入不同Dataset,从而完成数据集的切换,但是每次切换时必须要重新初始化。对于Feedable Iterator,其可以认为支持送入不同的
Iterator,通过切换迭代器的string handle来完成不同数据集的切换,并且在切换时迭代器的状态还会被保留,这相比reinitializable iterator更加灵活,下面是一个实例:
train_data = np.random.randn(100, 5)
val_data = np.random.randn(20, 5)
n_epochs = 20
train_dataset = tf.data.Dataset.from_tensor_slices(train_data).repeat(n_epochs)
val_dataset = tf.data.Dataset.from_tensor_slices(val_data)
# 创建一个feedable iterator
handle = tf.placeholder(tf.string, [])
feed_iterator = tf.data.Iterator.from_string_handle(handle, train_dataset.output_types,
train_dataset.output_shapes)
next_element = feed_iterator.get_next()
# 创建不同的iterator
train_iterator = train_dataset.make_one_shot_iterator()
val_iterator = val_dataset.make_initializable_iterator()
with tf.Session() as sess:
# 生成对应的handle
train_handle = sess.run(train_iterator.string_handle())
val_handle = sess.run(val_iterator.string_handle())
# 训练
for n in range(n_epochs):
for i in range(100):
print(i, sess.run(next_element, feed_dict={handle: train_handle}))
# 验证
if n % 10 == 0:
sess.run(val_iterator.initializer)
for i in range(20):
print(sess.run(next_element, feed_dict={handle: val_handle}))关于
tf.data的基础知识就这么多了,更多内容可以参考官方文档,另外这里要说一点就是,对于迭代器对象,当其元素取尽之后,会抛出
tf.errors.OutOfRangeError错误,当然一般情况下你是知道自己的迭代器对象的元素数,那么也就可以不用通过捕获错误来实现终止条件。下面,我们将使用
tf.data实现mnist的完整训练过程。
MNIST完整实例
我们采用feedable Iterator来实现mnist数据集的训练过程,分别创建两个Dataset,一个为训练集,一个为验证集,对于验证集不需要shuffle操作。首先我们创建
Dataset对象的辅助函数,主要是解析TFRecords文件,并对image做归一化处理:
def decode(serialized_example):
"""decode the serialized example"""
features = tf.parse_single_example(serialized_example,
features={"image": tf.FixedLenFeature([], tf.string),
"label": tf.FixedLenFeature([], tf.int64)})
image = tf.decode_raw(features["image"], tf.uint8)
image = tf.cast(image, tf.float32)
image = tf.reshape(image, [784])
label = tf.cast(features["label"], tf.int64)
return image, label
def normalize(image, label):
"""normalize the image to [-0.5, 0.5]"""
image = image / 255.0 - 0.5
return image, label然后定义创建
Dataset的函数,对于训练集和验证集,两者的参数会不同:
def create_dataset(filename, batch_size=64, is_shuffle=False, n_repeats=0): """create dataset for train and validation dataset""" dataset = tf.data.TFRecordDataset(filename) if n_repeats > 0: dataset = dataset.repeat(n_repeats) # for train dataset = dataset.map(decode).map(normalize) # decode and normalize if is_shuffle: dataset = dataset.shuffle(1000 + 3 * batch_size) # shuffle dataset = dataset.batch(batch_size) return dataset
我们使用一个简单的全连接层网络来实现mnist的分类模型:
def model(inputs, hidden_sizes=(500, 500)): h1, h2 = hidden_sizes net = tf.layers.dense(inputs, h1, activation=tf.nn.relu) net = tf.layers.dense(net, h2, activation=tf.nn.relu) net = tf.layers.dense(net, 10, activation=None) return net
然后是训练的主体代码:
n_train_examples = 55000
n_val_examples = 5000
n_epochs = 50
batch_size = 64
train_dataset = create_dataset("TFRecords/train.tfrecords", batch_size=batch_size, is_shuffle=True,
n_repeats=n_epochs)
val_dataset = create_dataset("TFRecords/validation.tfrecords", batch_size=batch_size)
# 创建一个feedable iterator
handle = tf.placeholder(tf.string, [])
feed_iterator = tf.data.Iterator.from_string_handle(handle, train_dataset.output_types,
train_dataset.output_shapes)
images, labels = feed_iterator.get_next()
# 创建不同的iterator
train_iterator = train_dataset.make_one_shot_iterator()
val_iterator = val_dataset.make_initializable_iterator()
# 创建模型
logits = model(images, [500, 500])
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)
loss = tf.reduce_mean(loss)
train_op = tf.train.AdamOptimizer(learning_rate=1e-04).minimize(loss)
predictions = tf.argmax(logits, axis=1)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predictions, labels), tf.float32))
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
with tf.Session() as sess:
sess.run(init_op)
# 生成对应的handle
train_handle = sess.run(train_iterator.string_handle())
val_handle = sess.run(val_iterator.string_handle())
# 训练
for n in range(n_epochs):
ls = []
for i in range(n_train_examples // batch_size):
_, l = sess.run([train_op, loss], feed_dict={handle: train_handle})
ls.append(l)
print("Epoch %d, train loss: %f" % (n, np.mean(ls)))
if (n + 1) % 10 == 0:
sess.run(val_iterator.initializer)
accs = []
for i in range(n_val_examples // batch_size):
acc = sess.run(accuracy, feed_dict={handle: val_handle})
accs.append(acc)
print("\t validation accuracy: %f" % (np.mean(accs)))大约可以在验证集上的accuracy达到98%。
小结
看起来最新的tf.data还是比较好用的,如果你是TensorFlow用户,可以尝试着使用它,当然上面的例子并不能包含关于
tf.data的所有内容,想继续深入的话可以移步TF的官网。
参考
Programmers guide: import data.How to use Dataset in TensorFlow.
Reading data.
Performance: datasets performance.
Introduction to Artificial Neural Networks and Deep Learning: A Practical Guide with Applications in Python.

相关文章推荐
- 实例介绍TensorFlow的输入流水线
- oracle中print_table存储过程实例介绍
- Oracle 阻塞(blocking blocked)介绍和实例演示
- Oracle RAC环境下的阻塞(blocking blocked)介绍和实例演示
- 任何人都能看懂的TensorFlow介绍
- SQL JOIN 连接详细介绍及简单使用实例
- JavaScript输入邮箱自动提示实例代码
- H3 BPM门户操作说明及实例介绍
- 实例介绍利用valgrind定位memcpy内存重叠问题------顺便再次说说memcpy和memmove的区别
- .NET+JS对用户输入内容进行字数提示功能的实例代码
- TensorFlow安装及实例-(Ubuntu16.04.1 & Anaconda3)
- Dockerfiles介绍与编写实例
- vue 实现边输入边搜索功能的实例讲解
- Chromium网页输入事件处理机制简要介绍和学习计划
- mysql分区功能详细介绍,以及实例
- js中判断用户输入的值是否为空的简单实例
- Web Service单元测试工具实例介绍之SoapUI
- Java 代码优化过程的实例介绍
- 实例介绍Cocos2d-x物理引擎:使用关节