第四周翻译(《Database.System.Concepts》8.3 Decomposition Using Functional Dependencies)
2018-04-01 08:41
260 查看
Tip:参考前人翻译8.3 运用函数依赖进行分级 在8.1节中,我们了解存在一个规范方法,判断一个关系模式是否应该分解,而这个方法基于码和函数依赖的概念。而当讨论关系数据库设计的算法时,我们还需要针对任意的关系和其的模式进行讨论,而不只是讨论某些例子。回想第2章对关系模型的介绍,我们在这里对我们的表示法进行概述。通常来说,我们会用希腊字母来表示属性集(例如α)。我们还会用一个小写的罗马字母后面跟一个用一对圆括号括住的大写字母来表示关系模式(例如r(R))。我们会用表示法r(R)来表示该模式是关系r的,R表示属性集,但是当我们不关心关系的名称时常常简化我们的表示法而只用一个R。当然,一个关系模式可以是一个属性集,但是并非所有的属性集都是模式。当使用一个小写的希腊字母时,我们是指一个有可能是模式也可能不是模式的属性集。但当我们希望指明属性集一定要是一个模式时,就使用罗马字母。当属性集是一个超码时,我们用K表示它。而超码属于特殊的关系模式,因此我们使用术语应该是“K是r(R)的超码”。我们对关系使用小写的名字。而在我们的例子中,这些名字是企图有实际含义的(例如instructor),但是在我们的定义和算法中,我们使用单个字母,比如r。当然,一个关系在任意给定时间都有特定的值:我们将它看作一个实例并使用术语“r的实例”。当我们明显在讨论一个实例时,我们就可以仅用关系的名字(例如r)。8.3.1 码和函数依赖 当一个数据库对实际的一组实体和联系建模时,在现实生活中,数据上通常存在各种约束(规则)。例如,在一个大学的数据库中预计要保证的一些约束有:学生和老师通过他们的ID唯一标识。每个学生和老师只有一个名字。每个老师和学生只(主要)关联一个系。每个系只有一个预算值,并且只有一个关联的办公楼。一个关系满足所有这种实际约束的实例,称为关系的合法实例(legal instance);而在一个数据库的合法实例中所有关系实例都是合法实例。几种最常用的实际约束可以形式化地表示为码(超码、候选码以及主码),或者下面所定义的函数依赖。在2.3节中,曾经定义超码的概念为可以唯一标识关系中一条元组的一个或者多个属性的集合。在这里,重新表述该定义如下:令r(R)为一个关系模式。而R的子集K是r(R)的超码的条件是:在关系r(R)的任意合法实例中,对于r的实例中的所有元组对t1和t2总满足,若t1≠t2,则t1[K]≠t2[K]。换句话说,在关系r(R)的任意合法实例中没有两条元组在属性集K上可能具有相同的值。显然,如果r中没有两条元组在K上具有相同的值,那么r中一个K值唯一标记一条元组。又鉴于超码是能够唯一标识整条元组的属性集,函数依赖能使我们可以表达唯一标识某些属性的值的约束。而当考虑一个关系模式r(R)时,令α⊆R 且 β⊆R.。给定r(R)的一个实例,我们说这个实例满足(satisfy)函数依赖α→β的条件是:对实例中所有元组对t1和t2,若t1[α]=t2[α],则t1[β]=t2[β]。如果在r(R)的每个合法实例中都满足函数依赖α→β,我们就说该函数依赖在模式r(R)上成立(hold)。当使用函数依赖这一概念,我们说如果函数依赖K →R在r(R)上成立,则K是r(R)的一个超码。换句话说,如果对于r(R)的每个合法实例,对于实例中每个元组对t1和t2,凡是t1[K]=t2[K],总是会有t1[R]=t2[R](即t1=t2),那么K是一个超码。函数依赖使我们能够表示不用超码表示的约束。在8.1.2节中我们曾考虑模式:inst dept (ID, name, salary,dept_name, building, budget)在该模式中函数依赖dept_name → budget成立,因为对于每个系(由dept_name唯一标识)都存在唯一的预算数额。属性对(ID, dept_name)构成inst_dept 的一个超码,我们将这一事实记做:一个老师或者一个学生可以和多个系相关联,例如兼职教师或者辅修系。我们简化的大学模式只对每个老师或学生所关联的主系建模。一个实际的大学模式会在另外的关系中表现次要的关联。注意的是,当我们在这里假设关系为集合。SQL处理多集,并且SQL中声明一个属性集K为主码不仅需要当t1[K]和t2[K],t1=t2时,还需要没有重复的元组。SQL还要求K集中的属性不能赋予空值。 ID, dept_name→name, salary, building, budget我们将以两种方式使用函数依赖:1.判定关系的实例是否满足给定函数依赖集F。2.说明合法关系集上的约束。所以,当我们只关心满足给定函数依赖集的那些关系实例,如果我们希望只考虑模式R上满足函数依赖集F的关系,我们说F在r(R)上成立。
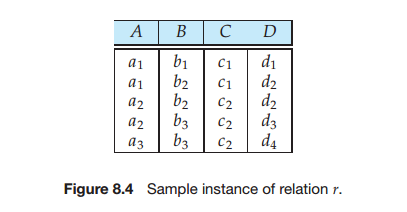
让我们考虑图8-4中的关系r的实例,研究它满足什么函数依赖。注意到A→C是满足的,存在两条元组的A值为a1。这些元组具有相同的C值,c1。同样的,A值为a2的两条元组具有相同的C值,c2。没有其他的元组对具有相同的A值。但是,函数依赖C→ A 是不满足的。而为了说明这一点,考虑元组t1=(a2,b3,c2,d3)和元组t2=(a3,b3,c2,d4)。这两条元组具有相同的C值,c2,但是它们两者间具有不同的A值,分别为a2和a3。所以,当我们找到一对元组t1和t2,使得t1[C]=t2[C]时,t1[A]≠t2[A]。
而有些函数依赖却是平凡的(trivial),因为它们在所有关系中都能满足。例如,A→ A在所有包含属性A的关系中满足。从字面上看函数依赖的定义,我们清楚,对所有满足t1[A]=t2[A]的元组t1和t2,有t1[A]=t2[A]。但是同样的,AB→ A也在所有包含属性A的关系中满足。一般来说,如果β⊆α,则形如α→β的函数依赖也是平凡的。
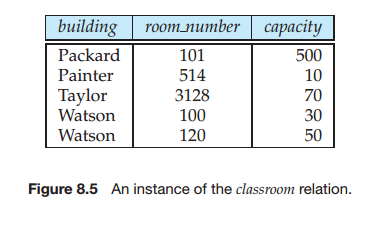
重要的是,要认识到一个关系实例可能满足某些函数依赖,它们并不需要在关系的模式上成立。比如在图8-5的classroom关系的实例中,我们发现room number→capacity是满足的。但是,我们相信,在实际生活中,不同建筑里的两个教室可以具有相同的房间号,但是并不具有相同的空间大小。所以,有时有可能会存在一个classroom关系的实例,不满足room number→capacity。所以,我们不需要将room number→capacity包含于classroom关系的模式上成立的函数依赖集中。然而,我们会希望函数依赖building, room number→capacity 在classroom模式上成立。
在给定关系r(R)上成立的函数依赖集中F中,有可能会推断出某些其他的函数依赖也一定会在该关系上成立。例如,给定模式r(A,B,C),如果函数依赖A→ B 和 B → C在r上成立,可以推出函数依赖A→ C也一定在r上成立。这就是因为,给定A的任意赋值,仅存在B的一个对应值,且对于B的那个值,只能存在C的一个对应值。所以我们稍后将在8.4.1节学习如何进行这样的推导。我们将使用F+号来表示F集合的闭包(closure),也就是能够从给定F集合推导出的所有函数依赖的集合。而显然,F+含F中所有的函数依赖。8.3.2 Boyce-Codd范式我们能够达到的比较满意的范式之一就是Boyce-Codd范式(Boyce–Codd normal form (BCNF).)。它删除了所有基于函数依赖而能发现的冗余,虽然,我们将在8.6节中看到,但是可能还是有其他类型的冗余保留。具有函数依赖集F的关系模式R属于BCNF的条件是,对F中所有形如α→β的函数依赖(其中α⊆R and β⊆R),在下面中至少有一项成立;α→ β是平凡的函数依赖(即,β ⊆α)。α是模式R的一个超码。一个数据库设计属于BCNF的条件是,构成该设计的关系模式集中于每个模式都属于BCNF。我们已经在8.1节中见过了不属于BCNF的关系模式的例子: Inst_dept (ID, name, salary, dept_name,building, budget)函数依赖dept_name→budget 在inst_dept上成立,但是dept_name并不是超码(因为一个系可以有多个不同的老师)。在8.1.2节中,我们看到把inst_dept分解为instructor和department是一个更好的设计。模式instructor属于BCNF。所有成立的非平凡的函数依赖,例如: ID→name, dept_name, salary在箭头的左侧包含ID,并且ID是instructor的一个超码(事实上,在这个例子中,是主码)。(也就是说,在不包含ID的另一侧上,对于name, dept_name, andsalary的任意组合不存在非平凡的函数依赖。)因此,instructor属于BCNF。类似地,department模式属于BCNF,因为所有成立的非平凡函数依赖,例如:Dept_name→building,budget在箭头的左侧包含dept_name,且dept_name是department的一个超码(和主码)。所以,department属于BCNF。 我们当前讲述分解不属于BCNF的模式的普遍规则:设R为不属于BCNF的一个模式。那么存在至少一个非平凡的函数依赖α→β,其中α不是R的超码。我们在设计里用以下两个模式取代R: (α∪β) (R−(β−α))在上面的inst_dept例子中,α= dept_name,β= ={building, budget},且inst_dept 被取代为; (α∪β) =(dept_name, building,budget) (R−(β−α))= (ID, name, dept_name,salary)在这个例子里,结果是β−α=β。我们同样需要像上述那样的表述规则,进而能够正确处理箭头两边都出现的属性的函数依赖。技术上的原因我们将在8.5.1节介绍。但当我们分解不属于BCNF的模式时,所产生的模式中可能有一个或者多个不属于BCNF。在这种情况下,需要进一步分解,而其最终结果是一个BCNF模式集合。8.3.3 BCNF和保持依赖 我们已经看到了多种表达数据库一致性约束的方式:主码约束、函数依赖、check约束、断言和触发器。但是在每次数据库更新时检查这些约束的开销就会很大,因此,把数据库设计成能够高效地检查约束是很有用的。特别注意的是,如果函数依赖的检验仅需要考虑一个关系就可以完成的话,那么检查这种约束的开销就很低,我们将会看到,在有些情况下,BCNF的分解会妨碍到某些函数依赖的高效检查。对此举个例子,假设我们对我们的大学机构做一个小的改动。在图7-15的设计中,一位学生只能有一位导师。这是从student到advisor的联系集advisor为多对一而推断出的。我们要做的“小”改动是一个老师只能和单个系关联,且一个学生可以有多个导师,但是一个给定的系中至少一位。
利用E-R图设计实现这个改动的一种方法是,把联系集advisor替换为实体集instructor、student和department的三元联系集dept_advisor,它是从{student,instructor}对到department多对一的,如图8-6所示。该E-R图指明了“一个学生可以有多位导师,但是对应一个给定的系最多只有一个”的约束。
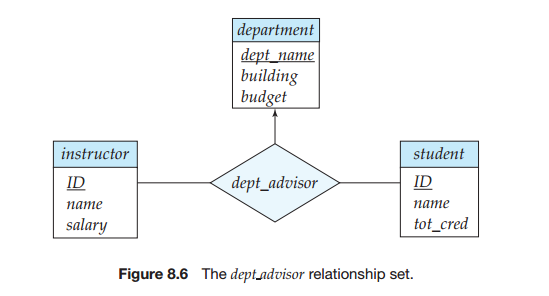
对应于新的E-R图,instructor、department和student的模式没有变。然而,从dept_advisor导出的模式现在为:Dept_advisor (s_ID, i_ID, dept_name)即使没有在E-R图中指明,但是假定我们有附加的约束“一位老师只能在一个系担任导师。”则下面的函数依赖在dept_advisor上成立: i_ID→dept_name S_ID, dept_name→i_ID而第一个函数依赖产生于我们的需求“一位教师只能在一个系担任导师”。第二个函数依赖则产生于我们的需求“对于一个给定的系,一个学生可以有至少一位导师”。注意的是,在这种设计中,每次一名老师参与一个dept_advisor联系的时候,我们需要重复一次系的名称。我们看到dept_advisor不属于BCNF,因为i_ID不是超码。根据BCNF分解规则,得到:(s-ID,i_ID)(i_ID,dept_name)上面的两个模式都属于BCNF。(但是事实上,你可以验证,按照定义任何只包含两个属性的模式都属于BCNF。)然而注意的是,在BCNF设计中,没有一个模式包含函数依赖s_ID,dept_namee→i_ID中出现的所有属性。因为我们的设计使得该函数依赖的强制实施时在计算上很困难,所以我们称我们的设计不是保持依赖的(dependency preserving)。又由于常常希望保持依赖,因此我们考虑另外一种比BCNF弱的范式,它允许我们保持依赖。该范式称为第三范式。 8.3.4 第三范式BCNF要求所有非平凡函数依赖都形如α→β,其中α为一个超码。第三范式(3NF)稍微放宽了这个约束,它允许左侧不是超码的某些非平凡函数依赖。在定义3NF之前,我们回想到候选码是最小的超码——任何真子集都不是超码的超码。要使具有函数依赖集F的关系模式R属于第三范式(third normalform)的条件是:对于F中所有形如α→β的函数依赖(其中α ⊆ 和 β ⊆ R),以下至少一项成立:α→β是一个平凡的函数依赖。α是R的一个超码。β—α中的每个属性A都包含于R的一个候选码中。注意上面的第三个条件并没有说单个候选码必须包含β—α中的所有属性:β—α中的每个属性A可能包含于不同的候选码中。在前两个条件与BCNF定义中的两个条件相同时。3NF定义中的第三个条件看起来就很不直观,而且它的用途也不是那么明显的。而从某种意义上,它代表BCNF条件的最小条件放宽,从而确保每一个模式都有保持依赖的3NF分解。它的用途在后面介绍3NF分解时会变得更清楚。注意任何满足BCNF的模式也同样满足3NF,因为它的每个函数依赖都将满足前两个条件中的一条。所以BCNF是比3NF更严格的范式。3NF的定义允许某些BCNF中不允许的函数依赖。只满足3NF定义中第三个条件的依赖α→β在BCNF中是不允许的,但在3NF中是允许的。现在让我们再次考虑联系集dept_advisor,它具有以下函数依赖:I_ID→dept_name S_ID, dept_name→i ID在8.3.3节中我们说函数依赖“i_ID → dept_name”导致dept_advisor模式不属于BCNF。需要注意的是这里α=i_ID,β =dept_name,和β−α =dept_name,由于函数依赖s_ID,dept_name →i_ID在dept_advisor上成立,于是属性dept_name包含于一个候选码中,因此dept_advisor属于3NF。但是从技术上来说,由于存在逻辑上蕴涵该依赖的其他依赖,所以属性在任何一个模式中都不完全出现的依赖也隐含地强制实施了。稍后我们将在8.4.5节讨论这个问题。你可能注意到我们跳过了第二范式。因为第二范式只有历史意义,已经不在实际中运用了。这些依赖是传递依赖(transitive dependencies)的例子(参见实践习题8.16)。3NF的原始定义就是由传递依赖而来的,我们所使用的定义与之等价却更容易理解。我们已经看到,当不存在保持依赖的BCNF设计时,必须在BCNF和3NF之间进行权衡。这些权衡将在8.5.4节中会详细讨论。 8.3.5 更高的范式在某些情况中,使用函数依赖分解模式可能不足以避免不必要的信息重复。需要考虑在instructor实体集定义中的小变化,我们为每个老师记录一组孩子名字以及一组电话号码。电话号码可以被多个人共享。因此,phone_number和child__name将是多值属性,并且根据我们从E-R设计生成模式的规则,我们会有两个模式,多值属性phone_number和child_name中每个属性对应一个模式:
(ID, child_name) (ID, phone_number)如果我们合并这些模式而得到 (ID,child_name, phone_number)我们就会发现这样的结果属于BCNF,因为只有平凡的函数依赖成立。所以我们可能认为这样的合并是个好主意。然而,通过考虑有两个孩子和两个电话号码的老师的例子,我们会发现这样的合并是一个坏主意。比如说,令ID为99999的老师有两个孩子,叫作“David”和“William”,以及有两个电话号码,512-555-1234和512-555-4321。在合并的模式中,我们必须为每个家属重复一次电话号码:(99999, David, 512-555-1234) (99999, David, 512-555-4321)(99999, William,512-555-1234)(99999, William,512-555-4321)而如果我们不重复电话号码,且只存储第一条和最后一条元组,我们就记录了家属名字和电话号码,但是结果却是,元组将暗指David对应于512-555-1234,而William对应于512-555-4321。我们知道,这是错误的。因为基于函数依赖的范式并不足以处理这样的情况,因此定义了另外的依赖和范式。而我们在8.6和8.7节对此进行讲述。
让我们考虑图8-4中的关系r的实例,研究它满足什么函数依赖。注意到A→C是满足的,存在两条元组的A值为a1。这些元组具有相同的C值,c1。同样的,A值为a2的两条元组具有相同的C值,c2。没有其他的元组对具有相同的A值。但是,函数依赖C→ A 是不满足的。而为了说明这一点,考虑元组t1=(a2,b3,c2,d3)和元组t2=(a3,b3,c2,d4)。这两条元组具有相同的C值,c2,但是它们两者间具有不同的A值,分别为a2和a3。所以,当我们找到一对元组t1和t2,使得t1[C]=t2[C]时,t1[A]≠t2[A]。
而有些函数依赖却是平凡的(trivial),因为它们在所有关系中都能满足。例如,A→ A在所有包含属性A的关系中满足。从字面上看函数依赖的定义,我们清楚,对所有满足t1[A]=t2[A]的元组t1和t2,有t1[A]=t2[A]。但是同样的,AB→ A也在所有包含属性A的关系中满足。一般来说,如果β⊆α,则形如α→β的函数依赖也是平凡的。
重要的是,要认识到一个关系实例可能满足某些函数依赖,它们并不需要在关系的模式上成立。比如在图8-5的classroom关系的实例中,我们发现room number→capacity是满足的。但是,我们相信,在实际生活中,不同建筑里的两个教室可以具有相同的房间号,但是并不具有相同的空间大小。所以,有时有可能会存在一个classroom关系的实例,不满足room number→capacity。所以,我们不需要将room number→capacity包含于classroom关系的模式上成立的函数依赖集中。然而,我们会希望函数依赖building, room number→capacity 在classroom模式上成立。
在给定关系r(R)上成立的函数依赖集中F中,有可能会推断出某些其他的函数依赖也一定会在该关系上成立。例如,给定模式r(A,B,C),如果函数依赖A→ B 和 B → C在r上成立,可以推出函数依赖A→ C也一定在r上成立。这就是因为,给定A的任意赋值,仅存在B的一个对应值,且对于B的那个值,只能存在C的一个对应值。所以我们稍后将在8.4.1节学习如何进行这样的推导。我们将使用F+号来表示F集合的闭包(closure),也就是能够从给定F集合推导出的所有函数依赖的集合。而显然,F+含F中所有的函数依赖。8.3.2 Boyce-Codd范式我们能够达到的比较满意的范式之一就是Boyce-Codd范式(Boyce–Codd normal form (BCNF).)。它删除了所有基于函数依赖而能发现的冗余,虽然,我们将在8.6节中看到,但是可能还是有其他类型的冗余保留。具有函数依赖集F的关系模式R属于BCNF的条件是,对F中所有形如α→β的函数依赖(其中α⊆R and β⊆R),在下面中至少有一项成立;α→ β是平凡的函数依赖(即,β ⊆α)。α是模式R的一个超码。一个数据库设计属于BCNF的条件是,构成该设计的关系模式集中于每个模式都属于BCNF。我们已经在8.1节中见过了不属于BCNF的关系模式的例子: Inst_dept (ID, name, salary, dept_name,building, budget)函数依赖dept_name→budget 在inst_dept上成立,但是dept_name并不是超码(因为一个系可以有多个不同的老师)。在8.1.2节中,我们看到把inst_dept分解为instructor和department是一个更好的设计。模式instructor属于BCNF。所有成立的非平凡的函数依赖,例如: ID→name, dept_name, salary在箭头的左侧包含ID,并且ID是instructor的一个超码(事实上,在这个例子中,是主码)。(也就是说,在不包含ID的另一侧上,对于name, dept_name, andsalary的任意组合不存在非平凡的函数依赖。)因此,instructor属于BCNF。类似地,department模式属于BCNF,因为所有成立的非平凡函数依赖,例如:Dept_name→building,budget在箭头的左侧包含dept_name,且dept_name是department的一个超码(和主码)。所以,department属于BCNF。 我们当前讲述分解不属于BCNF的模式的普遍规则:设R为不属于BCNF的一个模式。那么存在至少一个非平凡的函数依赖α→β,其中α不是R的超码。我们在设计里用以下两个模式取代R: (α∪β) (R−(β−α))在上面的inst_dept例子中,α= dept_name,β= ={building, budget},且inst_dept 被取代为; (α∪β) =(dept_name, building,budget) (R−(β−α))= (ID, name, dept_name,salary)在这个例子里,结果是β−α=β。我们同样需要像上述那样的表述规则,进而能够正确处理箭头两边都出现的属性的函数依赖。技术上的原因我们将在8.5.1节介绍。但当我们分解不属于BCNF的模式时,所产生的模式中可能有一个或者多个不属于BCNF。在这种情况下,需要进一步分解,而其最终结果是一个BCNF模式集合。8.3.3 BCNF和保持依赖 我们已经看到了多种表达数据库一致性约束的方式:主码约束、函数依赖、check约束、断言和触发器。但是在每次数据库更新时检查这些约束的开销就会很大,因此,把数据库设计成能够高效地检查约束是很有用的。特别注意的是,如果函数依赖的检验仅需要考虑一个关系就可以完成的话,那么检查这种约束的开销就很低,我们将会看到,在有些情况下,BCNF的分解会妨碍到某些函数依赖的高效检查。对此举个例子,假设我们对我们的大学机构做一个小的改动。在图7-15的设计中,一位学生只能有一位导师。这是从student到advisor的联系集advisor为多对一而推断出的。我们要做的“小”改动是一个老师只能和单个系关联,且一个学生可以有多个导师,但是一个给定的系中至少一位。
利用E-R图设计实现这个改动的一种方法是,把联系集advisor替换为实体集instructor、student和department的三元联系集dept_advisor,它是从{student,instructor}对到department多对一的,如图8-6所示。该E-R图指明了“一个学生可以有多位导师,但是对应一个给定的系最多只有一个”的约束。
对应于新的E-R图,instructor、department和student的模式没有变。然而,从dept_advisor导出的模式现在为:Dept_advisor (s_ID, i_ID, dept_name)即使没有在E-R图中指明,但是假定我们有附加的约束“一位老师只能在一个系担任导师。”则下面的函数依赖在dept_advisor上成立: i_ID→dept_name S_ID, dept_name→i_ID而第一个函数依赖产生于我们的需求“一位教师只能在一个系担任导师”。第二个函数依赖则产生于我们的需求“对于一个给定的系,一个学生可以有至少一位导师”。注意的是,在这种设计中,每次一名老师参与一个dept_advisor联系的时候,我们需要重复一次系的名称。我们看到dept_advisor不属于BCNF,因为i_ID不是超码。根据BCNF分解规则,得到:(s-ID,i_ID)(i_ID,dept_name)上面的两个模式都属于BCNF。(但是事实上,你可以验证,按照定义任何只包含两个属性的模式都属于BCNF。)然而注意的是,在BCNF设计中,没有一个模式包含函数依赖s_ID,dept_namee→i_ID中出现的所有属性。因为我们的设计使得该函数依赖的强制实施时在计算上很困难,所以我们称我们的设计不是保持依赖的(dependency preserving)。又由于常常希望保持依赖,因此我们考虑另外一种比BCNF弱的范式,它允许我们保持依赖。该范式称为第三范式。 8.3.4 第三范式BCNF要求所有非平凡函数依赖都形如α→β,其中α为一个超码。第三范式(3NF)稍微放宽了这个约束,它允许左侧不是超码的某些非平凡函数依赖。在定义3NF之前,我们回想到候选码是最小的超码——任何真子集都不是超码的超码。要使具有函数依赖集F的关系模式R属于第三范式(third normalform)的条件是:对于F中所有形如α→β的函数依赖(其中α ⊆ 和 β ⊆ R),以下至少一项成立:α→β是一个平凡的函数依赖。α是R的一个超码。β—α中的每个属性A都包含于R的一个候选码中。注意上面的第三个条件并没有说单个候选码必须包含β—α中的所有属性:β—α中的每个属性A可能包含于不同的候选码中。在前两个条件与BCNF定义中的两个条件相同时。3NF定义中的第三个条件看起来就很不直观,而且它的用途也不是那么明显的。而从某种意义上,它代表BCNF条件的最小条件放宽,从而确保每一个模式都有保持依赖的3NF分解。它的用途在后面介绍3NF分解时会变得更清楚。注意任何满足BCNF的模式也同样满足3NF,因为它的每个函数依赖都将满足前两个条件中的一条。所以BCNF是比3NF更严格的范式。3NF的定义允许某些BCNF中不允许的函数依赖。只满足3NF定义中第三个条件的依赖α→β在BCNF中是不允许的,但在3NF中是允许的。现在让我们再次考虑联系集dept_advisor,它具有以下函数依赖:I_ID→dept_name S_ID, dept_name→i ID在8.3.3节中我们说函数依赖“i_ID → dept_name”导致dept_advisor模式不属于BCNF。需要注意的是这里α=i_ID,β =dept_name,和β−α =dept_name,由于函数依赖s_ID,dept_name →i_ID在dept_advisor上成立,于是属性dept_name包含于一个候选码中,因此dept_advisor属于3NF。但是从技术上来说,由于存在逻辑上蕴涵该依赖的其他依赖,所以属性在任何一个模式中都不完全出现的依赖也隐含地强制实施了。稍后我们将在8.4.5节讨论这个问题。你可能注意到我们跳过了第二范式。因为第二范式只有历史意义,已经不在实际中运用了。这些依赖是传递依赖(transitive dependencies)的例子(参见实践习题8.16)。3NF的原始定义就是由传递依赖而来的,我们所使用的定义与之等价却更容易理解。我们已经看到,当不存在保持依赖的BCNF设计时,必须在BCNF和3NF之间进行权衡。这些权衡将在8.5.4节中会详细讨论。 8.3.5 更高的范式在某些情况中,使用函数依赖分解模式可能不足以避免不必要的信息重复。需要考虑在instructor实体集定义中的小变化,我们为每个老师记录一组孩子名字以及一组电话号码。电话号码可以被多个人共享。因此,phone_number和child__name将是多值属性,并且根据我们从E-R设计生成模式的规则,我们会有两个模式,多值属性phone_number和child_name中每个属性对应一个模式:
(ID, child_name) (ID, phone_number)如果我们合并这些模式而得到 (ID,child_name, phone_number)我们就会发现这样的结果属于BCNF,因为只有平凡的函数依赖成立。所以我们可能认为这样的合并是个好主意。然而,通过考虑有两个孩子和两个电话号码的老师的例子,我们会发现这样的合并是一个坏主意。比如说,令ID为99999的老师有两个孩子,叫作“David”和“William”,以及有两个电话号码,512-555-1234和512-555-4321。在合并的模式中,我们必须为每个家属重复一次电话号码:(99999, David, 512-555-1234) (99999, David, 512-555-4321)(99999, William,512-555-1234)(99999, William,512-555-4321)而如果我们不重复电话号码,且只存储第一条和最后一条元组,我们就记录了家属名字和电话号码,但是结果却是,元组将暗指David对应于512-555-1234,而William对应于512-555-4321。我们知道,这是错误的。因为基于函数依赖的范式并不足以处理这样的情况,因此定义了另外的依赖和范式。而我们在8.6和8.7节对此进行讲述。

相关文章推荐
- 翻译 《Database.System.Concepts》的8.3 Decomposition Using Functional Dependencies
- 《Database.System.Concepts》的8.3 Decomposition Using Functional Dependencies P329-338翻译
- Database.System.Concepts(6th.Edition.2010)-8.3
- 项目管理实践【六】自动同步数据库【Using Visual Studio with Source Control System to synchronize database automatically】
- 《Database.System.Concepts》【2.1 Structure of Relational Databases】至【2.3 Keys】
- 项目管理实践【六】自动同步数据库【Using Visual Studio with Source Control System to synchronize database automaticall
- 引用不到using System.Data.Entity.Database;(MVC3)
- 《Database.System.Concepts》(P329~338)
- 项目管理实践【六】自动同步数据库【Using Visual Studio with Source Control System to synchronize database automaticall
- 引用不到using System.Data.Entity.Database;(MVC3)
- 《Database.System.Concepts》2.1 Structure of Relational Databases-2.3 Keys
- DATABASE SYSTEM CONCEPTS4.8
- 项目管理实践【六】自动同步数据库【Using Visual Studio with Source Control System to synchronize database automatically】
- ScottGu博客之翻译-Linq to Sql第7部分--用存储过程更新数据库--LINQ to SQL (Part 7 - Updating our Database using Stored Procedures)
- 无法 using System.Data.Entity.Database的问题
- 引用不到using System.Data.Entity.Database;(MVC3)
- 项目管理实践【六】自动同步数据库【Using Visual Studio with Source Control System to synchronize database automatically】
- 项目管理实践【六】自动同步数据库【Using Visual Studio with Source Control System to synchronize database automatically】
- 项目管理实践【六】自动同步数据库【Using Visual Studio with Source Control System to synchronize database automaticall
- 项目管理实践【六】自动同步数据库【Using Visual Studio with Source Control System to synchronize database automatically】