【Udacity】3,2,13,因子变量
2018-03-31 15:56
232 查看
因子变量
使用数据reggit.csv,谁是reddit* 导入数据
> getwd()
[1] "C:/Users/Administrator/Documents"
> setwd('C:/Users/Administrator/Downloads')
> reggit <- read.csv('reddit.csv')使用搅拌命令,str命令–str(data)
运行搅拌命令,我们看到这里有很多数据,大多数变量都有一种因数(因数就是facter)。因数一种类别变量,具有不同的偏好和级别。
例子之一就是就业状态,这个变量有多种不同的级别,比如全职就业或兼职就业或者无工作。
str(data)
function (..., list = character(), package = NULL, lib.loc = NULL, verbose = getOption("verbose"), envir = .GlobalEnv)
> str(reggit)
'data.frame': 32754 obs. of 14 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ gender : int 0 0 1 0 1 0 0 0 0 0 ...
$ age.range : Factor w/ 7 levels "18-24","25-34",..: 2 2 1 2 2 2 2 1 3 2 ...
$ marital.status : Factor w/ 6 levels "Engaged","Forever Alone",..: NA NA NA NA NA 4 3 4 4 3 ...
$ employment.status: Factor w/ 6 levels "Employed full time",..: 1 1 2 2 1 1 1 4 1 2 ...
$ military.service : Factor w/ 2 levels "No","Yes": NA NA NA NA NA 1 1 1 1 1 ...
$ children : Factor w/ 2 levels "No","Yes": 1 1 1 1 1 1 1 1 1 1 ...
$ education : Factor w/ 7 levels "Associate degree",..: 2 2 5 2 2 2 5 2 2 5 ...
$ country : Factor w/ 439 levels " Canada"," Canada eh",..: 394 394 394 394 394 394 125 394 394 125 ...
$ state : Factor w/ 53 levels "","Alabama","Alaska",..: 33 33 48 33 6 33 1 6 33 1 ...
$ income.range : Factor w/ 8 levels "$100,000 - $149,999",..: 2 2 8 2 7 2 NA 7 2 7 ...
$ fav.reddit : Factor w/ 1834 levels "","'home' page (or front page if you prefer)",..: 720 691 1511 1528 188 691 1318 571 1629 1 ...
$ dog.cat : Factor w/ 3 levels "I like cats.",..: NA NA NA NA NA 2 2 2 1 1 ...
$ cheese : Factor w/ 11 levels "American","Brie",..: NA NA NA NA NA 3 3 1 10 7 ...针对以上不同因子,拿就业状态举例,我们可能感兴趣的是,每个就业状态组中有多少人。我们可以将变量制成表,莞城每个组中的人数。
table(reggit$employment.status) Employed full time Freelance Not employed and not looking for work 14814 1948 682 Not employed, but looking for work Retired Student 2087 85 12987
通过在我们的运行框架上运行汇总命令,可以得到一些计数以及其它数据点。
summary(reggit) id gender age.range marital.status Min. : 1 Min. :0.0000 18-24 :15802 Engaged : 1109 1st Qu.: 8189 1st Qu.:0.0000 25-34 :11575 Forever Alone : 5850 Median :16380 Median :0.0000 Under 18: 2330 In a relationship : 9828 Mean :16379 Mean :0.1885 35-44 : 2257 Married/civil union/domestic partnership: 5490 3rd Qu.:24568 3rd Qu.:0.0000 45-54 : 502 Single :10428 Max. :32756 Max. :1.0000 (Other) : 200 Widowed : 44 NA's :201 NA's : 88 NA's : 5 employment.status military.service children education Employed full time :14814 No :30526 No :27488 Bachelor's degree :11046 Freelance : 1948 Yes : 2223 Yes : 5047 Some college : 9600 Not employed and not looking for work: 682 NA's: 5 NA's: 219 Graduate or professional degree : 4722 Not employed, but looking for work : 2087 High school graduate or equivalent: 3272 Retired : 85 Some high school : 1924 Student :12987 (Other) : 2046 NA's : 151 NA's : 144 country state income.range fav.reddit dog.cat United States :20967 :11908 Under $20,000 :7892 : 4335 I like cats. :11156 Canada : 2888 California: 3401 $50,000 - $69,999 :4133 askreddit : 2123 I like dogs. :17151 United Kingdom: 1782 Texas : 1541 $70,000 - $99,999 :4101 fffffffuuuuuuuuuuuu: 1746 I like turtles.: 4442 Australia : 1051 New York : 1418 $100,000 - $149,999:3522 pics : 1651 NA's : 5 Germany : 407 Illinois : 976 $20,000 - $29,999 :3206 trees : 1311 (Other) : 5482 Washington: 910 (Other) :8285 (Other) :21562 NA's : 177 (Other) :12600 NA's :1615 NA's : 26 cheese Other :6563 Cheddar :6102 Brie :3742 Provolone:3456 Swiss :3214 (Other) :9672 NA's : 5
注:除了因子变量之外,还有其他的数据类型,比如列表和矩阵。详细数据类型介绍,参考链接:[]https://www.statmethods.net/input/datatypes.html]
有序因子
(有序因子)深入观察这些因数变量,这里重点关注age.range变量,注意它表示,因数变量有7个不同的级别。$ age.range : Factor w/ 7 levels "18-24","25-34",..: 2 2 1 2 2 2 2 1 3 2 ...
仔细观察变量的级别,方法是键入命令级别levels
levels(reggit$age.range) [1] "18-24" "25-34" "35-44" "45-54" "55-64" "65 or Above" "Under 18"
如果想查看每个级别中的用户数,这里讲用ggplot2程序包,和附带的qplot函数来创建图形。
library(ggplot2) Warning message: 程辑包‘ggplot2’是用R版本3.4.4 来建造的 > qplot(data=reggit,x=age.range)
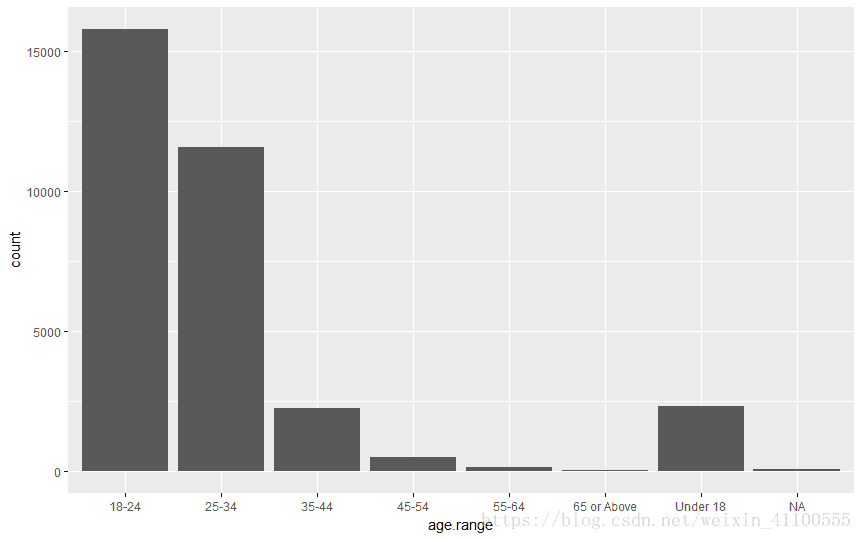
注:这里年纪分组未按照顺序排列,可以考虑让年纪分组按照顺序排列的函数
设置有序因子的水平
学习如何设置和排列因子水平设置级别解决排序问题
#设置级别
reggit$age.range <- ordered(reggit$age.range,levels = c("Under 18","18-24","25-34","35-44","45-54","55-64","65 or Above"))
#绘图
qplot(data=reggit,x=age.range)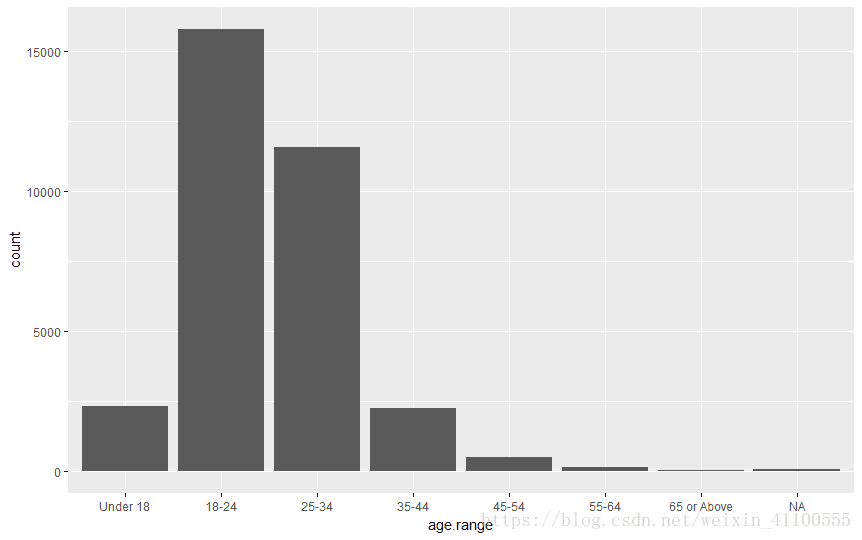
使用因数功能(factor)解决
> reggit$age.range <- factor(reggit$age.range,levels = c("Under 18","18-24","25-34","35-44","45-54","55-64","65 or Above"),ordered = T)
> qplot(data=reggit,x=age.range)代码输出结果和上面一样。

相关文章推荐
- Vim技能修炼教程(13) - 变量
- python--因子变量转换为哑变量
- Daily-C-Study(13):c语言变量及命名
- R 如何给因子的类型变量修改元素
- 笨办法学python习题13 参数、解包和变量
- 【机器学习】SVM学习(五):松弛变量与惩罚因子
- 改善C++ 程序的150个建议学习之建议13:掌握变量定义的位置与时机
- 松弛变量与惩罚因子
- [译]Stairway to Integration Services Level 13 - SSIS 变量回顾
- 13、函数名和变量名的命名
- Learn Python The Hard Way学习(13) - 参数,解包,变量
- 7_13:验证longjmp后变量的值
- 13、ubuntu 下设置交叉编译工具链的环境变量
- 笨方法学Python 习题 13: 参数、解包、变量
- SVM 学习 之 松弛变量和惩罚因子
- C++学习日记13——递归、内联、函数重载、变量的作用域和存储类型
- 13 JavaScript基础之--变量声明提升和预解析
- Learning Spark笔记13-Broadcast Variables(传播变量)
- SQL*Plus 系统变量之13 - COPYTYPECHECK