带你写爬虫(python)第二篇----抓取网易云音乐下面的评论(API方式)
2018-03-31 14:01
891 查看
抓取网易云音乐《大学无疆》的评论
一直喜欢使用网易云音乐,网易云歌曲下面的评论给其加分不少,所以这一篇来写一下怎么抓取歌曲下面的评论。准备工作
- 目标网页:http://music.163.com/#/song?id=520458203(歌曲《大学无疆》)
- API地址:http://music.163.com/api/v1/resource/comments/R_SO_4_520458203
- 开发工具:pycharm
- Python版本:3.6.4
- 所需库:请求库requests,解析库json
爬取过程分析
第一步:根据API获取信息
第二步:解析JSON数据
第三步:使用多进程池获取每一页数据
第一步:抓取页面并分析
我们直接用谷歌浏览器打开目标网页,我们所需要的数据如下所示
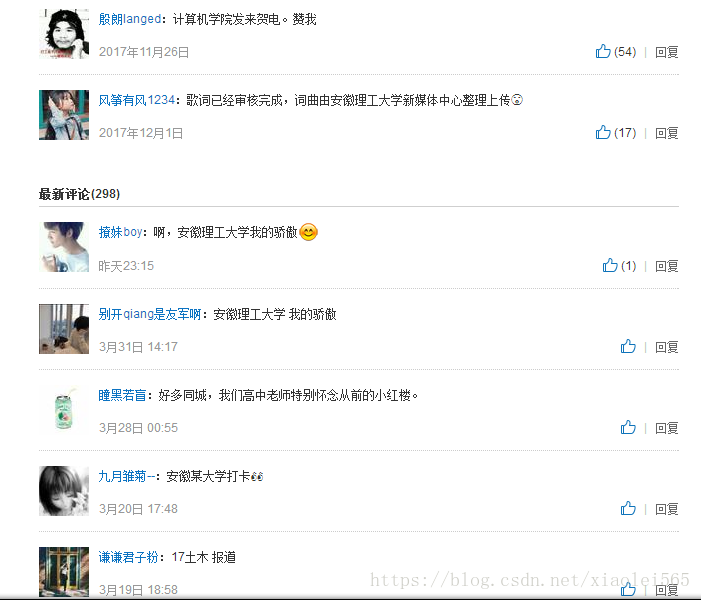
按F12打开开发者工具,查看网页中评论的加载情况,找了一圈发现,网易云并没有很简单的直接在网页中显示评论,而是使用AjAx的异步加载方式,点击NetWork,勾选Preview log,选择XHR,我们可以看到如下图所示,我们点击R_SO_4_520458203?csrf_token=这一个Name可以很容易看到评论数据就是在这个请求中加载出来的。
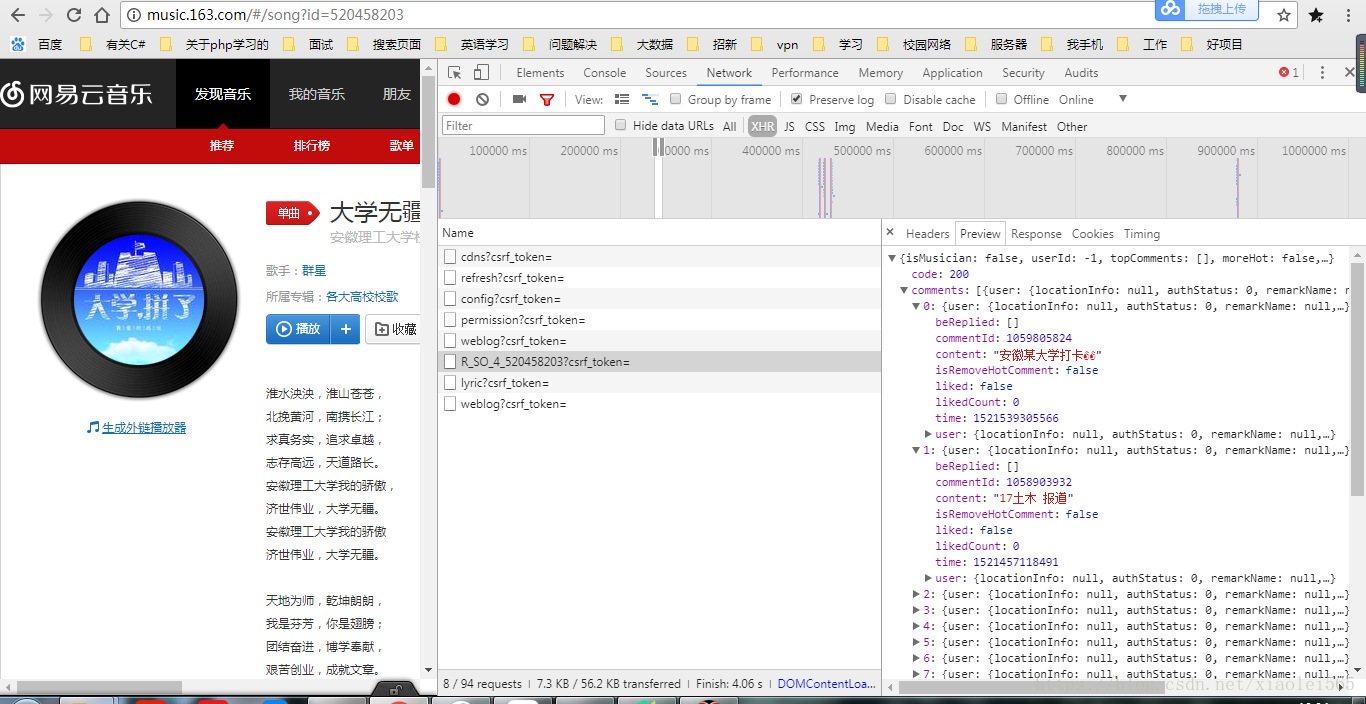
从上图中可以明显看出请求地址是
http://music.163.com/weapi/v1/resource/comments/R_SO_4_520458203?csrf_token=
数据传递方式是POST
然后我们选择Header,直接拖到下面看FormData,如下图所示
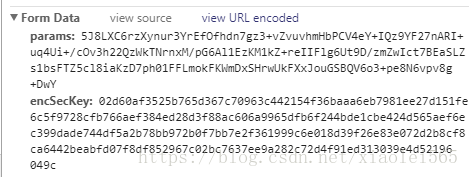
这也就是说明,POST方式传输了params和ensSecKey两个参数,明显有加密在里面,这也说明了网易云音乐对反扒做了一定的处理,因为对加密这一部分学习不深,我进行到这感觉进行不下去了,于是去知乎搜到了一个比较好理解的解密方法,传送门:https://www.zhihu.com/question/36081767(选择热门回答中的平胸小仙女和洛克的回答),我一想,这TM做个爬虫这么难啊,还要解谜,算了,不做了,结果发现天无绝人之路,我找到了一个不用解密的评论请求地址,在此感谢知乎:肖飞,传送门:如何爬网易云音乐的评论数? - 肖飞的回答 - 知乎
不加密请求地址:
http://music.163.com/api/v1/resource/comments/R_SO_4_520458203
后面的数字为需要爬取的音乐的ID。下一篇我们介绍直接解密的方法抓取
第二步:抓取页面并解析
首先导入对应的库
import requests from requests.exceptions import RequestException from urllib.parse import urlencode import json from multiprocessing import Pool#多进程池
再定义第一个函数get_response(),用来抓取页面
def get_response(offset,limit):
#参数
para = {
'offset':offset,#页数
'limit':limit#总数限制
}
# 歌曲id
musicid = "520458203" # 《大学无疆》
#歌曲api地址
musicurl = "http://music.163.com/api/v1/resource/comments/R_SO_4_"+musicid+"?"+urlencode(para)
#头结构
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'vjuids=-13ac1c39b.1620457fd8f.0.074295280a4d9; vjlast=1520491298.1520491298.30; _ntes_nnid=3b6a8927fa622b80507863f45a3ace05,1520491298273; _ntes_nuid=3b6a8927fa622b80507863f45a3ace05; vinfo_n_f_l_n3=054cb7c136982ebc.1.0.1520491298299.0.1520491319539; __utma=94650624.1983697143.1521098920.1521794858.1522041716.3; __utmz=94650624.1521794858.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; JSESSIONID-WYYY=FYtmJTTpVwmbihVrUad6u76CKxuzXZnfYyPZfK9bi%5CarU936rIdoIiVU50pfQ6JwjGgBvSyZO0%2FR%2BcoboKdPuMztgHCJwzyIgx1ON4v%2BJ2mOvARluNGpRo6lmhA%5CfcfCd3EwdS88sPgxpiiXN%5C6HZZEMQdNRSaHJlcN%5CXY657Faklqdh%3A1522053962445; _iuqxldmzr_=32',
'Host':'music.163.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
}
#代理IP
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197'
}
try:
#用post方式接收数据
response = requests.post(musicurl,headers=headers,proxies=proxies)
if response.status_code == 200:
return response.content
except RequestException:
print("访问出错")然后定义一个解析函数parse_return(),由于这个链接返回的是json数据,所以这个解析比较简单
def parse_return(html):
data = json.loads(html)#将返回的值格式化为json
if data.get('hotComments'):
hotcomm = data['hotComments']
print('--------------------------------------------------------------这是热门评论-------------------------------------------------------------------------------')
for hotitem in hotcomm:
hotdata = {
'用户名': hotitem['user']['nickname'],
'用户头像': hotitem['user']['avatarUrl'],
'content': hotitem['content'],
'赞':hotitem['likedCount']
}
print(hotdata)
print('------------------------------------------------------------------------------------------------------------------------------------------------------------')
# else:
# print('--------------------------------------------------')
if data.get('comments'):
comm = data['comments']
for item in comm:
data = {
'用户名': item['user']['nickname'],
'用户头像': item['user']['avatarUrl'],
'content': item['content'].replace('\r', ' '),
'赞': item['likedCount']
}
print(data)
print('-------------------------------------------------------------------------------------------------------------------------------------------------------------')然后创建main函数
def main(offset): gethtml = get_response(offset,200) parse_return(gethtml)
使用多进程方法抓取全部页面
if __name__ == '__main__': #多进程池 groups = [x*20 for x in range(0,20)] pool = Pool() pool.map(main,groups) #普通循环方法 # for x in range(0,20): # main(x*20)
抓取结果如下
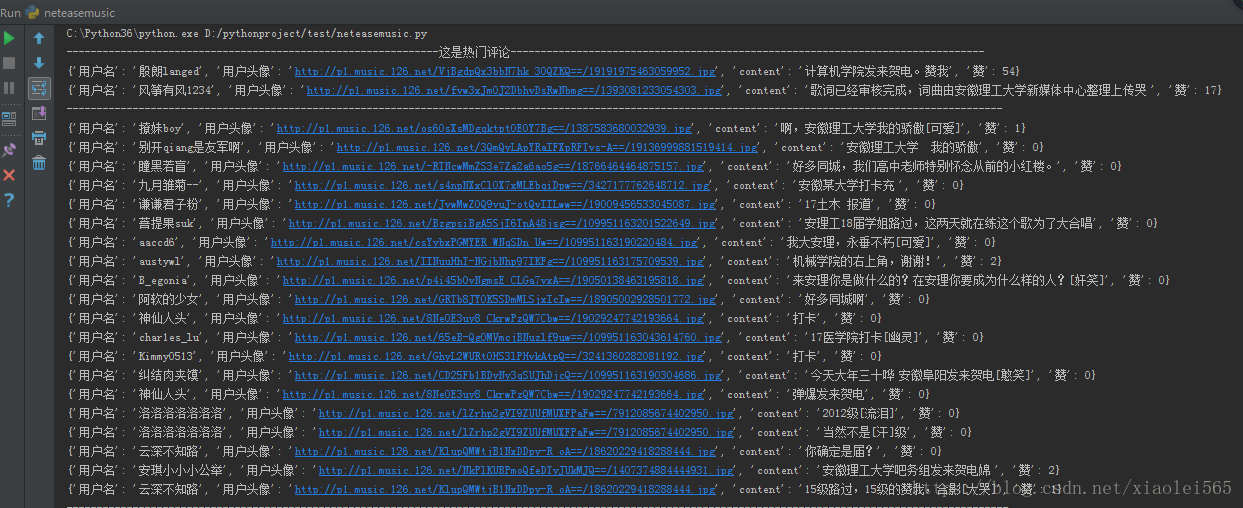
下面贴出全部代码,可以直接运行,只做学习使用
# -*- coding: utf-8 -*-
# @Time : 2018/3/15 15:27
# @Author : XueLei
# @Site :
# @File : neteasemusic.py
# @Software: PyCharm
#抓取某一首歌下面的评论
import requests from requests.exceptions import RequestException from urllib.parse import urlencode import json from multiprocessing import Pool#多进程池
def get_response(offset,limit):
#参数
para = {
'offset':offset,#页数
'limit':limit#总数限制
}
# 歌曲id
musicid = "520458203" # 《大学无疆》
#歌曲api地址
musicurl = "http://music.163.com/api/v1/resource/comments/R_SO_4_"+musicid+"?"+urlencode(para)
#头结构
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'vjuids=-13ac1c39b.1620457fd8f.0.074295280a4d9; vjlast=1520491298.1520491298.30; _ntes_nnid=3b6a8927fa622b80507863f45a3ace05,1520491298273; _ntes_nuid=3b6a8927fa622b80507863f45a3ace05; vinfo_n_f_l_n3=054cb7c136982ebc.1.0.1520491298299.0.1520491319539; __utma=94650624.1983697143.1521098920.1521794858.1522041716.3; __utmz=94650624.1521794858.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; JSESSIONID-WYYY=FYtmJTTpVwmbihVrUad6u76CKxuzXZnfYyPZfK9bi%5CarU936rIdoIiVU50pfQ6JwjGgBvSyZO0%2FR%2BcoboKdPuMztgHCJwzyIgx1ON4v%2BJ2mOvARluNGpRo6lmhA%5CfcfCd3EwdS88sPgxpiiXN%5C6HZZEMQdNRSaHJlcN%5CXY657Faklqdh%3A1522053962445; _iuqxldmzr_=32',
'Host':'music.163.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
}
#代理IP
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197'
}
try:
response = requests.post(musicurl,headers=headers,proxies=proxies)
if response.status_code == 200:
return response.content
except RequestException:
print("访问出错")
#解析返回页
def parse_return(html): data = json.loads(html)#将返回的值格式化为json if data.get('hotComments'): hotcomm = data['hotComments'] print('--------------------------------------------------------------这是热门评论-------------------------------------------------------------------------------') for hotitem in hotcomm: hotdata = { '用户名': hotitem['user']['nickname'], '用户头像': hotitem['user']['avatarUrl'], 'content': hotitem['content'], '赞':hotitem['likedCount'] } print(hotdata) print('------------------------------------------------------------------------------------------------------------------------------------------------------------') # else: # print('--------------------------------------------------') if data.get('comments'): comm = data['comments'] for item in comm: data = { '用户名': item['user']['nickname'], '用户头像': item['user']['avatarUrl'], 'content': item['content'].replace('\r', ' '), '赞': item['likedCount'] } print(data) print('-------------------------------------------------------------------------------------------------------------------------------------------------------------')
def main(offset): gethtml = get_response(offset,200) parse_return(gethtml)
if __name__ == '__main__':
# groups = [x*20 for x in range(0,20)]
# pool = Pool()
# pool.map(main,groups)
for x in range(0,20):
main(x*20)

相关文章推荐
- Python3实战之爬虫抓取网易云音乐的热门评论
- 使用爬虫抓取网易云音乐热门评论生成好玩的词云
- 关于利用Python无法直接抓取全部网易云音乐评论时怎么解决
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第二篇)
- 【python爬虫】通过python多线程的抓取新浪新闻的标题时间评论信息
- Python爬虫,抓取淘宝商品评论内容
- python爬虫----网易云音乐之热门评论
- Python爬虫:十分钟实现从数据抓取到数据API提供
- [置顶] [爬虫]使用python抓取京东全站数据(商品,店铺,分类,评论)
- Python3爬虫抓取网易云音乐热评实战
- python写爬虫2-数据抓取的三种方式
- Python爬虫入门-fiddler抓取手机新闻评论
- python爬虫selenium+firefox抓取京东商品评论
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
- python实现爬虫抓取段子
- python爬虫 前程无忧网页抓取
- python网页爬虫之列车时刻表的抓取-完整的python脚本
- 我的第一个爬虫程序:利用Python抓取网页上的信息
- 爬虫-python调用百度API/requests
- Python爬虫实践:从中文歌词库抓取歌词