Tensorflow实现简单的图像分类器
2018-03-30 16:34
399 查看
一个简单的Tensorflow图片分类器,数据集是iris数据集。两个脚本premade_estimator.py分类器脚本、iris_data.py处理数据的脚本。
Premade_estimator.py脚本分析如下
运行premade_estimator.py脚本,可以得到如下的结果
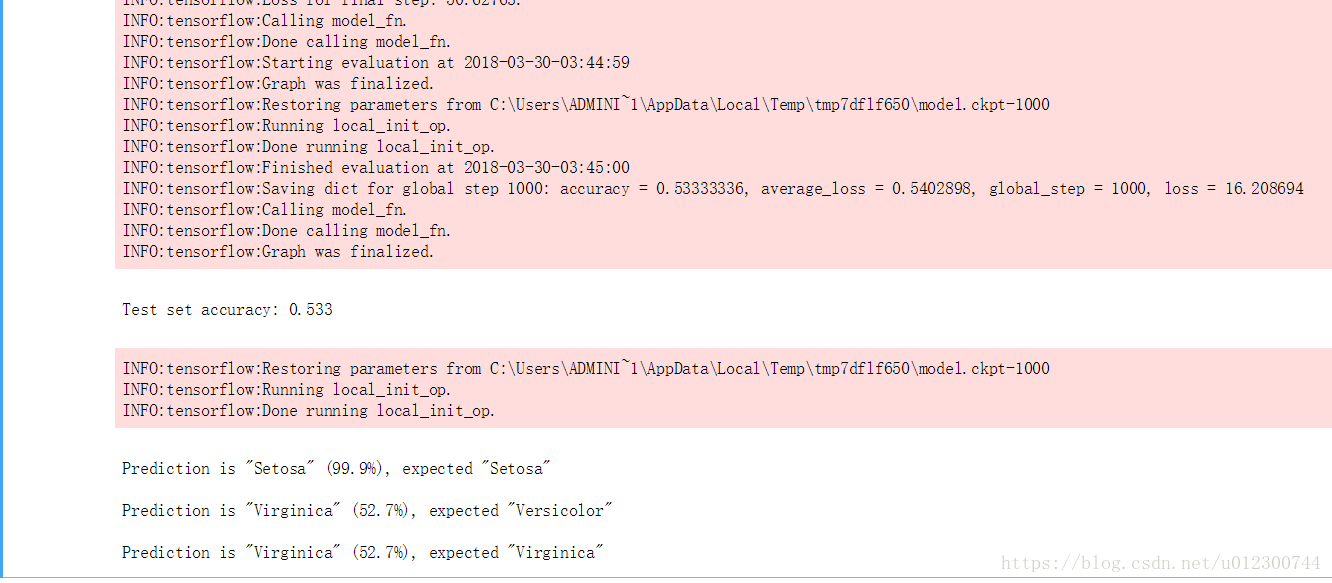
可以看出训练出的模型对predict_x中的三种图像做出了很好的分类。
#iris_data.py 下载数据集,并且处理数据集
import pandas as pd
import tensorflow as tf
# iris数据集的下载URL
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
TEST_URL = "http://download.tensorflow.org/data/iris_test.csv"
# iris数据集5个列的命名规则
CSV_COLUMN_NAMES = ['SepalLength', 'SepalWidth',
'PetalLength', 'PetalWidth', 'Species']
#花朵分成三个类
SPECIES = ['Setosa', 'Versicolor', 'Virginica']
# 下载数据集返回数据集的文件所在路径,默认~/.keras/datasets目录下
def maybe_download():
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1], TRAIN_URL)
# print(train_path)
test_path = tf.keras.utils.get_file(TEST_URL.split('/')[-1], TEST_URL)
# print(test_path)
return train_path, test_path
# 读取iris数据集的csv文件,并且制作(X,Y)形式的训练集和验证集
def load_data(y_name='Species'):
"""Returns the iris dataset as (train_x, train_y), (test_x, test_y)."""
train_path, test_path = maybe_download()
train = pd.read_csv(train_path, names=CSV_COLUMN_NAMES, header=0)
train_x, train_y = train, train.pop(y_name)
test = pd.read_csv(test_path, names=CSV_COLUMN_NAMES, header=0)
test_x, test_y = test, test.pop(y_name)
return (train_x, train_y), (test_x, test_y)
# 训练集输入
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# Return the dataset.
return dataset
# 验证集输入
def eval_input_fn(features, labels, batch_size):
"""An in
af36
put function for evaluation or prediction"""
features=dict(features)
if labels is None:
# No labels, use only features.
inputs = features
else:
inputs = (features, labels)
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices(inputs)
# Batch the examples
assert batch_size is not None, "batch_size must not be None"
dataset = dataset.batch(batch_size)
# Return the dataset.
return dataset
# The remainder of this file contains a simple example of a csv parser,
# implemented using a the `Dataset` class.
# `tf.parse_csv` sets the types of the outputs to match the examples given in
# the `record_defaults` argument.
CSV_TYPES = [[0.0], [0.0], [0.0], [0.0], [0]]
def _parse_line(line):
# Decode the line into its fields
fields = tf.decode_csv(line, record_defaults=CSV_TYPES)
# Pack the result into a dictionary
features = dict(zip(CSV_COLUMN_NAMES, fields))
# Separate the label from the features
label = features.pop('Species')
return features, label
def csv_input_fn(csv_path, batch_size):
# Create a dataset containing the text lines.
dataset = tf.data.TextLineDataset(csv_path).skip(1)
# Parse each line.
dataset = dataset.map(_parse_line)
# Shuffle, repeat, and batch the examples.
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# Return the dataset.
return datasetPremade_estimator.py脚本分析如下
"""An Example of a DNNClassifier for the Iris dataset."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import tensorflow as tf
import iris_data
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', default=100, type=int, help='batch size')
parser.add_argument('--train_steps', default=1000, type=int,
help='number of training steps')
def main(argv):
args = parser.parse_args(argv[1:])
# Fetch the data
(train_x, train_y), (test_x, test_y) = iris_data.load_data()
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
# Build 2 hidden layer DNN with 10, 10 units respectively.
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model must choose between 3 classes.
n_classes=3)
# Train the Model.
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y,
args.batch_size),
steps=args.train_steps)
# Evaluate the model.
eval_result = classifier.evaluate(
input_fn=lambda:iris_data.eval_input_fn(test_x, test_y,
args.batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
# Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict(
input_fn=lambda:iris_data.eval_input_fn(predict_x,
labels=None,
batch_size=args.batch_size))
template = ('\nPrediction is "{}" ({:.1f}%), expected "{}"')
for pred_dict, expec in zip(predictions, expected):
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(template.format(iris_data.SPECIES[class_id],
100 * probability, expec))
if __name__ == '__main__':
tf.logging.set_verbosity(tf.logging.INFO)
tf.app.run(main)运行premade_estimator.py脚本,可以得到如下的结果
可以看出训练出的模型对predict_x中的三种图像做出了很好的分类。

相关文章推荐
- 使用tensorflow实现简单的多分类问题
- 简单实现Tensorflow CNN图像训练
- 如何用TensorFlow和TF-Slim实现图像分类与分割
- Tensorflow使用slim工具(vgg16模型)实现图像分类与分割
- TensorFlow实战5:利用卷积神经网络对图像分类(初阶:MNIST手写数字)代码实现
- TensorFlow简要教程系列(三)TensorFlow实现简单图像探索
- 第1章:阿里云机器学习实践之路 / 第5节:深度学习--使用TensorFlow实现图像分类
- 详解tensorflow训练自己的数据集实现CNN图像分类
- 如何用TensorFlow和TF-Slim实现图像分类与分割
- 利用tensorflow实现一个简单的二分类
- tensorflow训练自己的数据集实现CNN图像分类2(保存模型&测试单张图片)
- Tensorflow实现一个简单的二分类问题
- [置顶] 基于DL的计算机视觉(2)--实现图像分类最简单的方法:KNN
- 如何用TensorFlow和TF-Slim实现图像分类与分割
- 如何用TensorFlow和TF-Slim实现图像分类与分割
- tensorflow实现简单卷积网络进行mnist分类
- 简单图像分类与识别CNN,Tensorflow,Cifar10(吴恩达Deep Learning)
- tensorflow用CNN实现CIFAR-10图像分类(cpu贼慢)
- 如何用TensorFlow和TF-Slim实现图像分类与分割
- Tensorflow使用slim工具(vgg16模型)实现图像分类与分割