python高阶爬虫实战
2018-03-30 11:58
274 查看
首先我们要知道,互联网中存在着无数的数据资源,通过网站网页呈现给用户。基本上都是用户发送一个请求,然后获得服务器响应发回对应的数据。很多网站上的数据爬取比较简单,只需要直接request那个网址就可以,很多小型网站都是这样。面对这样的网站数据,只需要花个几分钟随便写几行代码,就能爬到我们想要的数据。
但是想要爬取稍微大型一些的网站数据,就不会这么容易了。这些网站的服务器,会分析收到的每一条request,来判断该请求是否为用户操作。这种技术,我们把它称为反爬技术。常见的反爬技术,楼主知道的有上面所述的分析请求,还有验证码技术。对于这两种情况,我们在构造爬虫程序的时候就需要稍微费点力气了。
先来介绍第一种的应对方法。首先我们要知道一条request的组成部分,不同网站的request格式可能会有点不同。对于这一点,我们可以通过浏览器的开发者工具,抓到一个网站的请求数据格式。如下图:
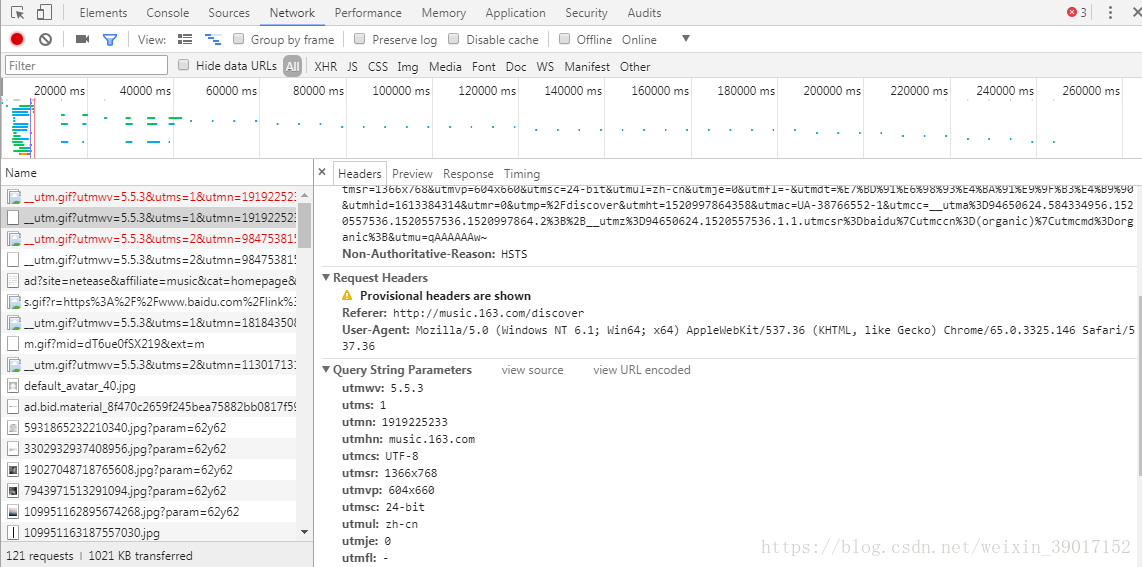
此为使用谷歌浏览器抓取的请求信息。
我们可以看到request headers的格式,所以在访问这样的网站的时候,我们就不能忘了在postdata中放上一条伪造的headers。headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:32.0) Gecko/20100101 Firefox/32.0',
'Referer': 'Address'}其中referer键对应的值是要访问的网址。
某些网站还会需要有cookie的用户验证,我们可以通过调用requests.Session().cookies来获得它。
如果在爬虫中需要提交某些信息的话,还要构造一下postdata的数据。比如这样:postData = {
'username': ul[i][0],
'password': ul[i][1],
'lt': b.group(1),
'execution': 'e1s1',
'_eventId': 'submit',
'submit': '%B5%C7%C2%BC',
}而对于爬虫处理验证码的话,目前楼主能想到的就是通过PIL做图像分析,提取图像特征值来匹配验证码内容。
具体的算法网上有很多,根据不同验证码的种类,有不同的算法,不过思路基本一样。楼主就不举例了。
以上是爬虫进阶内容,若有错误还望指正。
但是想要爬取稍微大型一些的网站数据,就不会这么容易了。这些网站的服务器,会分析收到的每一条request,来判断该请求是否为用户操作。这种技术,我们把它称为反爬技术。常见的反爬技术,楼主知道的有上面所述的分析请求,还有验证码技术。对于这两种情况,我们在构造爬虫程序的时候就需要稍微费点力气了。
先来介绍第一种的应对方法。首先我们要知道一条request的组成部分,不同网站的request格式可能会有点不同。对于这一点,我们可以通过浏览器的开发者工具,抓到一个网站的请求数据格式。如下图:
此为使用谷歌浏览器抓取的请求信息。
我们可以看到request headers的格式,所以在访问这样的网站的时候,我们就不能忘了在postdata中放上一条伪造的headers。headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:32.0) Gecko/20100101 Firefox/32.0',
'Referer': 'Address'}其中referer键对应的值是要访问的网址。
某些网站还会需要有cookie的用户验证,我们可以通过调用requests.Session().cookies来获得它。
如果在爬虫中需要提交某些信息的话,还要构造一下postdata的数据。比如这样:postData = {
'username': ul[i][0],
'password': ul[i][1],
'lt': b.group(1),
'execution': 'e1s1',
'_eventId': 'submit',
'submit': '%B5%C7%C2%BC',
}而对于爬虫处理验证码的话,目前楼主能想到的就是通过PIL做图像分析,提取图像特征值来匹配验证码内容。
具体的算法网上有很多,根据不同验证码的种类,有不同的算法,不过思路基本一样。楼主就不举例了。
以上是爬虫进阶内容,若有错误还望指正。

相关文章推荐
- 07Python爬虫---Cookie实战
- Python爬虫实战--(三)获取网页中的动态数据
- Python3爬虫实战:爬取大众点评网某地区所有酒店相关信息
- Python爬虫实战03:用Selenium模拟浏览器爬取淘宝美食
- Python爬虫实战 抓取淘宝照片
- Python爬虫实战:爬糗事百科的段子
- 03精通Python网络爬虫——HTTP协议请求实战
- Python爬虫实战一之爬取糗事百科段子
- python3 [爬虫入门实战] 爬虫之爬取盘多多文档(百万数据)
- Python爬虫实战(4):抓取淘宝MM照片
- Python爬虫实战(4):抓取淘宝MM照片
- python爬虫实战:利用scrapy,短短50行代码下载整站短视频
- Python爬虫实战一 | 抓取取校花网的所有妹子
- python爬虫实战(1)——开发环境搭建
- Python爬虫实战(动态网页)
- Python爬虫框架Scrapy实战之定向批量获取职位招聘信息
- python初级实战系列教程《一、爬虫之爬取网页、图片、音视频》
- python 爬虫学习三(Scrapy 实战,豆瓣爬取电影信息)
- Pyspider框架 —— Python爬虫实战之爬取 V2EX 网站帖子
- Python基础爬虫实战实例----爬取1000个Python百度百科词条及相关词条的标题和简介