HadoopHA搭建
2018-03-29 22:09
148 查看
本人小白,此文章针对简单但是容易忽略的问题,自己踩过的坑自己知道,膜拜大神。
1.下载对应的CDH版本组件CDH版本要对得上号,要不会出现一系列问题。
2.拿到集群首先该干什么。应该确定一下组件分部情况。千万不要搞混淆。
举例 4台集群
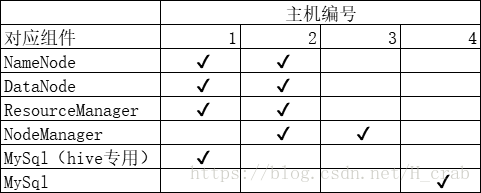
这是我给我用的那4太集群配的,后面会加上Spark和Hbase 所以2 、3号机器我打算主要当跑任务用
一定要吧mysqlhive专用的那个和普通的mysql分开 如过两个mysql放在同一台机器上 mysql如果挂掉了hive的数据是很难找回来的,专门拎出来一台机器专门做数据的读写感觉更好。
3.先别急着解压tar包。先检查机器的配置
(1)查看防火墙状态 防火墙开启的情况下 集群之间的端口用不了的!!!!!
开机启动 chkconfig iptables on
开机不启动 chkconfig iptables off
立刻开启 service iptables start
立刻关闭 service iptables stop
(2)云服务器防火墙的问题:云服务器的防火墙就比较麻烦了,比如我现在使用的是华为的ucloud,
他们官网上有控制台,控制台上有控制防火墙的组件,实在找不到就问上司要帐号 然后自己去问客服怎么操作,阿里云同理()(3)这个是检查端口能不能用的命令。很实用
先安装telnet
命令:yum install telnet
检查端口是否以通信的命令 :telnet IP或者主机名 端口号
4.配置hosts
vi /etc/hosts
5.实现分发机器与机器之间的钥匙
6.配置 /etc/profile
7.以上基本操作做好了以后就可以解压tar包啦 举例我是解压在/home下面的
配置什么?
每一台机器上的配置文件都统一
CDH版本的配置文件是在$HADOOP_HOME/etc/hadoop下面的
分别是core-site.xml hdfs-site.xml yarn-site.xml mapper-site.xml
不同颜色字体对应不同的机器
第一台主机名 第二台主机名 第三台主机名
core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://主机1:8020</value> </property><!--配置的是主节点的client端口号 可以自己更改-->
<property> <name>hadoop.tmp.dir</name> <value>/home/data</value> </property><!--配置的是存放blk的目录,可以以逗号隔开指定第二个地址-->
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--设置副本数为2-->
<property>
<name>dfs.ha.namenodes.freedom</name>
<value>主机1,主机2</value>
</property>
<!--设置namenode高可用-->
<property>
<name>dfs.nameservices</name>
<value>主机1</value>
</property>
<!--设置namenode服务端-->
<property>
<name>dfs.ha.namenodes.Master.yanshu.com</name>
<value>主机1,主机2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Master.yanshu.com.Master.yanshu.com</name>
<value>主机1:50090</value>
</property>
<!--hdfs 用的通信端口,这里找不到请改成ip-->
<property>
<name>dfs.namenode.http-address.Master.yanshu.com.Master.yanshu.com</name>
<value>主机1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Master.yanshu.com.slave01.yanshu.com</name>
<value>主机2:50090</value>
</property>
<property>
<name>dfs.namenode.http-address.Master.yanshu.com.slave01.yanshu.com</name>
<value>主机2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://主机1:8485;主机2:8485;主机3:8485/cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journal</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.Master.yanshu.com</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value></property><property> <name>yarn.resourcemanager.cluster-id</name> <value>RM_HA_ID</value></property><property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>主机1,主机2</value></property><!--指定resourcemanager的Ha -->
<property> <name>yarn.resourcemanager.hostname.主机1</name> <value>主机1</value></property><!--指定resourcemanager节点的IP地址 -->
<property> <name>yarn.resourcemanager.hostname.主机2</name> <value>主机2</value></property>
<!--指定resourcemanager节点的IP地址 -->
<property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value></property><!--指定resourcemanager节点挂了 就启动恢复-->
<property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property> <name>yarn.resourcemanager.zk-address</name> <value>主机1:2181,主机2:2181,主机3:2181</value></property><!--指定resourcemanager用的zookeeper地址加端口号-->
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><!--优化shuffle-->
</configuration>
mapper-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--告诉hadoop mapreduce任务在yarn上执行-->
</configuration>
slaves
192.168.0.** 主机1192.168.0.** 主机2192.168.0.** 主机38.机器与机器之间通讯需要什么???-------zookeeper
zookeeper配置
参考 https://www.cnblogs.com/LUA123/p/7222216.html
9.以上步骤处理好了之后可以开始了
配置好了以后一定遵循以下步骤!!!!!!!!!!!!!1
1.检查core-site.xml里面配置的元文件存储地址是不是文件为空(警告:不是新配置的hadoop集群请一定不要操作!!)
2.启动j
3.在第一台NameNode节点上format 仔细查看日志 如果不出错会在倒数几行内发现success
4.启动第一台的NameNode是否可以成功启动 如果不能启动仔细检查配置(core-site.xml hdfs-site.xml)
5.如果可以成功启动就到第二台NameNode上同步元数据信息
6.在第一台机器上初始化zk
bin/hdfs zkfc -formatZK7.关闭所有机器上的NameNode
8.sbin/start-all.sh
查看所有机器的jps启动情况 如果与配置不符合则检查相对应的配置是否正确,如果确定正确。请打开相对应的logs日志的out文件查看日志输出信息
9.如果成功配置那是最好的,如果配置成功或或者中途步骤错误了,不要担心,继续重新来,新集群嘛练手的
千万千万千万不要乱用rm 这种命令 你会后悔的
尽量不要kill程序的时候用kill -9 这种命令 太暴力了 上次我就用这个命令弄得第二台机器NameNode无法跟第一台一致了 还好能再同步
有问题先看日志,一定搞清楚问题到底出在哪里,找对应的问题 会看日志总比盲目的复制错误代码去百度上找强得多
日志是好朋友
1.下载对应的CDH版本组件CDH版本要对得上号,要不会出现一系列问题。
2.拿到集群首先该干什么。应该确定一下组件分部情况。千万不要搞混淆。
举例 4台集群
这是我给我用的那4太集群配的,后面会加上Spark和Hbase 所以2 、3号机器我打算主要当跑任务用
一定要吧mysqlhive专用的那个和普通的mysql分开 如过两个mysql放在同一台机器上 mysql如果挂掉了hive的数据是很难找回来的,专门拎出来一台机器专门做数据的读写感觉更好。
3.先别急着解压tar包。先检查机器的配置
(1)查看防火墙状态 防火墙开启的情况下 集群之间的端口用不了的!!!!!
开机启动 chkconfig iptables on
开机不启动 chkconfig iptables off
立刻开启 service iptables start
立刻关闭 service iptables stop
(2)云服务器防火墙的问题:云服务器的防火墙就比较麻烦了,比如我现在使用的是华为的ucloud,
他们官网上有控制台,控制台上有控制防火墙的组件,实在找不到就问上司要帐号 然后自己去问客服怎么操作,阿里云同理()(3)这个是检查端口能不能用的命令。很实用
先安装telnet
命令:yum install telnet
检查端口是否以通信的命令 :telnet IP或者主机名 端口号
4.配置hosts
vi /etc/hosts
5.实现分发机器与机器之间的钥匙
6.配置 /etc/profile
7.以上基本操作做好了以后就可以解压tar包啦 举例我是解压在/home下面的
配置什么?
每一台机器上的配置文件都统一
CDH版本的配置文件是在$HADOOP_HOME/etc/hadoop下面的
分别是core-site.xml hdfs-site.xml yarn-site.xml mapper-site.xml
不同颜色字体对应不同的机器
第一台主机名 第二台主机名 第三台主机名
core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://主机1:8020</value> </property><!--配置的是主节点的client端口号 可以自己更改-->
<property> <name>hadoop.tmp.dir</name> <value>/home/data</value> </property><!--配置的是存放blk的目录,可以以逗号隔开指定第二个地址-->
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--设置副本数为2-->
<property>
<name>dfs.ha.namenodes.freedom</name>
<value>主机1,主机2</value>
</property>
<!--设置namenode高可用-->
<property>
<name>dfs.nameservices</name>
<value>主机1</value>
</property>
<!--设置namenode服务端-->
<property>
<name>dfs.ha.namenodes.Master.yanshu.com</name>
<value>主机1,主机2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Master.yanshu.com.Master.yanshu.com</name>
<value>主机1:50090</value>
</property>
<!--hdfs 用的通信端口,这里找不到请改成ip-->
<property>
<name>dfs.namenode.http-address.Master.yanshu.com.Master.yanshu.com</name>
<value>主机1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Master.yanshu.com.slave01.yanshu.com</name>
<value>主机2:50090</value>
</property>
<property>
<name>dfs.namenode.http-address.Master.yanshu.com.slave01.yanshu.com</name>
<value>主机2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://主机1:8485;主机2:8485;主机3:8485/cluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/journal</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.Master.yanshu.com</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value></property><property> <name>yarn.resourcemanager.cluster-id</name> <value>RM_HA_ID</value></property><property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>主机1,主机2</value></property><!--指定resourcemanager的Ha -->
<property> <name>yarn.resourcemanager.hostname.主机1</name> <value>主机1</value></property><!--指定resourcemanager节点的IP地址 -->
<property> <name>yarn.resourcemanager.hostname.主机2</name> <value>主机2</value></property>
<!--指定resourcemanager节点的IP地址 -->
<property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value></property><!--指定resourcemanager节点挂了 就启动恢复-->
<property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property> <name>yarn.resourcemanager.zk-address</name> <value>主机1:2181,主机2:2181,主机3:2181</value></property><!--指定resourcemanager用的zookeeper地址加端口号-->
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><!--优化shuffle-->
</configuration>
mapper-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--告诉hadoop mapreduce任务在yarn上执行-->
</configuration>
slaves
192.168.0.** 主机1192.168.0.** 主机2192.168.0.** 主机38.机器与机器之间通讯需要什么???-------zookeeper
zookeeper配置
参考 https://www.cnblogs.com/LUA123/p/7222216.html
9.以上步骤处理好了之后可以开始了
配置好了以后一定遵循以下步骤!!!!!!!!!!!!!1
1.检查core-site.xml里面配置的元文件存储地址是不是文件为空(警告:不是新配置的hadoop集群请一定不要操作!!)
2.启动j
3.在第一台NameNode节点上format 仔细查看日志 如果不出错会在倒数几行内发现success
4.启动第一台的NameNode是否可以成功启动 如果不能启动仔细检查配置(core-site.xml hdfs-site.xml)
5.如果可以成功启动就到第二台NameNode上同步元数据信息
6.在第一台机器上初始化zk
bin/hdfs zkfc -formatZK7.关闭所有机器上的NameNode
8.sbin/start-all.sh
查看所有机器的jps启动情况 如果与配置不符合则检查相对应的配置是否正确,如果确定正确。请打开相对应的logs日志的out文件查看日志输出信息
9.如果成功配置那是最好的,如果配置成功或或者中途步骤错误了,不要担心,继续重新来,新集群嘛练手的
千万千万千万不要乱用rm 这种命令 你会后悔的
尽量不要kill程序的时候用kill -9 这种命令 太暴力了 上次我就用这个命令弄得第二台机器NameNode无法跟第一台一致了 还好能再同步
有问题先看日志,一定搞清楚问题到底出在哪里,找对应的问题 会看日志总比盲目的复制错误代码去百度上找强得多
日志是好朋友

相关文章推荐
- 如何搭建一个独立博客——简明Github Pages与Hexo教程
- vim自动补全之搭建
- 使用python fabric搭建RHEL 7.2大数据基础环境以及部分优化
- (cljs/run-at (JSVM. :browser) "搭建刚好可用的开发环境!")
- 搭建showslow:前端性能跑分及优化工具
- 如何在一台ESXi主机上搭建一整套VSAN集群的环境
- Java环境搭建与配置
- RMI网络编程开发之二 如何搭建基于JDK1.5的分布式JAVA RMI
- pycharm的Django搭建web开发-helloworld
- MongoDB 3.4 高可用集群搭建(三)shard 分片
- Linux的iSCSI共享存储服务搭建
- Ubuntu14.04搭建LNMP平台
- dubbo搭建实例
- linux开发环境搭建
- docker应用-3(搭建hadoop以及hbase集群)
- Ubuntu 10.10下Android源码编译环境的搭建
- cocos2d-x学习之旅(二):1.2 cocos2d-x Visual Studio2010 开发环境搭建 windows 7 32位
- nginx hls rtmp 环境搭建
- 一步一步了解Cocos2dx 3.0 正式版本开发环境搭建(Win32/Android)
- ***搭建以及pptp原理