Drill-On-YARN
2018-03-27 23:09
155 查看
1. Drill-On-YARN介绍
功能启动
停止
扩容
缩容
failover
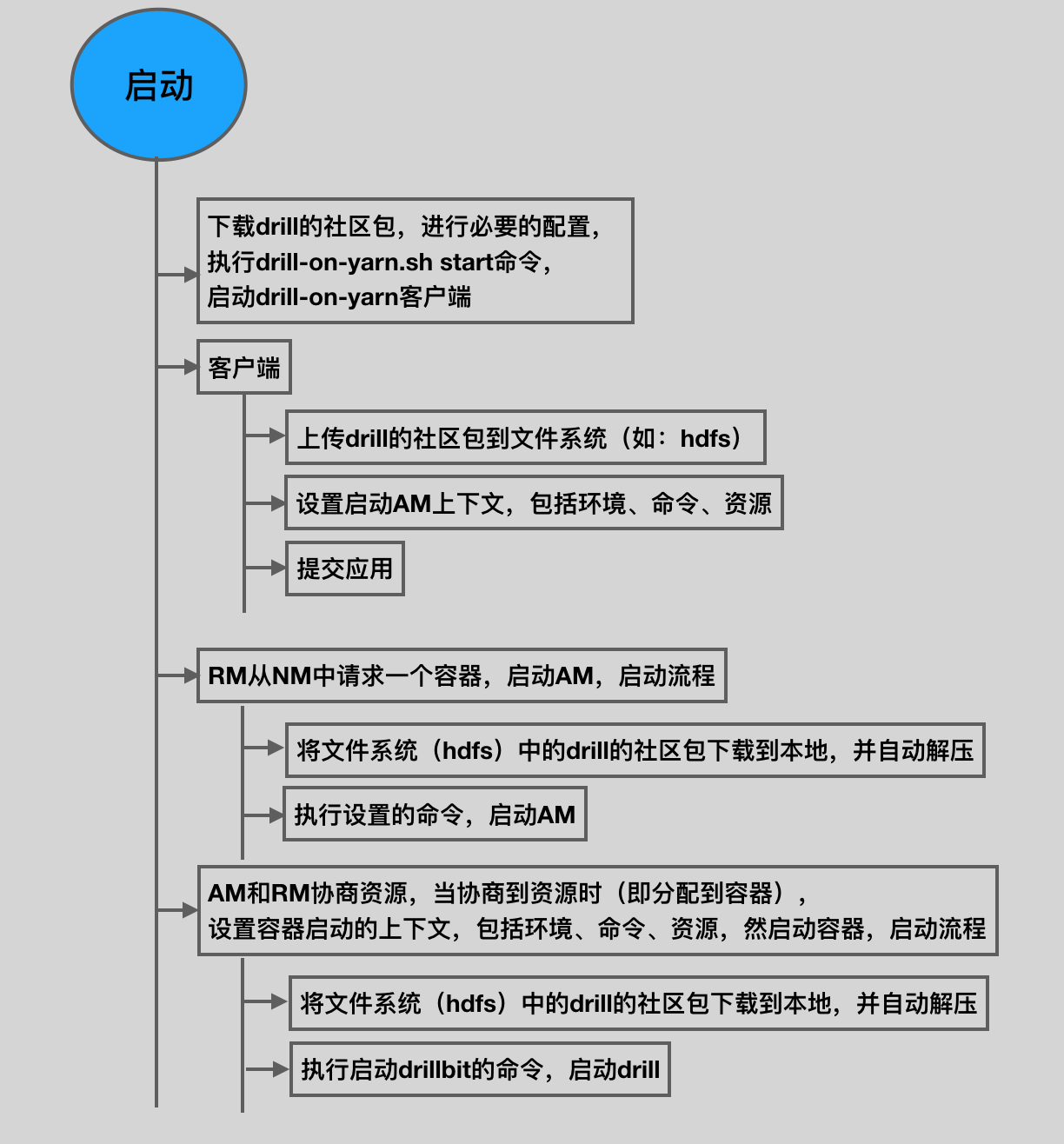
启动流程
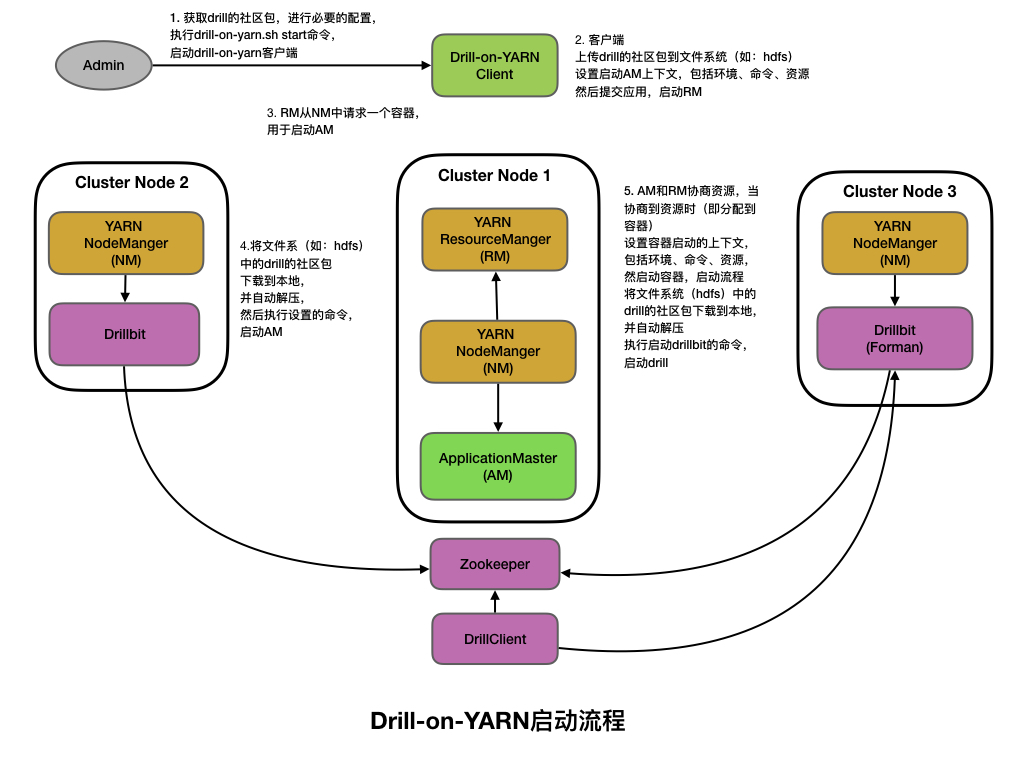
下载drill的社区包,进行必要的配置,执行drill-on-yarn.sh start命令,启动drill-on-yarn客户端
客户端
上传drill的社区包到文件系统(如:hdfs)
设置启动AM上下文,包括环境、命令、资源
提交应用,启动RM
RM从NM中请求一个容器,启动AM,启动流程
将文件系统(hdfs)中的drill的社区包下载到本地,并自动解压
执行设置的命令,启动AM
AM和RM协商资源,当协商到资源时(即分配到容器)
设置容器启动的上下文,包括环境、命令、资源,然启动容器,启动流程
将文件系统(hdfs)中的drill的社区包下载到本地,并自动解压
执行启动drillbit的命令,启动drill
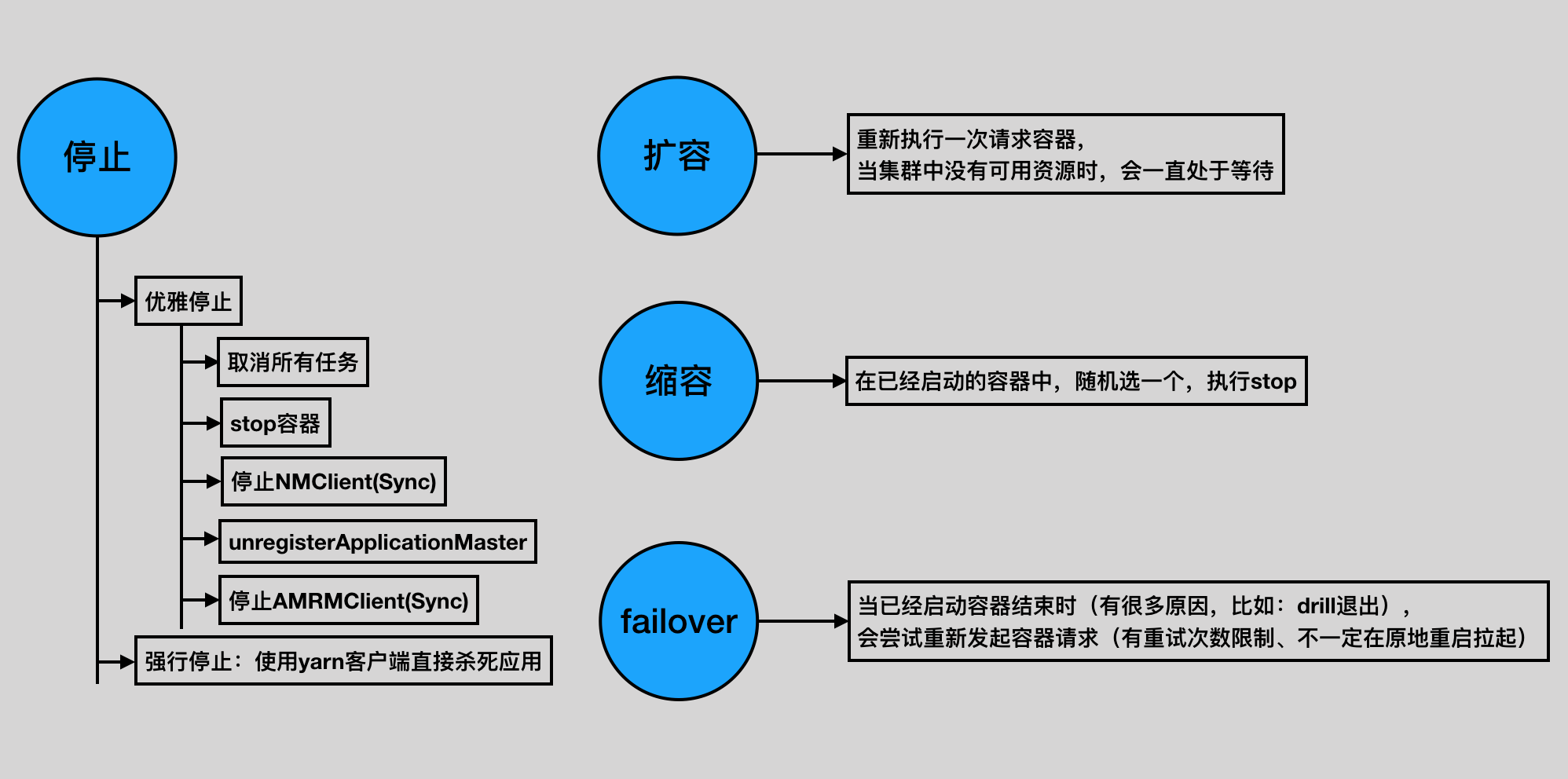
停止
优雅停止:取消所有任务(pending、requesting、running) -> stop容器 -> 停止NMClient -> unregisterApplicationMaster -> 停止AMRMClient
强行停止: yarn客户端直接杀死应用 yarnClient.killApplication
扩容:重新执行一次请求容器,当集群中没有可用资源时,会一直处于等待
缩容:在已经启动的容器中,随机选一个,执行stop
failover:当已经启动容器结束时(有很多原因,比如:drill退出),会尝试重新发起容器请求(有重试次数限制、不一定在原地重启拉起)
2. 启动流程
3. 其他功能

相关文章推荐
- Drill-On-YARN
- Spark on Yarn遇到的几个问题
- MapReduce On YARN
- Spark2.0.1 on yarn with hue 集群搭建部署(一)基础环境配置
- spark on yarn启动异常
- spark on yarn中的启动参数
- Spark On YARN 集群安装部署
- Spark2.0.1 on yarn with hue 集群搭建部署(五)hue安装支持hadoop
- Hadoop Yarn on Docker
- Spark ON YARN 官方中文版
- Spark on Yarn:java.sql.SQLException: No suitable driver found for jdbc:microsoft:sqlserver://localhost\\db_instance_name:1433;databaseName=db_name
- 从源码角度看Spark on yarn client & cluster模式的本质区别
- SparkSQL On Yarn with Hive,操作和访问Hive表
- Hadoop HA on Yarn——集群配置
- Spark On Yarn:提交Spark应用程序到Yarn
- spark on yarn模式:yarn命令杀除当前的application
- Spark On YARN 集群安装部署
- Spark on yarn的内存分配问题
- spark on yarn 基本用法
- 【解决】Spark On Yarn执行中executor内存限制问题