【物体检测】R-CNN家族
2018-03-27 22:09
260 查看
目标检测评测指标
mAp(Mean Average Precision)true prediction: IoU>thresholdIoU>threshold & ypred=yypred=y 而且,多个类似的预测,只取一个,其他认为是false。即对一张图的同一个物体,假设有5个预测的IoU > threshold, 且ypred=ygroudtruthypred=ygroudtruth,我们则认为有1个true + 4个false
Recall:TPTP+FNTPTP+FN
理解R-CNN
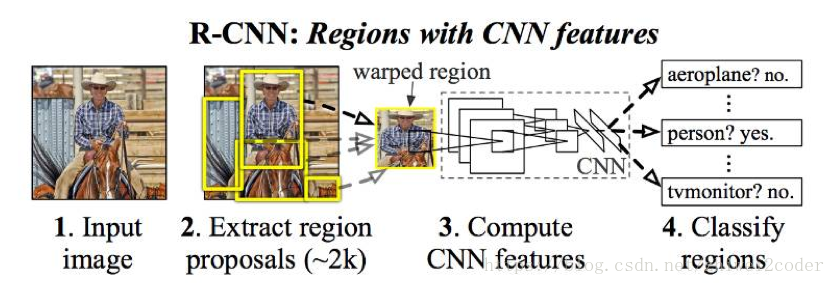
输入:图像
输出:图像中每个物体的边界框(四个坐标?两个)和边框内物体的类别
R-CNN是最早的结合CNN的目标检测框架之一,当时在PASCAL, ILSVR上的评测效果达到最高。其主要思想就是判断哪些区域可能存在物体,再判断这些区域包含了那个物体。步骤如图:
生成2k个可能包含物体的边框
warp图片至统一大小,训练CNN(fine-runing),然后用CNN提取fixed-size的特征
用Linear SVM对所有特征进行分类
回归模型生成边框
一些需要明确的问题:
1. 如何生成边框? Selective search《Efficient 》
2. 对2k个区域,我们截取图片并resize至227x227大小(AlexNet的输入图片大小)。然后使用在大数据集(ImageNet 或VOC2007)下pre-trained的模型,进行fine-tuning,然后提取得到4096(6x6x256)维的特征。
问:怎么构建数据集用于fine-tune CNN呢? X:每个propsal区域的图像 fixed size(227x227) Y:每个propsal区域,我们选和它overlap最大,且IoU>0.5的GT区域的标签作为label,这些被我们成为positive example。其他proposal都被标记为背景,是negtive examples。它们组成的数据集将被用于fine-tune CNNs
3. 存储所有上一阶段的特征,训练linear svm分类器。
问:怎么构建数据集用于训练SVM呢? X:CNN features。 Y: 对每个类,只取GT的bbx作为positive example,取IoU<0.3的为negtive example,剩下的舍弃。 问:为什么不直接用fine-tuned CNN的最后一层softmax? 实验证明再次使用SVM效果更好。原因可能是fine_tuning的时候样本数量太少,我们通过‘jittered’增加30倍。fine-tuned的时候使用不是严格的GT,训练SVM的时候是。
4. 如何最后确定边框(class-specific bounding-box regression)
用P=(px,py,pw,ph)P=(px,py,pw,ph) 表示一个bbx,前两个是p的坐标,后两个是bbx的宽和高。用G=(Gx,Gy,Gw,Gh)G=(Gx,Gy,Gw,Gh)表示真实值的bbx信息。我们希望学习一个 P→GP→G的线性映射,或者说回归。
我们只选有效的P用于训练bbx。有效的定义:
- 与GT的IoU>threshold = 0.6 - 如果对一个GT有多个overlap的pred,取IoU最大的一个 - 其他的不选
理解Fast R-CNN
理解Faster R-CNN
理解Mask R-CNN(semantic segmentation)

相关文章推荐
- CNN应用之基于R-CNN的物体检测-CVPR 2014-未完待续
- 物体检测与识别-Faster RCNN
- 后RCNN时代的物体检测及实例分割进展
- Faster R-CNN物体检测
- 深度学习(十八)基于R-CNN的物体检测-CVPR 2014
- 深度学习笔记之基于R-CNN的物体检测
- 基于R-CNN的物体检测
- 基于R-CNN的物体检测
- 物体检测系列之faster-rcnn原理介绍
- CNN应用之SPP(基于空间金字塔池化的卷积神经网络物体检测)-ECCV 2014-未完待续
- 基于R-CNN的物体检测(笔记标注版)
- HyperNet/ION/SDP-CRC/R-CNN/Fast R-CNN/Faster R-CNN/物体检测算法
- 基于R-CNN的物体检测
- 基于R-CNN的物体检测
- 简介物体检测从RCNN到Mask RCNN的网络构型变化
- 基于R-CNN的物体检测(转自 hjimce的专栏)
- caffe 官方例程之R-CNN(物体检测)
- 深度学习之物体检测——Fast R-CNN(Ross Girshick)
- 物体检测(1)--R-CNN物体检测
- (Slide)CNN图像分类与物体检测