MapReduce工作机制详解(MapTask和ReduceTask)
2018-03-27 15:17
465 查看
MapTask:
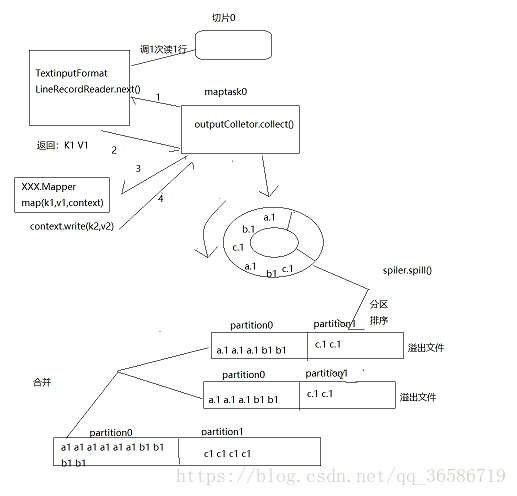
1.maptask0负责切片0 ,maptask1负责切片1,maptask2负责切片2。
2.maptask0通过一个组件TextinputFormat读切片0,这个组件封装一个LineRecordReader,里面有next方法,每调一次方法从切片0里读一行,给maptask返回k1:行起始offset和value1:行内容。
3.调用mapper里的map(k1,v1,context)方法,再返回context.write(k2,v2)。
4.mapTask收到k2 v2,再调用mapTask里的工具类,调用outputColletor.collect(),序列化,变成二进制,放到一个环形的缓冲区。
5.不断向缓冲区放输出的数据,环形缓冲区默认是100M,当放入容量差不多达到80%,把数据溢出调用组件spiler.spill(),在过程中先分区:k.hashcode%reducetasts排序:同一个区内按key排序,得到分区,根据这个分区文件写到磁盘里去。(算法是快速排序算法)
6.当缓冲结束,读取切片完成,会把溢出文件合并,对局部数据通过归并排序(外部排序算法)。
ReduceTask
1.reduceTask0从多个mapTask拿到的partiton0的数据合并放在本地磁盘。
2.调用XXXReducer类里的reduce(Text key,迭代器 values,context),输出数据context.write(k3,v3)
3.调用TextOtputFormat里的RecordWriter.write(k3,v3)
4.然后在指定的HDFS的目录写文件。
1.maptask0负责切片0 ,maptask1负责切片1,maptask2负责切片2。
2.maptask0通过一个组件TextinputFormat读切片0,这个组件封装一个LineRecordReader,里面有next方法,每调一次方法从切片0里读一行,给maptask返回k1:行起始offset和value1:行内容。
3.调用mapper里的map(k1,v1,context)方法,再返回context.write(k2,v2)。
4.mapTask收到k2 v2,再调用mapTask里的工具类,调用outputColletor.collect(),序列化,变成二进制,放到一个环形的缓冲区。
5.不断向缓冲区放输出的数据,环形缓冲区默认是100M,当放入容量差不多达到80%,把数据溢出调用组件spiler.spill(),在过程中先分区:k.hashcode%reducetasts排序:同一个区内按key排序,得到分区,根据这个分区文件写到磁盘里去。(算法是快速排序算法)
6.当缓冲结束,读取切片完成,会把溢出文件合并,对局部数据通过归并排序(外部排序算法)。
ReduceTask
1.reduceTask0从多个mapTask拿到的partiton0的数据合并放在本地磁盘。
2.调用XXXReducer类里的reduce(Text key,迭代器 values,context),输出数据context.write(k3,v3)
3.调用TextOtputFormat里的RecordWriter.write(k3,v3)
4.然后在指定的HDFS的目录写文件。

相关文章推荐
- Mapreduce计算框架涉及的技术(2)-工作机制详解
- MapReduce工作机制详解
- MapReduce 工作机制详解(三)Shuffle 机制
- MapReduce 工作机制详解(二)ReduceTask工作机制
- MapReduce 工作机制详解(一)MapTask工作机制
- MapReduce 2 的工作机制
- JVM结构、GC工作机制详解
- JVM 和 GC的工作机制详解
- Hadoop入门第三篇-MapReduce试手以及MR工作机制
- JVM结构、GC工作机制详解
- yarn运行mapreduce的工作机制
- 大数据之MapReduce详解(MR的运行机制及配合WordCount实例来说明运行机制)
- MapReduce工作机制
- 【Spark工作机制详解】 执行机制
- MapReduce的工作机制
- 802.1X协议的工作机制流程详解
- JVM结构、GC工作机制详解
- MapReduce 2 的工作机制
- NIO组件Selector工作机制详解(上)
- JVM结构、GC工作机制详解