大数据第一步:Scala+Hadoop+Spark环境安装
2018-03-26 15:57
183 查看
(下面所有操作都要建立在安装过JDK的基础上)请到官网下载最新版本的scala、hadoop和spark,移动至/usr/local文件夹。

一、安装Scala1、解压

2、重命名

3、编辑/etc/profile

在底部添加export PATH=/usr/local/scala/bin:$PATH
4、使更改生效

5、验证出现下图即为成功
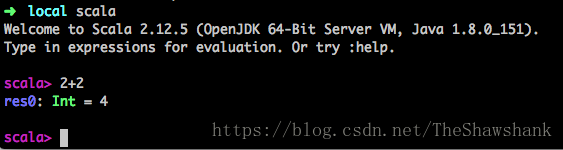
至此Scala安装全部完成。二、安装hadoop1、新增名为hadoop的用户

输入密码,如果提示密码过于简单可以无视,继续输入即可2、配置ssh免密登陆安装SSH client和SSH server。验证如下

密钥授权cd ~/.ssh/(如果没有该目录则先执行ssh localhost登陆,再输入exit退出)ssh-keygen -t rsa(生成密钥)cat id_rsa.pub >> authorized_keyschmod 600 ./authorized_keys3、解压,重命名(参考Scala,root权限)

4、更改hadoop权限

5、验证解压即可用,验证如下

三、安装Spark1、解压、重命名(参考Scala)
2、编辑/etc/profile
在底部添加SPARK_HOME=/usr/local/sparkPATH=$PATH:${SPARK_HOME}/bin3、使更改生效
4、验证

如果成功会出现
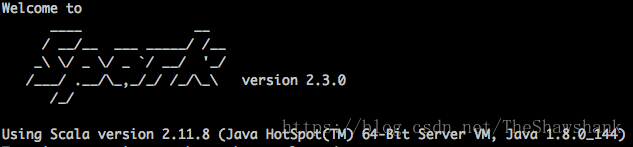
5、常见错误

如果出现这个错误在/etc/profile最后增加一行即可export LD_LIBRARY_PATH=/usr/local/hadoop/lib/native/:$LD_LIBRARY_PATH
一、安装Scala1、解压
2、重命名
3、编辑/etc/profile
在底部添加export PATH=/usr/local/scala/bin:$PATH
4、使更改生效
5、验证出现下图即为成功
至此Scala安装全部完成。二、安装hadoop1、新增名为hadoop的用户
输入密码,如果提示密码过于简单可以无视,继续输入即可2、配置ssh免密登陆安装SSH client和SSH server。验证如下
密钥授权cd ~/.ssh/(如果没有该目录则先执行ssh localhost登陆,再输入exit退出)ssh-keygen -t rsa(生成密钥)cat id_rsa.pub >> authorized_keyschmod 600 ./authorized_keys3、解压,重命名(参考Scala,root权限)
4、更改hadoop权限
5、验证解压即可用,验证如下
三、安装Spark1、解压、重命名(参考Scala)
2、编辑/etc/profile
在底部添加SPARK_HOME=/usr/local/sparkPATH=$PATH:${SPARK_HOME}/bin3、使更改生效
4、验证
如果成功会出现
5、常见错误
如果出现这个错误在/etc/profile最后增加一行即可export LD_LIBRARY_PATH=/usr/local/hadoop/lib/native/:$LD_LIBRARY_PATH

相关文章推荐
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop
- windows搭建spark运行环境(windows scala,hadoop,spark安装,idea使用配置等)
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(1)安装jdk
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
- 在hadoop环境下用spark跑wordcount(没有安装scala)
- Hadoop+Spark+Scala+R+PostgreSQL+Zeppelin 安装过程-环境准备
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(2)安装hadoop
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(1)安装jdk
- [置顶] 安装Idea(集成scala)以及在windows上配置spark(hadoop依赖)本地开发环境
- Hadoop+Spark+Scala+R+PostgreSQL+Zeppelin 安装过程-环境准备
- 两种配置大数据环境的方法Ambari以及hadoop源代码安装的步骤
- Hadoop+Spark+Scala+R+PostgreSQL+Zeppelin安装过程-Spark的安装配置测试和Scala的安装配置yuan
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
- Win10下安装单点Spark、Hadoop、Python环境
- 在hadoop2.4集群环境下安装spark
- mac下Hadoop、HDFS、Spark环境的安装和搭建
- 解决Linux(Ubuntu)环境变量配置无效的问题:JDK,Hadoop,Spark,Scala等
- [机器学习]基于spark框架的scala语言MAC环境的安装
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(3)http://www.cnblogs.com/liugh/p/6624491.html
- Hadoop+Spark+Scala+R+PostgreSQL+Zeppelin安装过程-SparkR安装配置和Zeppelin安装配置