机器学习笔记1——感知机(分类)
2018-03-23 21:23
218 查看
1.模型
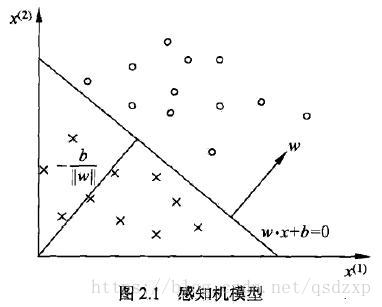
f(x)=sign(w⃗ ⋅x⃗ +b)f(x)=sign(w→⋅x→+b)其中,x⃗ x→为输入向量。w⃗ w→和bb为感知机模型的参数,w⃗ w→为权值向量,bb为偏置。感知机就是一个单个的神经元,如下图所示

几何解释:线性方程w⃗ ⋅x⃗ +b=0w→⋅x→+b=0是定义在特征空间RnRn的一个超平面。其中w⃗ w→是超平面的一个法向量,bb是超平面的截距。
2 训练数据集
(x⃗ i,yi),i=1,2,⋯,n(x→i,yi),i=1,2,⋯,n,其中yi∈{+1,−1}yi∈{+1,−1}3 损失函数:误分类点到超平面的总距离
输入空间中任意输入x⃗ ix→i到超平面的距离为1||w⃗ |||w⃗ ⋅x⃗ i+b|1||w→|||w→⋅x→i+b|如果x⃗ jx→j为误分类点,那么其到超平面的距离可以写为
−1||w⃗ ||yj(w⃗ ⋅x⃗ j+b)−1||w→||yj(w→⋅x→j+b)那么感知机学习的损失函数为L(w⃗ ,b)=−1||w⃗ ||∑xj∈Myj(w⃗ ⋅x⃗ j+b)L(w→,b)=−1||w→||∑xj∈Myj(w→⋅x→j+b)其中MM为误分类点的集合。
4.学习算法 —— 梯度下降法
极小化过程中不是一次将所有误分类点的梯度下降,而是一次随机算去一个误分类点使其梯度下降4.1 原始形式
需要注意的是,参数为w⃗ w→和bb。将损失函数分别对w⃗ w→和bb求偏导
∇w⃗ L(w⃗ ,b)=−∑xj∈Myjx⃗ j∇w→L(w→,b)=−∑xj∈Myjx→j∇bL(w⃗ ,b)=−∑xj∈Myj∇bL(w→,b)=−∑xj∈Myj每次选取一个点后,按照梯度的负方向更新参数即可,直到被正确分类。其实梯度下降的过程中,超平面在不断向误分类点的一侧移动。
w⃗ =w⃗ +ηyjx⃗ jw→=w→+ηyjx→j b=b+ηyjb=b+ηyj
4.2 对偶形式
在原始形式中,实例点更新次数越多,表明它离超平面越近,分类也就越难。在完成所有的学习之后,得到 w⃗ w→和bb最终的表达式为w⃗ =−∑xj∈Mnjηyjx⃗ jw→=−∑xj∈Mnjηyjx→j b=−∑xj∈Mnjηyjb=−∑xj∈Mnjηyj其中,njnj表示对于实例点jj的学习次数,正确分类点nj=0nj=0。在对偶形式中,学习的过程也就变为更新njnj的过程。
这样感知机模型就可以表示为f(x)=sign(∑xj∈Mnjηyjx⃗ j⋅x⃗ +∑xj∈Mnjηyj)f(x)=sign(∑xj∈Mnjηyjx→j⋅x→+∑xj∈Mnjηyj)学习过程中只需要更新njnj的优点还在于,对每次选择的实例点x⃗ ix→i,x⃗ j⋅x⃗ ix→j⋅x→i可以提前被离线计算,也就是Gram矩阵。这样可以大大降低运算量。
5 python实现
import numpy as np
import matplotlib.pyplot as plt
#训练数据集
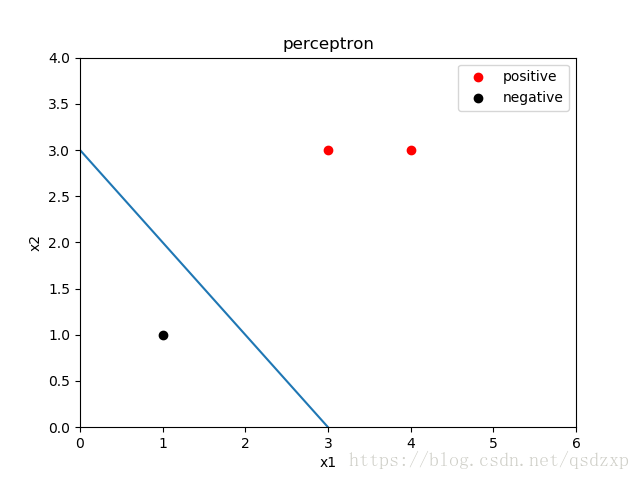
TrainData_x = np.array([[3, 3], [4, 3], [1, 1]])
TrainData_y = np.array([1, 1, -1])
NumData = len(TrainData_x)
#训练数据可视化
plt.figure()
plt.scatter(TrainData_x[0:2,0], TrainData_x[0:2,1], color='r',label='positive')
plt.scatter(TrainData_x[2,0], TrainData_x[2,1], color='k',label='negative')
plt.title('perceptron')
plt.xlabel('x1')
plt.ylabel('x2')
plt.xlim([0,6])
plt.ylim([0,4])
plt.legend()
eta = 1 #步长or学习率
w = np.array([0, 0]) #法向量初始值
delta_w = np.array([[0,0],[0,0],[0,0]]) #法向量更新值
b = 0 #截距初始值
delta_b = np.zeros(NumData)
for index in range(NumData):
delta_w[index] = eta*TrainData_x[index]*TrainData_y[index]
delta_b[index] = eta*TrainData_y[index]
###学习过程###
CorrData = 0 #正确分类数据的数目
while 1 :
for index in range(NumData):
if -TrainData_y[index]*(np.dot(w,TrainData_x[index])+b) >= 0 : #误分类点需要更新法向量和截距
w = w + delta_w[index]
b = b + delta_b[index]
else: #正确分类点无需操作
CorrData = CorrData + 1
if NumData == CorrData : #如果分类全部正确,跳出while,学习结束
break
else: #如果分类有错误,将CorrData置零,重新循环判断数据分类
CorrData = 0
print("w = ", w)
print("b = ", b)
line_x = [0, 6]
line_y = [0, 0]
for index in range(len(line_x)):
line_y[index] = (-w[0] * line_x[index]- b)/w[1]
plt.plot(line_x, line_y)
plt.savefig("perceptron.png")
plt.show()最终学习结果
w = [1 1]
b = -3.0
后记:第一次写python,从安装到调试环境到完成这段代码,比我想象多花了两倍的时间。主要是对python还不太熟悉,以后要多敲代码多练习。好好加油!

相关文章推荐
- 机器学习学习笔记3---感知机
- 机器学习之感知机学习笔记第一篇:求输入空间R中任意一点X0到超平面S的距离
- 多类别分类-机器学习(machine learning)笔记(Andrew Ng)
- 机器学习 学习笔记 朴素贝叶斯分类 笔记
- 机器学习基石笔记2——感知机(Perceptron)
- 机器学习笔记之朴素贝叶斯分类算法
- 机器学习笔记(3)---K-近邻算法(1)---约会对象魅力程度分类
- 机器学习概念总结笔记(一)——机器学习算法分类、最小二乘回归、岭回归、LASSO回归
- 机器学习实战笔记(Python实现)-07-模型评估与分类性能度量
- 机器学习实战笔记之非均衡分类问题
- 机器学习中使用的神经网络第二讲笔记:神经网络的结构和感知机
- 程序员的机器学习入门笔记(五):文本分类的入门介绍
- 机器学习概念总结笔记(二)——逻辑回归、贝叶斯分类、支持向量分类SVM、分类决策树ID3、
- 【学习笔记】斯坦福大学公开课(机器学习)题外篇:感知机学习算法
- 机器学习笔记十二:分类与回归树CART
- 机器学习笔记-决策树跟分类规则
- 【机器学习】python实践笔记 -- 经典监督学习模型之分类学习模型
- 机器学习笔记(IX)线性模型(V)多分类学习
- 机器学习概念总结笔记(三)——分类决策树C4.5、集成学习Bagging算法Boosting算法随机森林算法迭代决策树算法、