Spark2.X环境准备、编译部署及运行
2018-03-13 16:10
363 查看







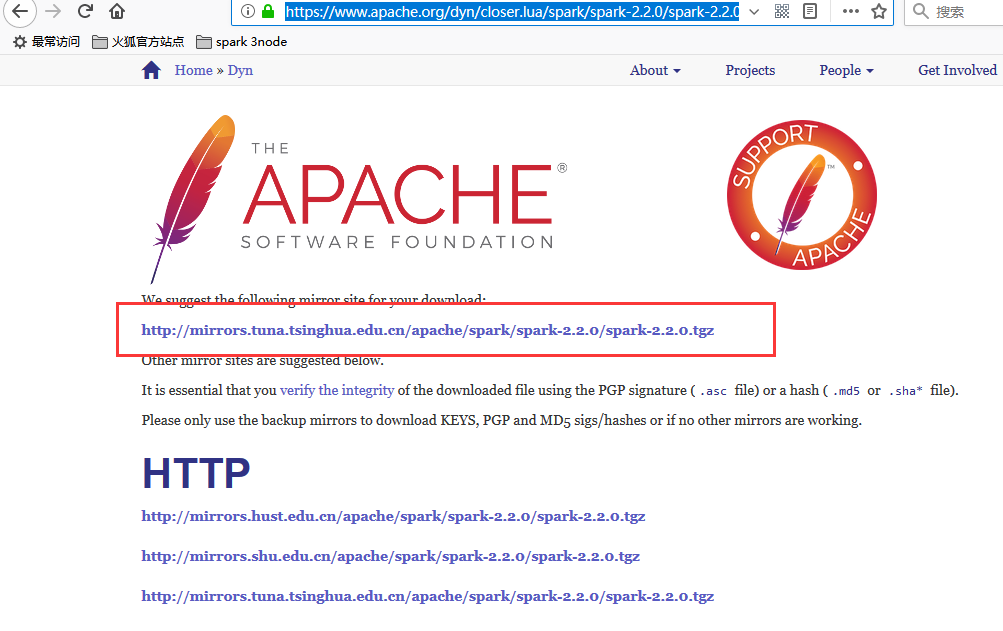
下载地址 :https://www.apache.org/dyn/closer.lua/spark/spark-2.2.0/spark-2.2.0.tgz
我们把spark放在节点2上

解压


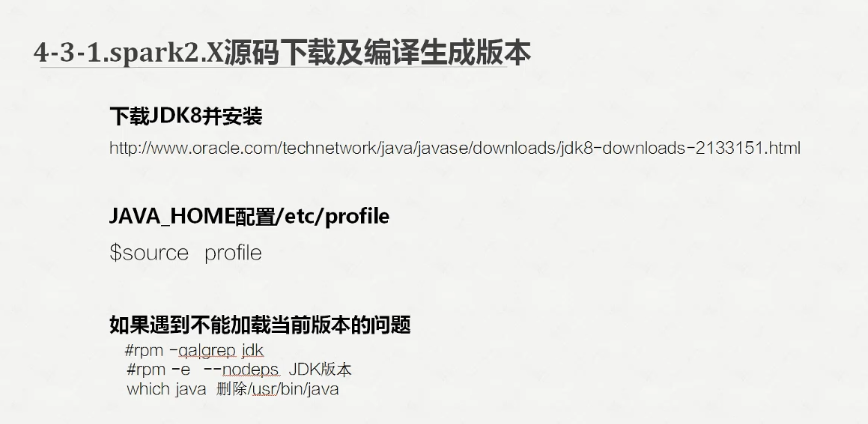
下面我们把jdk换成1.8的
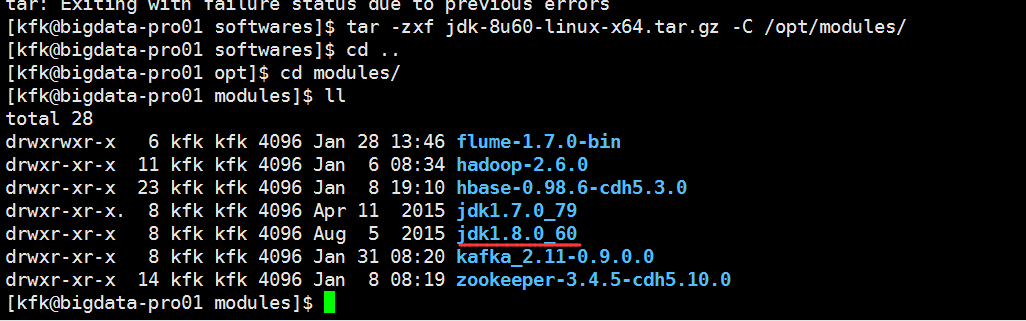


配置环境变量


使环境变量生效

重启后

另外两个节点的做法一样,这里就不多说了

上传maven包
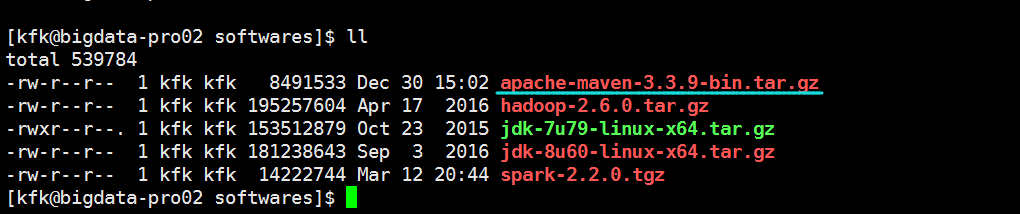
解压
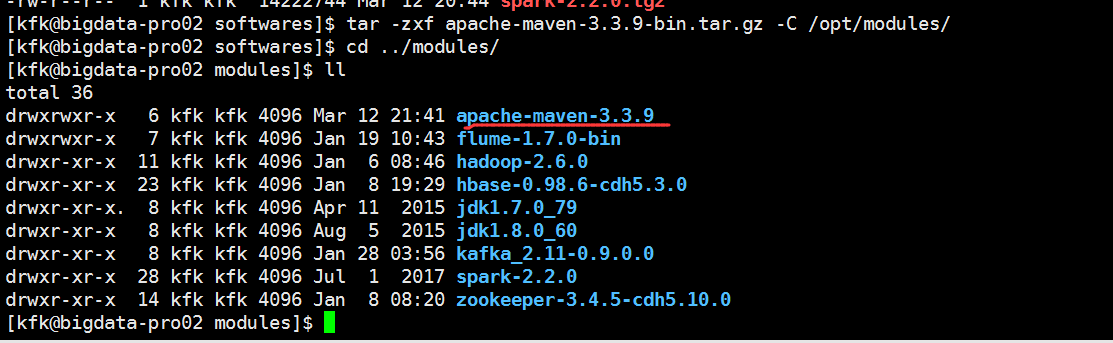

配置maven的环境变量

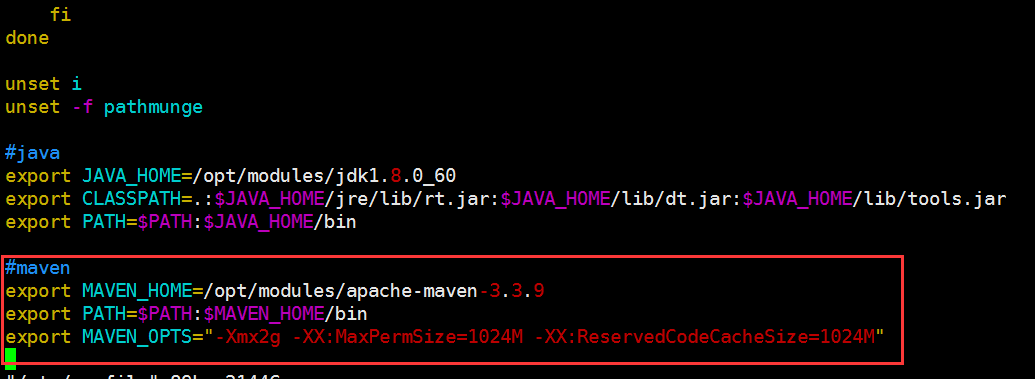
#java export JAVA_HOME=/opt/modules/jdk1.8.0_60 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin #maven export MAVEN_HOME=/opt/modules/apache-maven-3.3.9 export PATH=$PATH:$MAVEN_HOME/bin export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=1024M -XX:ReservedCodeCacheSize=1024M"
使其环境变量生效






找到这一串,把他删除掉
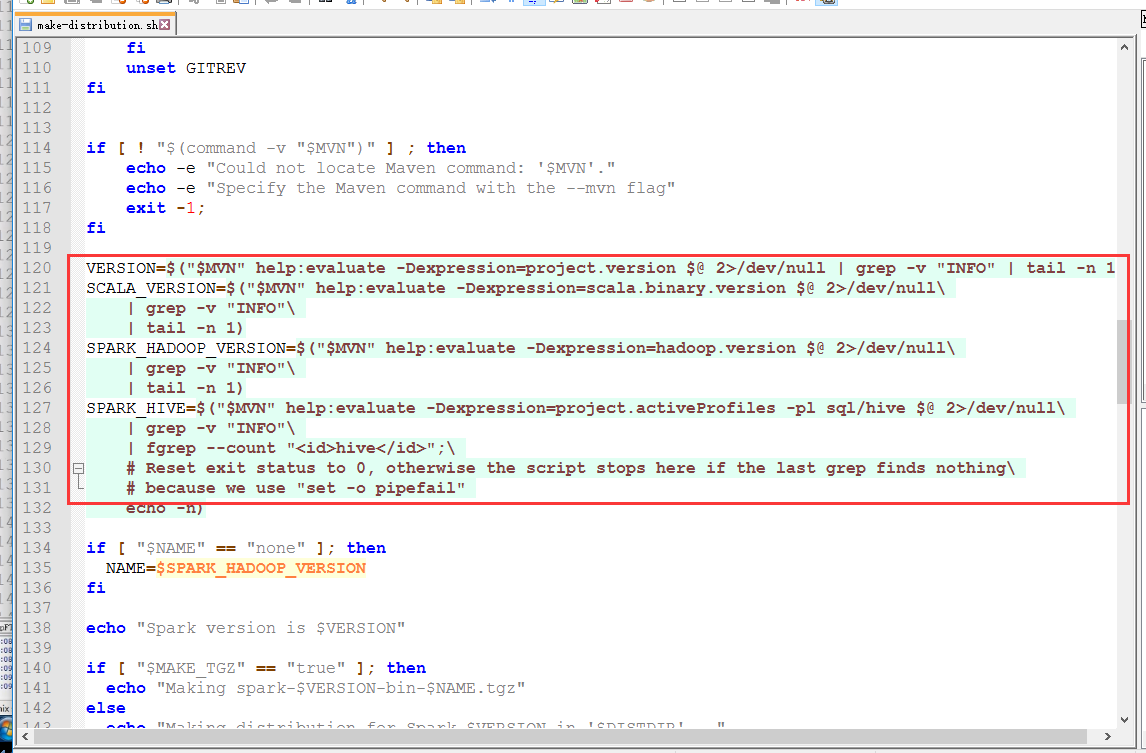
改成
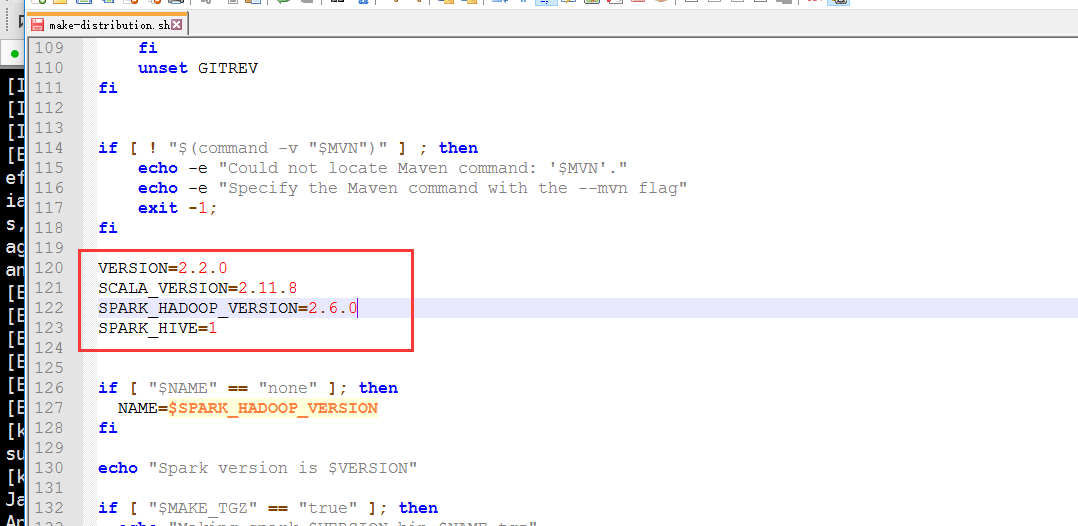
VERSION=2.2.0 SCALA_VERSION=2.11.8 SPARK_HADOOP_VERSION=2.6.0 SPARK_HIVE=1

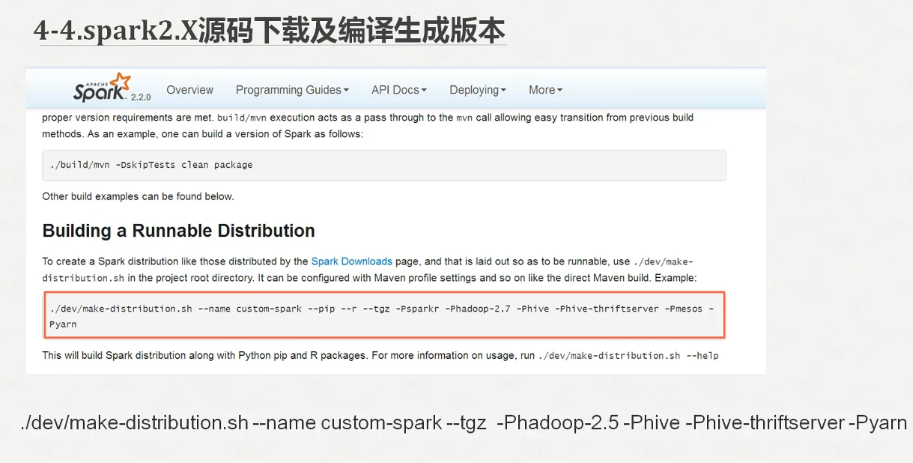
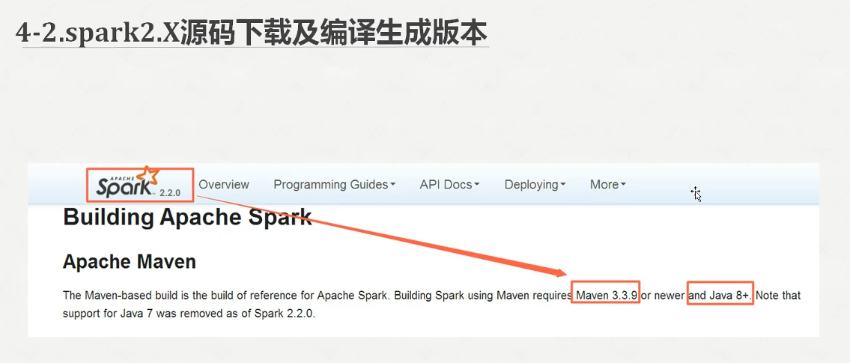
我们可以参考官网的教程说明
http://spark.apache.org/docs/2.2.0/building-spark.html
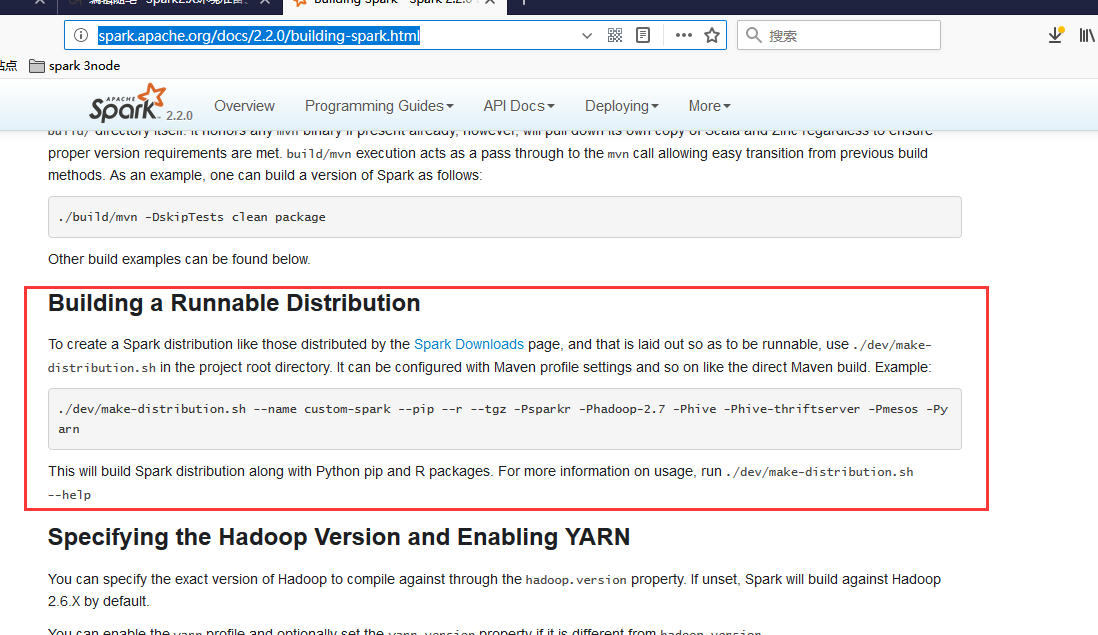
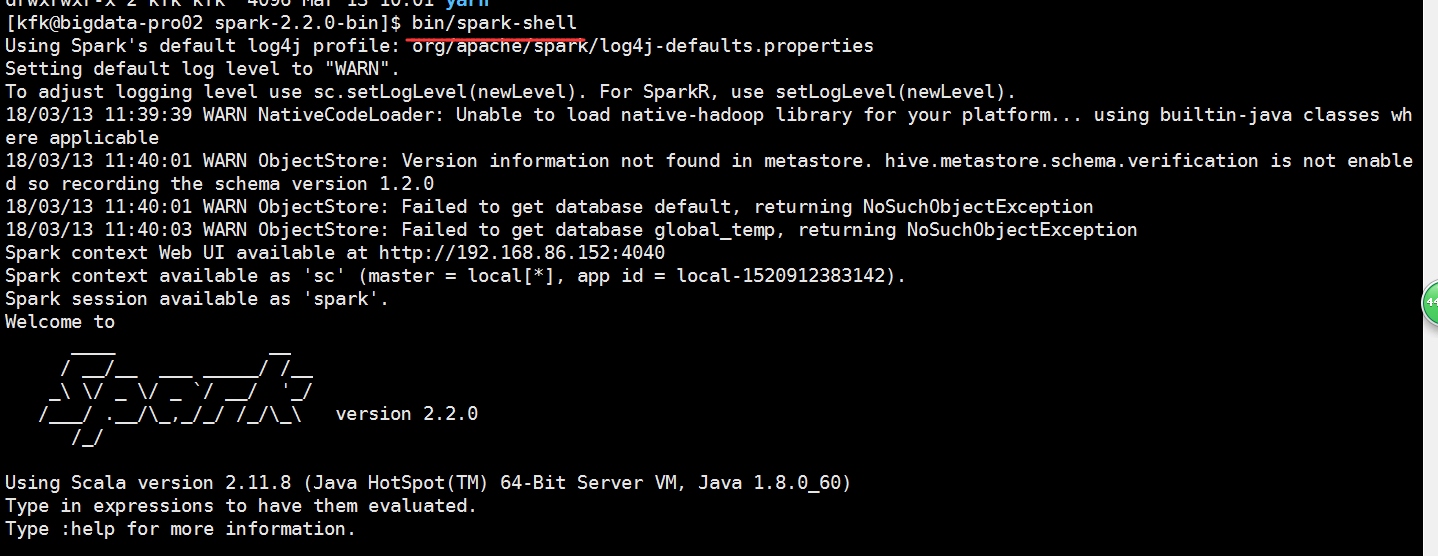
我们运行一下

./dev/make-distribution.sh --name custom-spark --tgz -Phadoop-2.6 -Phive -Phive-thriftserver -Pyarn
这个过程非常长,网络好机器配置好的话也许一个小时吧,如果中途网络不好失败的话就重新来吧

我自己这里也是经过了一次失败之后,再重新运行一次这条语句就可以了,当看到build success字样的时候就说明成功了
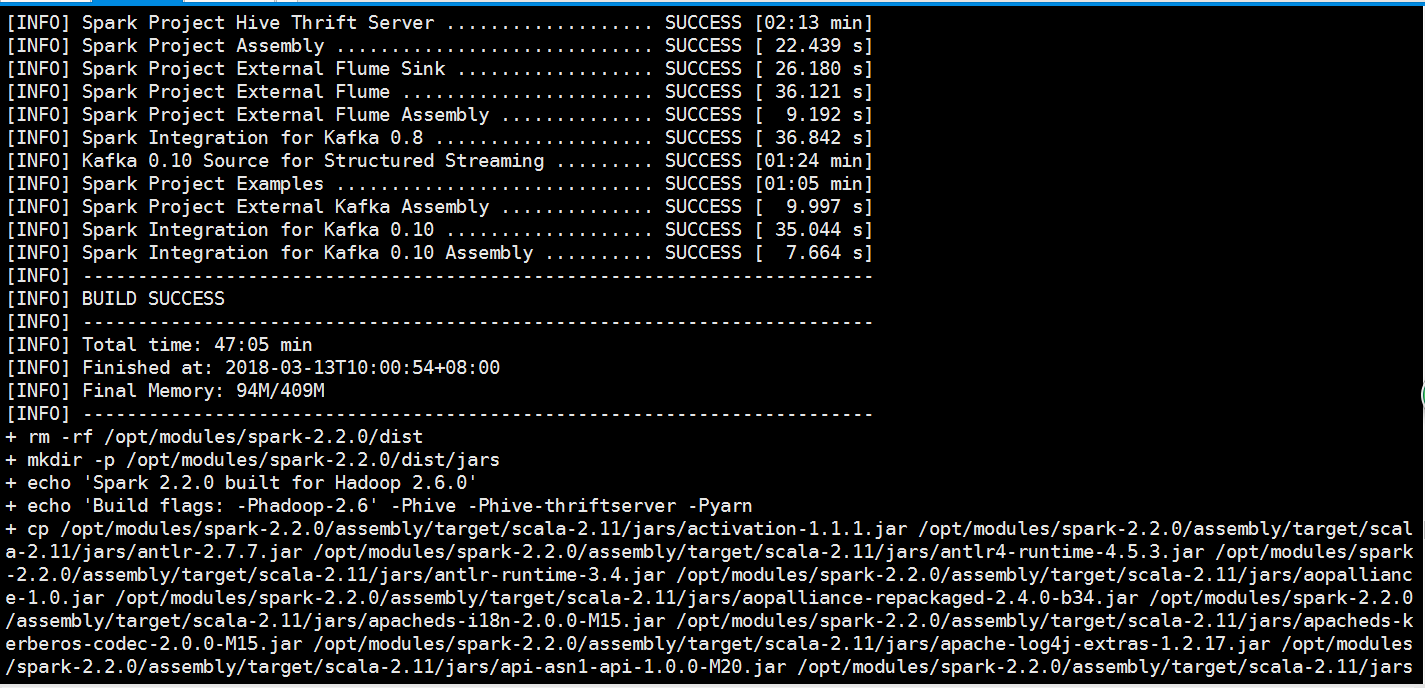
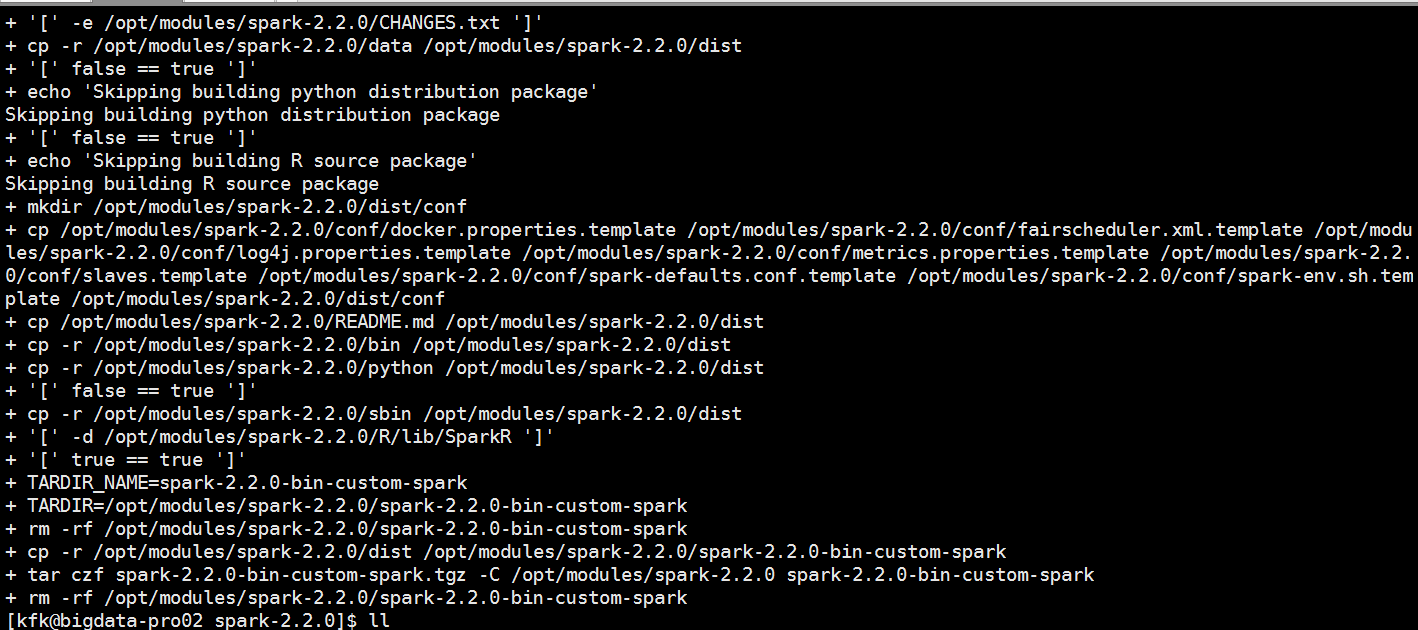
在spark的目录下会多了一个踏包

解压

改一下名字
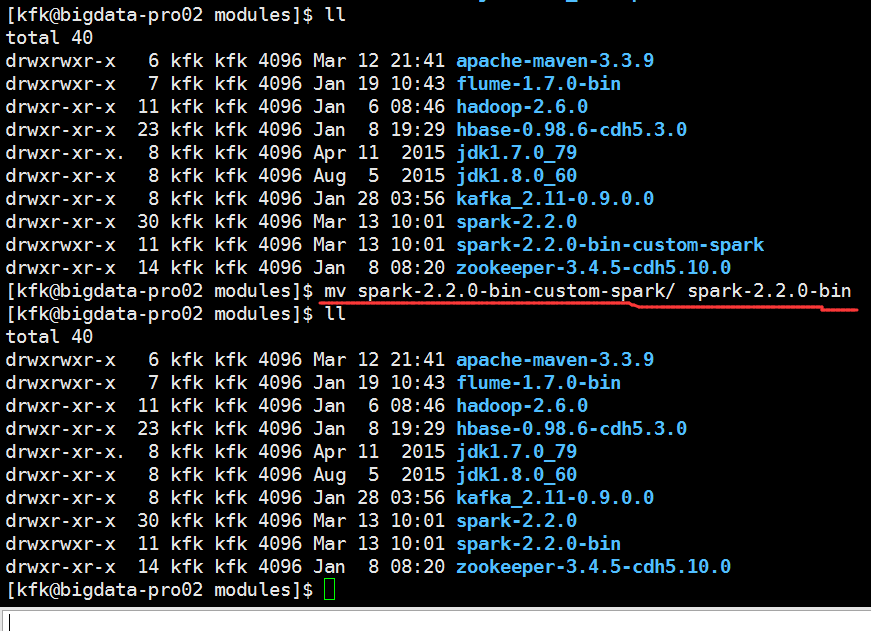

解压
接下来配置环境变量

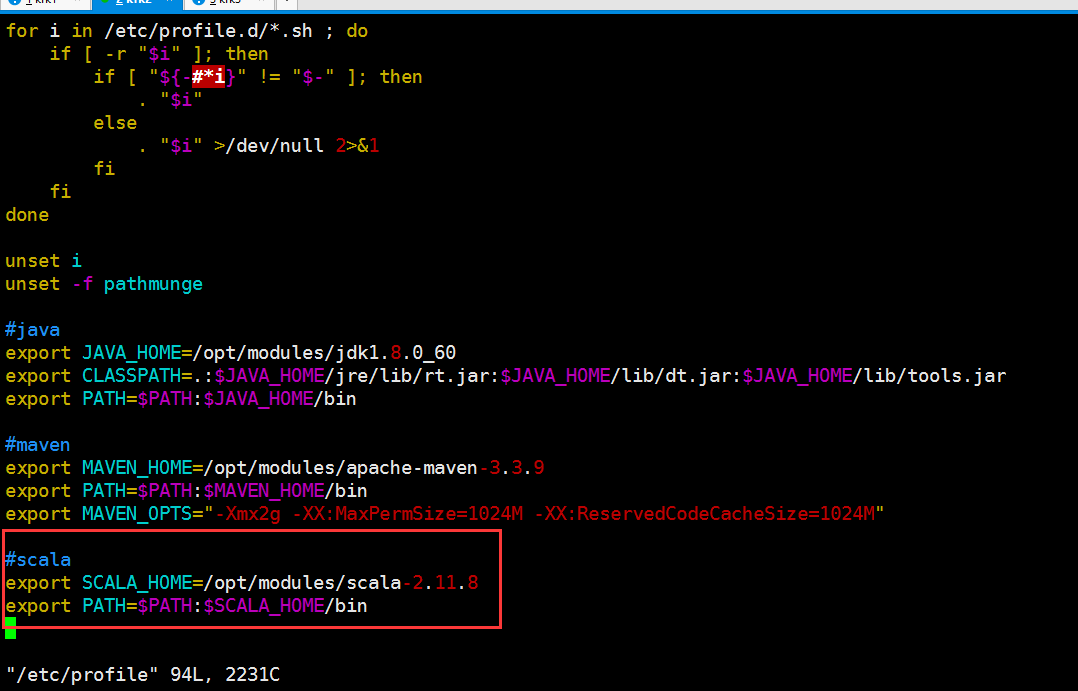
#scala export SCALA_HOME=/opt/modules/scala-2.11.8 export PATH=$PATH:$SCALA_HOME/bin
使环境变量生效





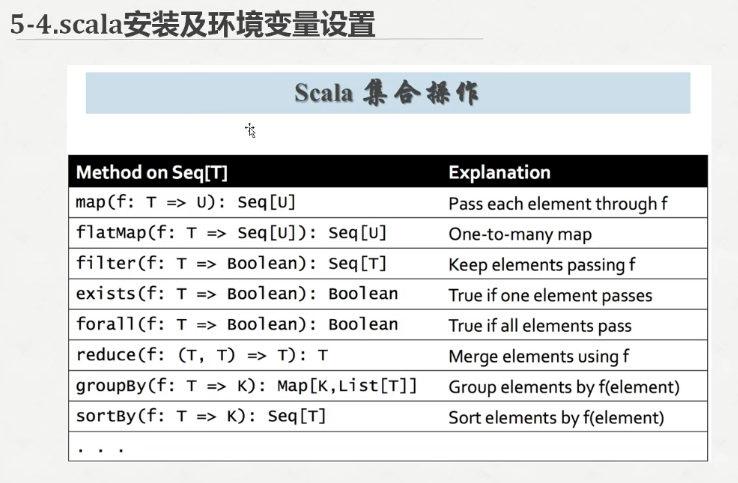

读取文件

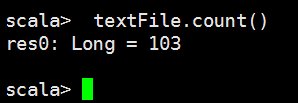
统计有多少行
文件的第一行

前4行


我们先新建一个数据文件


把文件读取进来

用空格切分

以key value对的方式显示出来

这里报错

下面我们打开spark的系统监控页面


创建缓存

使用一下

这里就有反馈了


相关文章推荐
- Ubuntu12.04(64bit)上部署编译运行Openfire+Spark环境
- Ubuntu12.04(64bit)上部署编译运行Openfire+Spark环境
- Spark编译与部署(上)--基础环境搭建
- 部署、编译、运行spark
- SQL入门前期准备 第一次接触SQL 第一次运行SQL代码 SQL编译环境 SQL新手
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
- Spark源代码在Eclipse3.5.2中的部署、编译、运行
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
- Spark集群环境搭建+Maven、SBT编译部署+IDEA开发(一)
- Spark集群环境搭建+Maven、SBT编译部署+IDEA开发(二)
- spark学习8之eclipse安装scala2.10和spark编译环境并上传到集群运行
- Xamarin 跨移动端开发系列(01) -- 搭建环境、编译、调试、部署、运行
- Spark-基础-Spark编译与部署环境搭建
- spark学习7之IDEA下搭建Spark本地编译环境并上传到集群运行
- Spark2.1.0——运行环境准备
- Spark编译与部署(上)--基础环境搭建
- windows 环境下部署spark运行环境 (包含遇到的问题和解决方法)
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
- spark:Idea编译程序打jar包部署到spark运行方法--19
- Xamarin 跨移动端开发系列(01) -- 搭建环境、编译、调试、部署、运行