超融合集群数据分布原理
2018-03-13 14:17
246 查看
超融合是通过软件定义基础架构整合计算、存储、网络和虚拟化资源。超融合基础架构的目标是提供更为简易的方式,它通过软件定义存储和服务器虚拟化的整合,以替代传统SAN存储的方式来建设数据中心。超融合更注重基于低成本的X86服务器来达到数据的管理和控制。在超融合中,集群数据分布起了较关键的作用。
PG(Placement Group)——顾名思义,PG的用途是对object的存储进行组织和位置映射。具体而言,一个PG负责组织若干个object(可以为数千个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是“多对多”映射关系。在实践当中,n至少为2,如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。
OSD —— 即Object Storage Device主要功能包括:存储数据,副本数据处理,数据恢复,数据回补,平衡数据分布,并将数据相关的一些儿监控信息提供给至少2个 OSD,才能有效保存两份数据。
软件定义存储(WinStore)基于开源的Ceph并做了深度的优化和功能开发。云宏在2015年超融合元年推出了Winhong HCI v1.0,WinStore以模块化的方式运行在WinServer中而不是运行在虚拟机上,WinStore可以将多台物理机上面的本地SSD和HDD组成一个虚拟的存储池,利用多台x86服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
CRUSH算法有以下特征:
去中心化架构,无元数据服务器,读写性能不会因为集群的扩大而降低;
在相同的环境下,相似的输入得到的结果之间没有相关性,相同的输入得到的结果是确定的;
确保数据尽可能的平均分布在集群的各个节点的所有硬盘上;
在增删节点导致存储目标数量出现变化时,能够最小化集群间的数据迁移量;
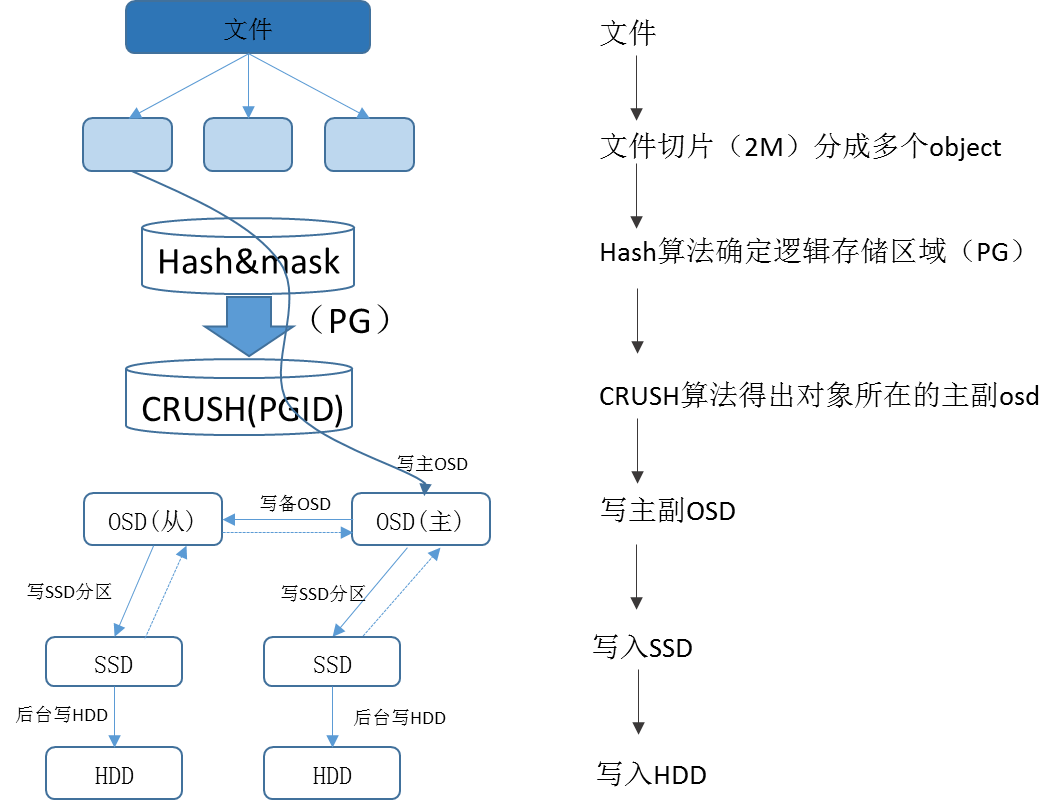
WinStore首先将文件分片(2M),分成多个object,产生object id;
根据虚拟磁盘所属的存储池Pool和object id,通过哈希算法和取模,得出所属的PG(Placement Group)的ID;PG 在 Pool 被创建后就会根据 CRUSH 算法计算出来的 PG 应该所在若干的 OSD 上被创建出来了。也就是说,在客户端写入对象的时候,PG 已经被创建好了,PG 和 OSD 的映射关系已经是确定了的;
然后将PG的值传给CRUSH算法,由CRUSH算法得出对应的主从OSD;
数据写入到与主从OSD所对应的SSD后,即给上层的业务系统返回写入成功的信息;
最后WinStore会根据一定的规则,将SSD中的数据刷写到持久化存储HDD磁盘中。
由此可见,系统指定的一个静态哈希函数计算object id的哈希值,将object id映射成为一个近似均匀分布的伪随机值。然后,将这个伪随机值和mask按位相与,得到最终的PG序号(pgid)。根据系统的设计,给定PG的总数为m(m应该为2的整数幂),则mask的值为m-1。因此,哈希值计算和按位与操作的整体结果事实上是从所有m个PG中近似均匀地随机选择一个。基于这一机制,当有大量object和大量PG时,RADOS能够保证object和PG之间的近似均匀映射。又因为object是由file切分而来,大部分object的size相同
4000
,因而,这一映射最终保证了,各个PG中存储的object的总数据量近似均匀。
其中PG映射到OSD中使用CRUSH算法,而不是其他哈希算法,原因之一正是CRUSH具有可配置特性,可以根据管理员的配置参数决定OSD的物理位置映射策略;另一方面是因为CRUSH具有特殊的“稳定性”,也即,当系统中加入新的OSD,导致系统规模增大时,大部分PG与OSD之间的映射关系不会发生改变,只有少部分PG的映射关系会发生变化并引发数据迁移。
这种可配置性和稳定性都不是普通哈希算法所能提供的。因此,CRUSH算法的设计也是WinStore的核心内容之一。
超融合集群数据分布概念
Ojbect —— object即“对象”,是文件切片后生产的逻辑对象,object的最大size通常限定为2MB或4MB,以便实现底层存储的组织管理。PG(Placement Group)——顾名思义,PG的用途是对object的存储进行组织和位置映射。具体而言,一个PG负责组织若干个object(可以为数千个甚至更多),但一个object只能被映射到一个PG中,即,PG和object之间是“一对多”映射关系。同时,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,即,PG和OSD之间是“多对多”映射关系。在实践当中,n至少为2,如果用于生产环境,则至少为3。一个OSD上的PG则可达到数百个。
OSD —— 即Object Storage Device主要功能包括:存储数据,副本数据处理,数据恢复,数据回补,平衡数据分布,并将数据相关的一些儿监控信息提供给至少2个 OSD,才能有效保存两份数据。
软件定义存储
云宏超融合是整合了自主研发的服务器虚拟化平台CNware和自主研发的高性能分布式文件系统WinStore。软件定义存储(WinStore)基于开源的Ceph并做了深度的优化和功能开发。云宏在2015年超融合元年推出了Winhong HCI v1.0,WinStore以模块化的方式运行在WinServer中而不是运行在虚拟机上,WinStore可以将多台物理机上面的本地SSD和HDD组成一个虚拟的存储池,利用多台x86服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
数据分布算法-CRUSH算法
CRUSH算法是WinStore的基石,是一种可扩展的伪随机数据分布算法,用于控制数据的分布,能够高效稳定的将数据分布在普通的结构化集群中。CRUSH算法有以下特征:
去中心化架构,无元数据服务器,读写性能不会因为集群的扩大而降低;
在相同的环境下,相似的输入得到的结果之间没有相关性,相同的输入得到的结果是确定的;
确保数据尽可能的平均分布在集群的各个节点的所有硬盘上;
在增删节点导致存储目标数量出现变化时,能够最小化集群间的数据迁移量;
数据分布过程
WinServer与WinStore融合部署,WinServer虚拟机的虚拟磁盘直接使用WinStore提供的rbd块设备。在虚拟机上一个文件的写入过程中,首先会将文件分片,分成多个object,每一个object都可能会写入到不同的HDD(OSD)上,均衡分散到整个集群中。WinStore首先将文件分片(2M),分成多个object,产生object id;
根据虚拟磁盘所属的存储池Pool和object id,通过哈希算法和取模,得出所属的PG(Placement Group)的ID;PG 在 Pool 被创建后就会根据 CRUSH 算法计算出来的 PG 应该所在若干的 OSD 上被创建出来了。也就是说,在客户端写入对象的时候,PG 已经被创建好了,PG 和 OSD 的映射关系已经是确定了的;
然后将PG的值传给CRUSH算法,由CRUSH算法得出对应的主从OSD;
数据写入到与主从OSD所对应的SSD后,即给上层的业务系统返回写入成功的信息;
最后WinStore会根据一定的规则,将SSD中的数据刷写到持久化存储HDD磁盘中。
由此可见,系统指定的一个静态哈希函数计算object id的哈希值,将object id映射成为一个近似均匀分布的伪随机值。然后,将这个伪随机值和mask按位相与,得到最终的PG序号(pgid)。根据系统的设计,给定PG的总数为m(m应该为2的整数幂),则mask的值为m-1。因此,哈希值计算和按位与操作的整体结果事实上是从所有m个PG中近似均匀地随机选择一个。基于这一机制,当有大量object和大量PG时,RADOS能够保证object和PG之间的近似均匀映射。又因为object是由file切分而来,大部分object的size相同
4000
,因而,这一映射最终保证了,各个PG中存储的object的总数据量近似均匀。
其中PG映射到OSD中使用CRUSH算法,而不是其他哈希算法,原因之一正是CRUSH具有可配置特性,可以根据管理员的配置参数决定OSD的物理位置映射策略;另一方面是因为CRUSH具有特殊的“稳定性”,也即,当系统中加入新的OSD,导致系统规模增大时,大部分PG与OSD之间的映射关系不会发生改变,只有少部分PG的映射关系会发生变化并引发数据迁移。
这种可配置性和稳定性都不是普通哈希算法所能提供的。因此,CRUSH算法的设计也是WinStore的核心内容之一。

相关文章推荐
- Elasticsearch之数据如何在集群中分布和获取。
- 大数据教程(3.4):zookeeper集群角色分配原理
- swift数据分布原理分析博文推荐
- 2 weekend110的zookeeper的原理、特性、数据模型、节点、角色、顺序号、读写机制、保证、API接口、ACL、选举、 + 应用场景:统一命名服务、配置管理、集群管理、共享锁、队列管理
- [Oracle] 炼数成金Oracle 12C RAC集群原理与管理实战 + 玩转数据库 释放数据价值
- Elasticsearch之重要核心概念(cluster(集群)、shards(分配)、replicas(索引副本)、recovery(据恢复或叫数据重新分布)、gateway(es索引的持久化存储方式)、discovery.zen(es的自动发现节点机制机制)、Transport(内部节点或集群与客户端的交互方式)、settings(修改索引库默认配置)和mappings)
- 027 关于大数据中的分布集群的搭建
- kafka集群partition分布原理分析
- 如何处理集群、分布架构的数据同步问题
- Linux下基于LVS的集群原理及配置方法
- hadoop单线程实现server多socket连接读取数据原理分析
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
- Quartz应用与集群原理分析
- MYSQL集群管理节点和数据节点的检测脚本
- 集群仲裁盘voting disk的原理
- 大数据之路-Hadoop-5-HDFS原理解析及NameNode、DataNode工作机制
- 北京租赁住房用地分布,八张大数据图表让你一目了然!
- 《coredump问题原理探究》windows版5.1节基本数据类型
- Zookeeper 集群伪分布 在 Windows下的安装
- TroubleShooting - 迁移到集群环境数据错乱问题