2018-03-09 第二章 认识数据
2018-03-12 15:10
120 查看
本章主要内容为:介绍数据的不同类型、描述属性数据的中心趋势、和散布的统计度量,以及数据的可视化技术。
a. 属性(attribute):数据库和数据仓库领域;
b. 维(dimension):数据仓库;
c. 特征(feature):机器学习;
d. 变量(variable):统计学领域。
非对称: HIV:positive,negtive c. 序数属性:取值是具有有意义的序或秩评定(ranking),但是相继值之间的差是未知的。e.g.
drink_size: small,middle,big d. 数值属性:定量的、可以度量的值,用整数或实数表示。分为区间标度属性和比率标度属性。区间标度属性可以比较和定量评估值之间的差值;比率标度属性可以说一个值是另一个的倍数或比率。e.g.
区间标度属性:tempeture:20℃ is 5℃ higher than 15℃
比率标度属性:100$ is 100 times than 1$. e. 离散属性与连续属性:离散属性具有有限或无限可数个值;如果属性不是离散的,就是连续的。
均值对极端值(例如:离群点)很敏感,截尾均值是丢弃高低极端值后的均值。
中位数(median):中位数是有序数据值的中间值,计算方法略;
众数(mode):出现最频繁的值,可以对定性和定量属性确定众数。最高频率可能会对应不同值,导致多个众数。
具有一个、两个、三个众数的数据集合分别称为单峰(unimodal)、双峰(bimodal)、三峰(trimo
4000
dal)
有如下经验关系: mean-mode=3*(mean-median)
中列数(midrange):数据集的最大和最小值平均值
分位数: 取自数据分布的每隔一定间隔上的点,把数据划分成基本上大小相等的连贯集合
四分位数:把数据分布划分成4个相等的部分,使得每部分表示数据分布的四分之一的点。
四分位数极差:第1个分位数和第三个分位数之间的距离 IQR=Q3-Q1
识别可疑的离群点的通常规则是:落在第3个四分位数之上或者第1个四分位数之下至少1.5倍IQR处的值
方差和标准差:略
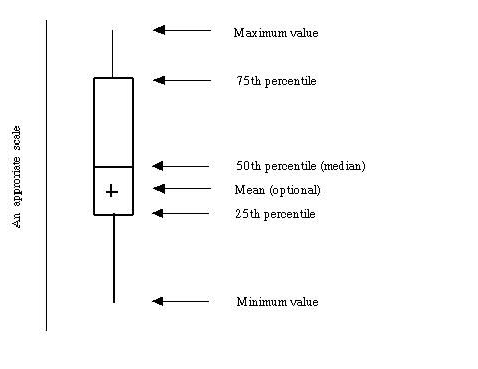
盒图:五数概括(图片来自百度百科)
a. 盒的端点一般在四分位数上,使得盒的长度是四分位数极差IQR
b. 中位数用盒内的线标记
c. 盒外的两条线延伸到最大和最小观测值(如果最值不超过1.5倍IQR的时候,延伸到最值;若是超过,延伸到1.5倍IQR范 围内的最极端的观测值,剩下的情况个别绘出)
分位数-分位数图(quantile-quantile plot):q-q图,对着另一个对应的分位数,绘制一个单变量分布的分位数
直方图(histogram):略
散点图(scatter plot):确定两个数值变量之间看上去是否存在联系、模式或者趋势。
p:刻画对象的属性总数
m:对象i和对象j取值相同状态的属性数二元属性的列联表
对于非对称的二元属性来说,两个值同时取0被认为是无意义的,会直接忽略

欧几里得距离(直线距离):闵可夫斯基距离式子中,p=2曼哈顿距离(城市块距离):闵可夫斯基距离式子中,p=1
上确界距离(切比雪夫距离):闵可夫斯基距离式子中,p=+∞ ,约等于在某个属性上,两个对象的最大值差
2.1 数据对象与属性类型
2.1.1 什么是属性
属性是一个数据字段,表示数据对象的一个特征。不同领域,叫法不同。a. 属性(attribute):数据库和数据仓库领域;
b. 维(dimension):数据仓库;
c. 特征(feature):机器学习;
d. 变量(variable):统计学领域。
2.1.2 属性的类型
a. 标称属性:属性值是一些符号或事物的名称,每个值代表某种类别、编码或者状态。可以用数表示,但是在标称属性上数学运算没有意义。也就是标称属性不是数值属性,不能定量的使用这些整数。 e.g. hair_color:black,blue,red,browm.... occupation:doctor,teacher,coder,... b. 二元属性:是一种特殊的标称属性,只有两个类别或者状态:0或1. 0表示属性不出现,1表示出现。类似CS中的bool属性。 分为对称的二元属性和非对称的二元属性。 对称是指两种状态是否具有同样的价值、携带相同的权重。对称: gender:male,female非对称: HIV:positive,negtive c. 序数属性:取值是具有有意义的序或秩评定(ranking),但是相继值之间的差是未知的。e.g.
drink_size: small,middle,big d. 数值属性:定量的、可以度量的值,用整数或实数表示。分为区间标度属性和比率标度属性。区间标度属性可以比较和定量评估值之间的差值;比率标度属性可以说一个值是另一个的倍数或比率。e.g.
区间标度属性:tempeture:20℃ is 5℃ higher than 15℃
比率标度属性:100$ is 100 times than 1$. e. 离散属性与连续属性:离散属性具有有限或无限可数个值;如果属性不是离散的,就是连续的。
2.2 数据的基本统计描述
2.2.1 中心趋势度量:均值、中位数和众数
均值(mean):普通均值与加权均值,计算方法略;均值对极端值(例如:离群点)很敏感,截尾均值是丢弃高低极端值后的均值。
中位数(median):中位数是有序数据值的中间值,计算方法略;
众数(mode):出现最频繁的值,可以对定性和定量属性确定众数。最高频率可能会对应不同值,导致多个众数。
具有一个、两个、三个众数的数据集合分别称为单峰(unimodal)、双峰(bimodal)、三峰(trimo
4000
dal)
有如下经验关系: mean-mode=3*(mean-median)
中列数(midrange):数据集的最大和最小值平均值
2.2.2 数据散布度量:极差、四分位数、方差、标准差和四分位数极差
极差:最大值与最小值之间的差值 max-min分位数: 取自数据分布的每隔一定间隔上的点,把数据划分成基本上大小相等的连贯集合
四分位数:把数据分布划分成4个相等的部分,使得每部分表示数据分布的四分之一的点。
四分位数极差:第1个分位数和第三个分位数之间的距离 IQR=Q3-Q1
识别可疑的离群点的通常规则是:落在第3个四分位数之上或者第1个四分位数之下至少1.5倍IQR处的值
方差和标准差:略
盒图:五数概括(图片来自百度百科)
a. 盒的端点一般在四分位数上,使得盒的长度是四分位数极差IQR
b. 中位数用盒内的线标记
c. 盒外的两条线延伸到最大和最小观测值(如果最值不超过1.5倍IQR的时候,延伸到最值;若是超过,延伸到1.5倍IQR范 围内的最极端的观测值,剩下的情况个别绘出)
2.2.3 数据的基本统计描述的图形表示
分位数图(quantile plot):分位数-分位数图(quantile-quantile plot):q-q图,对着另一个对应的分位数,绘制一个单变量分布的分位数
直方图(histogram):略
散点图(scatter plot):确定两个数值变量之间看上去是否存在联系、模式或者趋势。
2.3 数据可视化
通过图形表示来表达数据,有基于像素的可视化、基于图符的可视化(切尔诺夫脸)、几何投影可视化、层次可视化技术、树图、标签云。2.4 度量数据的相似性和相异性
2.4.1 数据矩阵与相异性矩阵
数据矩阵:对象-属性结构,行代表对象,列代表属性,又称为二模矩阵;相异性矩阵:对象-对象结构,存放n个对象两两之间的临近度(proximity)、差别、距离,又称为单模矩阵。2.4.2 标称属性的邻近性度量
两个对象i和j之间的相异性可以根据不匹配率计算:相异性(距离): d(i,j)=(p-m)/p 相似性:sim(i,j)=1-d(i,j)p:刻画对象的属性总数
m:对象i和对象j取值相同状态的属性数
2.4.3 二元属性的邻近性度量
| 对象j | ||||
|---|---|---|---|---|
| 1 | 0 | sum | ||
| 对象i | 1 | q | r | q+r |
| 0 | s | t | s+t | |
| sum | q+s | r+t | p=q+r+s+t |
对称的二元相异性:d(i,j)=(r+s)/(q+r+s+t) 非对称的二元相异性:d(i,j)=(r+s)/(q+r+s)
2.4.4 数值属性的相异性
闵可夫斯基距离(Minkowski distance):欧几里得距离(直线距离):闵可夫斯基距离式子中,p=2曼哈顿距离(城市块距离):闵可夫斯基距离式子中,p=1
上确界距离(切比雪夫距离):闵可夫斯基距离式子中,p=+∞ ,约等于在某个属性上,两个对象的最大值差
2.4.5 序数属性的邻近性度量
将序数属性用不同的状态数表示,转为数值属性计算。2.4.6 余弦相似性
如度量两个文档的相似性,将每个文档用一个词频向量表示,计算两个向量之间的夹角余弦。
相关文章推荐
- 数据挖掘读书笔记--第二章:认识数据
- 第二章 认识数据
- 第二章 认识数据 笔记
- 第二章 认识数据
- Excel在统计分析中的应用—第二章—描述性统计-分组数据的方差求解方法
- 大数据究竟是什么?一篇文章让你认识并读懂大数据
- 【C】【笔记】《C和指针》 第一章 快速上手 第二章 基本概念 第三章 数据 第四章 语句 第五章 操作符和表达式
- 《Hadoop生态》——第二章 数据库与数据管理——Spark SQL (formerly Shark)
- 第二章 开始认识XAML (1)
- (2)认识Lucene:检索数据
- 实时数据库领域中有关数据压缩的认识误区
- Head First Python 第二章 函数模块&第三章 文件与异常&第四章 持久存储&第五章 处理数据
- [翻译]C#数据结构与算法 – 第二章(Part1)
- 对数据更新的认识
- 认识django2.0读书笔记(2)---第二章 入门
- 大数据究竟是什么?一篇文章让你认识并读懂大数据[转]
- [翻译]C#数据结构与算法 – 第二章(Part2完)
- 第二章,数据类型和运算符
- 重新认识excel(4):数据的位置
- 视频教程 一起搞大C#-初级篇 第二章 变量、数据类型(上)