CUDA编程-(2)其实写个矩阵相乘并不是那么难
2018-03-09 10:54
465 查看
程序代码及图解析:
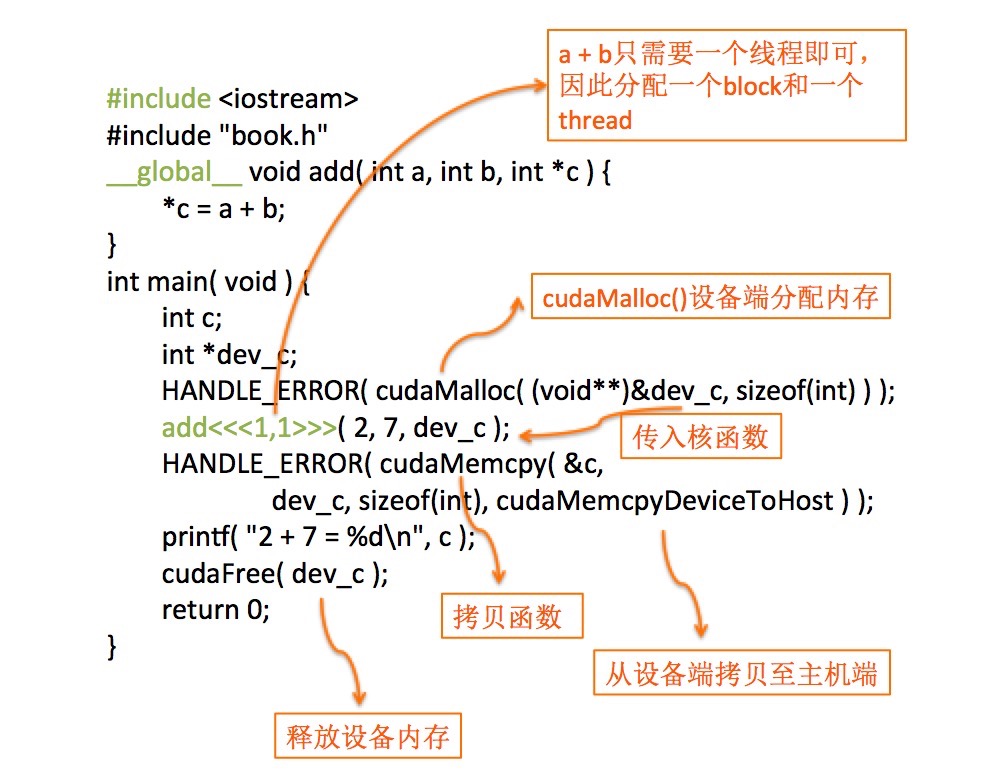
函数原型:__host__cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)作用:在设备端和主机端拷贝数据。参数:dst 目的地址 src 源地址 count 拷贝字节大小kind 传输的类型返回值:cudaSuccess, cudaErrorInvalidValue, cudaErrorInvalidDevicePointer, cudaErrorInvalidMemcpyDirection说明:从源地址拷贝设定数量的字节数至目的地址,kind类型有四种,分别为:cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice,通过指定方向进行拷贝。存储器区域不可重叠。如若产生未定义拷贝方向的行为,dst和src将不匹配。
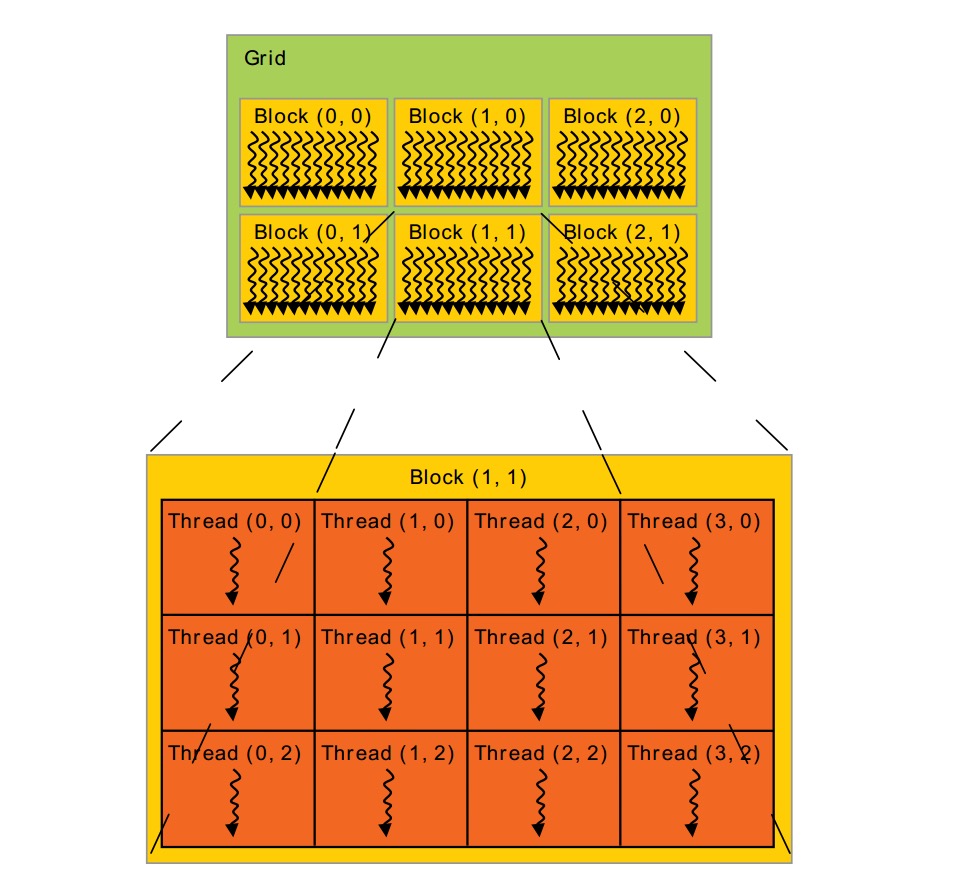
其中T表示变量threadIdx。(Dx, Dy, Dz)为block的size(每一维有多少threads)。因为一个block内的所有threads会在同一处理器内核上共享内存资源,所以block内有多少threads是有限制的。目前GPU限制每个 block最多有1024个threads。但是一个kernel可以在多个相同shape的block上执行,效果等效于在一个有N*#thread per block个thread的block上执行。Block又被组织成grid。同样,grid中block也可以被组织成1维,2维or3维。一个grid中的block数量由系统中处理器个数或待处理的数据量决定。(来自这里)
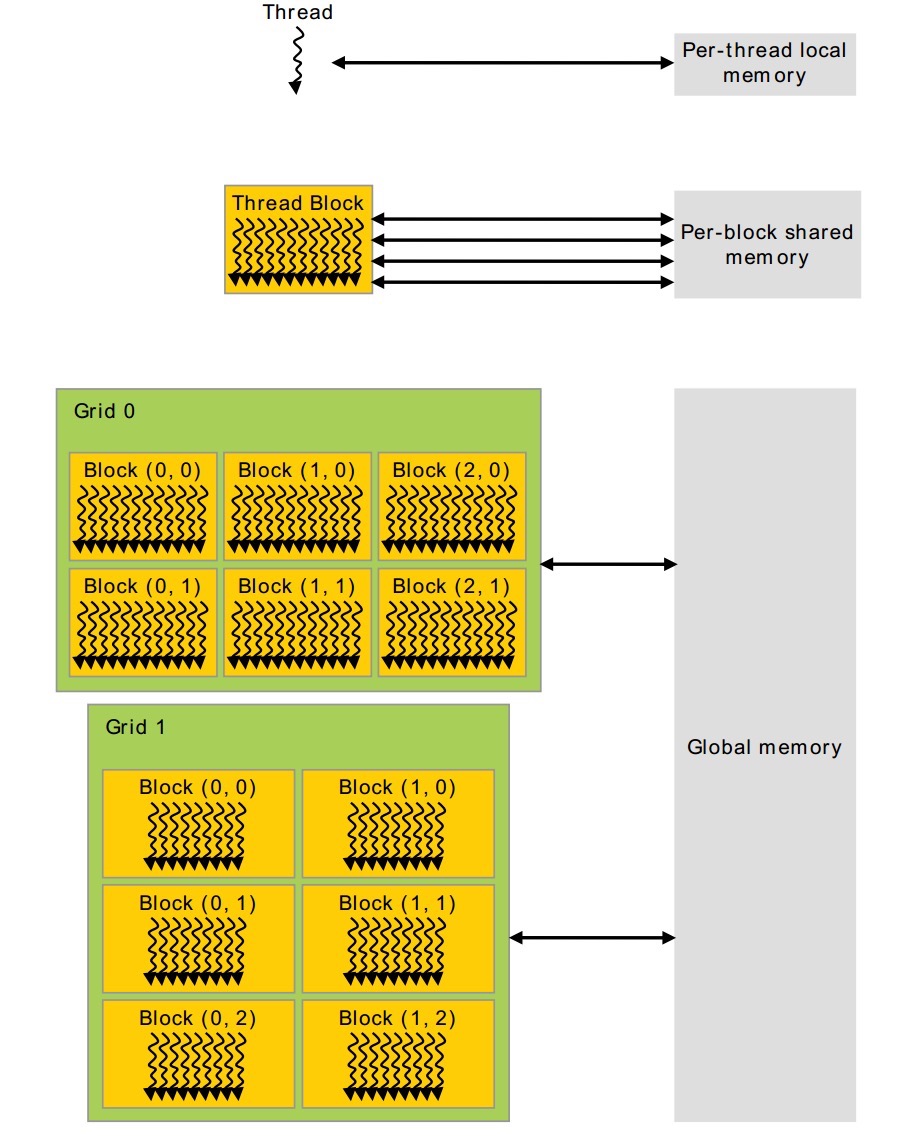
下图中描述了Thread、Block、Grid内存的访问机制。每个thread有自己的local-memory。每一个block有自己的共享内存、grid和grid之间可以同时访问全局内存。这里要注意:block和block之间不能访问同一个共享内存,他们只能访问自己的共享内存。
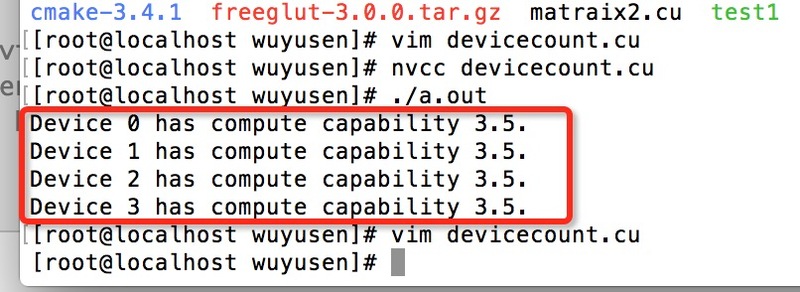
cudaGetDeviceCount( &count )查询服务器的CUDA信息.
结果:
矩阵相乘也非常简单,难在如何在这个基础上提高速率。比如:引入sharememory。代码:
share memory 改进。加入同步机制 __syncthreads(),即 等待之前的所有线程执行完毕后再接下去执行。
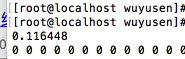
share memory执行时间:

注意,核函数内不是所有线程一起进去执行,这个概念模糊不清。我们需要理解成,所有的线程并行执行核函数里面的程序,即每一个线程都会执行该函数,所有线程执行完,即结束。这个简单的概念,我一开始想了很久。
函数原型:__host__cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)作用:在设备端和主机端拷贝数据。参数:dst 目的地址 src 源地址 count 拷贝字节大小kind 传输的类型返回值:cudaSuccess, cudaErrorInvalidValue, cudaErrorInvalidDevicePointer, cudaErrorInvalidMemcpyDirection说明:从源地址拷贝设定数量的字节数至目的地址,kind类型有四种,分别为:cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToDevice,通过指定方向进行拷贝。存储器区域不可重叠。如若产生未定义拷贝方向的行为,dst和src将不匹配。
正文
前面的图是最简单的一个CUDA程序,它引出了Grid Block Thread概念。很多threads组成1维,2维or3维的thread block. 为了标记thread在block中的位置(index),我们可以用上面讲的threadIdx。threadIdx是一个维度<=3的vector。还可以用thread index(一个标量)表示这个位置。thread的index与threadIdx的关系:| Thread index | |
| 1 | T |
| 2 | T.x + T.y * Dx |
| 3 | T.x+T.y*Dx+z*Dx*Dy |
下图中描述了Thread、Block、Grid内存的访问机制。每个thread有自己的local-memory。每一个block有自己的共享内存、grid和grid之间可以同时访问全局内存。这里要注意:block和block之间不能访问同一个共享内存,他们只能访问自己的共享内存。
cudaGetDeviceCount( &count )查询服务器的CUDA信息.
小结
第一个执行时间:share memory执行时间:
注意,核函数内不是所有线程一起进去执行,这个概念模糊不清。我们需要理解成,所有的线程并行执行核函数里面的程序,即每一个线程都会执行该函数,所有线程执行完,即结束。这个简单的概念,我一开始想了很久。

相关文章推荐
- CUDA编程-(2)其实写个矩阵相乘并不是那么难
- CUDA范例精解通用GPU架构-(2)其实写个矩阵相乘并不是那么难
- CUDA编程接口:共享存储器实现矩阵相乘
- CUDA编程接口:共享存储器实现矩阵相乘
- 【CUDA并行编程之四】矩阵相乘
- CUDA编程—通过shared memory优化矩阵相乘
- 【CUDA并行编程之四】矩阵相乘
- 其实编程不是那么恐怖----几句话
- cuda编程入门示例19---矩阵相乘
- 404 其实也不是那么讨厌
- 编程也不是那么奇妙.........
- CUDA 矩阵相乘
- 拜读了《婆媳关系好坏取决于老公》一文,看似有道理,细读感觉其实应该不是那么回事
- 一个优秀的的测试人员其实靠的并不是编程
- CUDA 矩阵相乘完整代码
- 编程实现两个矩阵相乘
- 简单点儿、简单点儿、再简单点儿,其实世界可以不是我们想象的那么复杂
- cuda编程基本概念和矩阵运算
- 加拿大学者:乔布斯不是爱迪生 其实没那么伟大
- 简单点儿、简单点儿、再简单点儿,其实世界可以不是我们想象的那么复杂