python3.6爬虫案例:爬取顶点小说(爱看小说同学的福利)
2018-03-08 15:52
597 查看
一、写在前面
这次本来打算爬百思不得姐视频的,谁料赶上此网站调整,视频专栏下线了,网站中也没有视频可爬。所幸先来说说如何爬取顶点小说吧。 顶点小说(https://www.x23us.com)里面的内容很丰富,不过我们要爬的话最好爬已经完结的全本小说(https://www.x23us.com/quanben/)。爬完我们可以直接将.txt文件放入手机看,很过瘾的哦。(本篇博客由于内容丰富,篇幅有点大,耐心看完給定下哦!)二、正文
1.任务说明
我们可以先将完本的所有小说的书名、作者、链接等爬下来,放到一个.txt文件中,等到爬某本小说的时候直接将链接放入即可。也许有人说,你这样多麻烦,没错我自己也觉得麻烦,但由于网站本身存在各种各样的网页格式问题,要想完全无人值守爬取所有小说是很有难度的。不过,我们真正的目的是学习嘛,作为学习的战利品够我们平时娱乐就好。2.爬取所有完本图书信息。
 我们打开全本栏,看下链接为:https://www.x23us.com/quanben/。我们打开网页可以发现小说位于一个表格内,通过网页源代码发现所有小说均位于<tr>标签下,该标签下面有小说的所有信息,大家看上图。有一点需要注意第一个<tr>为表的标题,我们爬取得时候要忽略这个标签,具体做法为:tr_list = html.find_all({'table','tr'})通过上面代码找到所有<tr>标签,下面我们通过切片工具和for语句实现该页所有小说的爬取:for tr in tr_list[2:]:#从第2个<tr>开始 book_info= tr.find_all({'td','a'})[2] book_name = book_info.text #获取书名 book_href = book_info['href'] #获取数的链接 author = tr.find('td',{'class':'C'}).text #获取作者姓名 news = book_name+';'+book_href+';'+author+'\n'是不是很简单,我们只需要将这些信息写入本地文件即可。具体爬取全本小说CrawlBookInfo.py的代码如下:"""爬取所有图书的名称、作者、链接等信息。"""import requestsimport timefrom bs4 import BeautifulSoup as bsdef get_html(url):html = requests.get(url)html.encoding = 'gbk'soup = bs(html.text, 'lxml')return soupf = open('F:\\python program\\顶点小说\\顶点小说所有图书信息.txt', 'w', encoding = 'utf-8')page = 1while page:url = 'https://www.x23us.com/quanben/'+str(page)try:html = get_html(url)except:print('爬取结束')breaktr_list = html.find_all({'table','tr'})for tr in tr_list[2:]:book_info= tr.find_all({'td','a'})[2]book_name = book_info.text #获取书名book_href = book_info['href'] #获取数的链接author = tr.find('td',{'class':'C'}).text #获取作者姓名news = book_name+';'+book_href+';'+author+'\n'f.write(news)# time.sleep(0.5)print(time.ctime()+';正在打印第'+str(page)+'页内容')page += 1f.close()对于网页的跳页,我个人的处理方式分为三种:(1)点开每页看链接的规律,此网站的链接就很有规律,https://www.x23us.com/quanben/'后面跟上页码就行了,不要管后面共有多少页,一直往下跑,通过while page判断停止程序爬取;(2)我们可以通过定位“下一页”或“next”元素位置,找到下页链接跳转。如下图:
我们打开全本栏,看下链接为:https://www.x23us.com/quanben/。我们打开网页可以发现小说位于一个表格内,通过网页源代码发现所有小说均位于<tr>标签下,该标签下面有小说的所有信息,大家看上图。有一点需要注意第一个<tr>为表的标题,我们爬取得时候要忽略这个标签,具体做法为:tr_list = html.find_all({'table','tr'})通过上面代码找到所有<tr>标签,下面我们通过切片工具和for语句实现该页所有小说的爬取:for tr in tr_list[2:]:#从第2个<tr>开始 book_info= tr.find_all({'td','a'})[2] book_name = book_info.text #获取书名 book_href = book_info['href'] #获取数的链接 author = tr.find('td',{'class':'C'}).text #获取作者姓名 news = book_name+';'+book_href+';'+author+'\n'是不是很简单,我们只需要将这些信息写入本地文件即可。具体爬取全本小说CrawlBookInfo.py的代码如下:"""爬取所有图书的名称、作者、链接等信息。"""import requestsimport timefrom bs4 import BeautifulSoup as bsdef get_html(url):html = requests.get(url)html.encoding = 'gbk'soup = bs(html.text, 'lxml')return soupf = open('F:\\python program\\顶点小说\\顶点小说所有图书信息.txt', 'w', encoding = 'utf-8')page = 1while page:url = 'https://www.x23us.com/quanben/'+str(page)try:html = get_html(url)except:print('爬取结束')breaktr_list = html.find_all({'table','tr'})for tr in tr_list[2:]:book_info= tr.find_all({'td','a'})[2]book_name = book_info.text #获取书名book_href = book_info['href'] #获取数的链接author = tr.find('td',{'class':'C'}).text #获取作者姓名news = book_name+';'+book_href+';'+author+'\n'f.write(news)# time.sleep(0.5)print(time.ctime()+';正在打印第'+str(page)+'页内容')page += 1f.close()对于网页的跳页,我个人的处理方式分为三种:(1)点开每页看链接的规律,此网站的链接就很有规律,https://www.x23us.com/quanben/'后面跟上页码就行了,不要管后面共有多少页,一直往下跑,通过while page判断停止程序爬取;(2)我们可以通过定位“下一页”或“next”元素位置,找到下页链接跳转。如下图: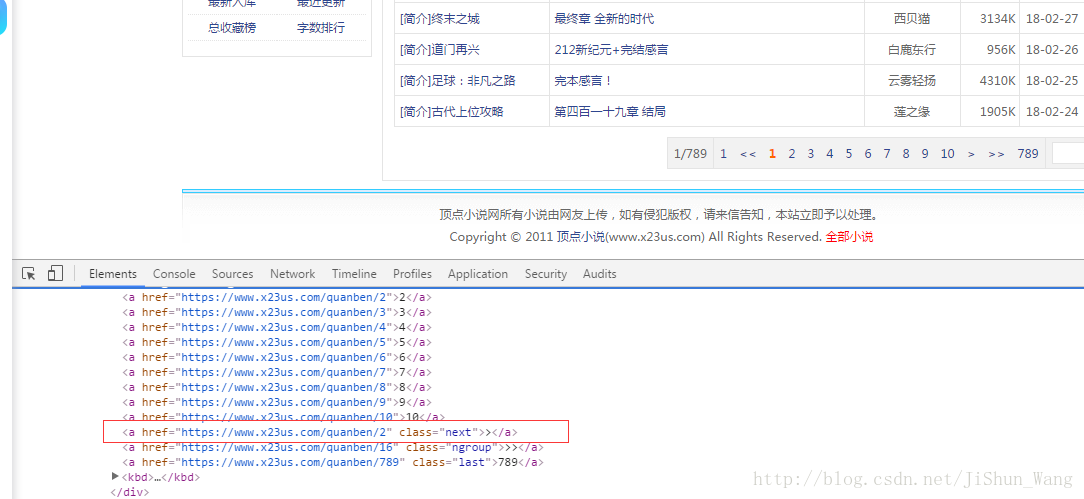 (3)有些网站的链接没有规律,元素定位也不容易,通过上面两种方法就有点束手无策了,这个时候我们要借助于selenium了,通过selenium跳转网页,拿到网页信息后再将网页内容用BeautifulSoup解析。总之,看哪个方便用哪个方法。
(3)有些网站的链接没有规律,元素定位也不容易,通过上面两种方法就有点束手无策了,这个时候我们要借助于selenium了,通过selenium跳转网页,拿到网页信息后再将网页内容用BeautifulSoup解析。总之,看哪个方便用哪个方法。2.小说内容的爬取
我们打开一本部小说,看下网页结构: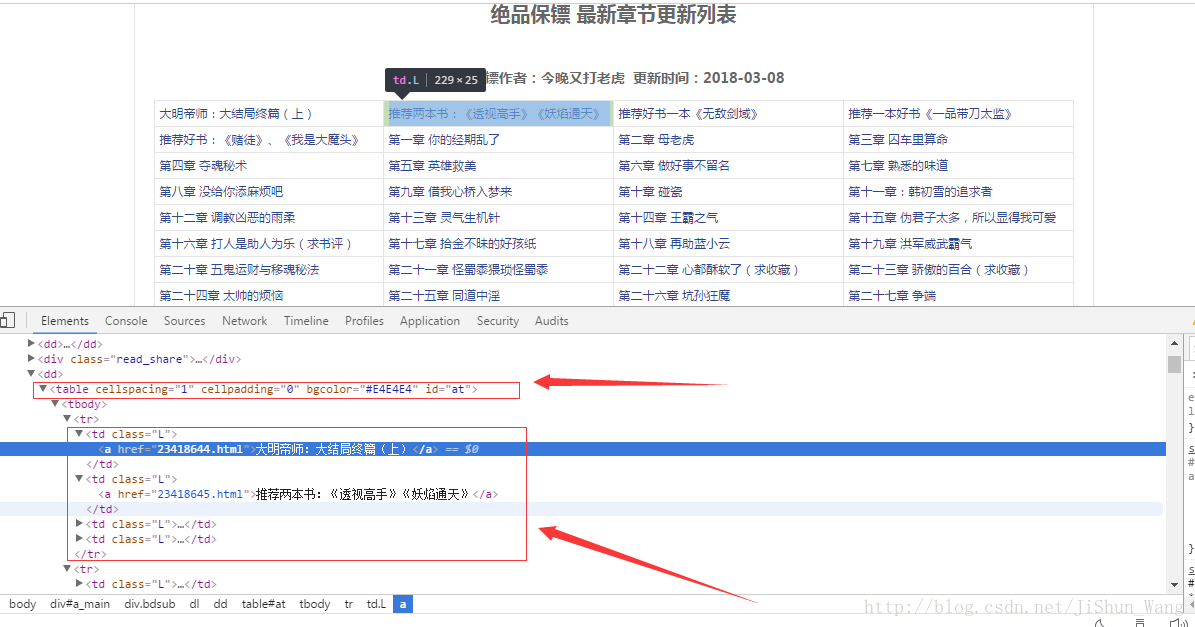 此时显示的是章节标题,点击每个标题才能进入每章的内容。由上图可知,所有的章节分布与表格中,每行通过<tr>标签标识,每行下面由<td>标识四列。继续打开<td>标签,发现下面的标签<a>内有每章内容的链接和标题,顿时思路清晰了。 不过还有一点,在我们爬取网页的时候,最好将每个网页都要看下,我们打开第一章
此时显示的是章节标题,点击每个标题才能进入每章的内容。由上图可知,所有的章节分布与表格中,每行通过<tr>标签标识,每行下面由<td>标识四列。继续打开<td>标签,发现下面的标签<a>内有每章内容的链接和标题,顿时思路清晰了。 不过还有一点,在我们爬取网页的时候,最好将每个网页都要看下,我们打开第一章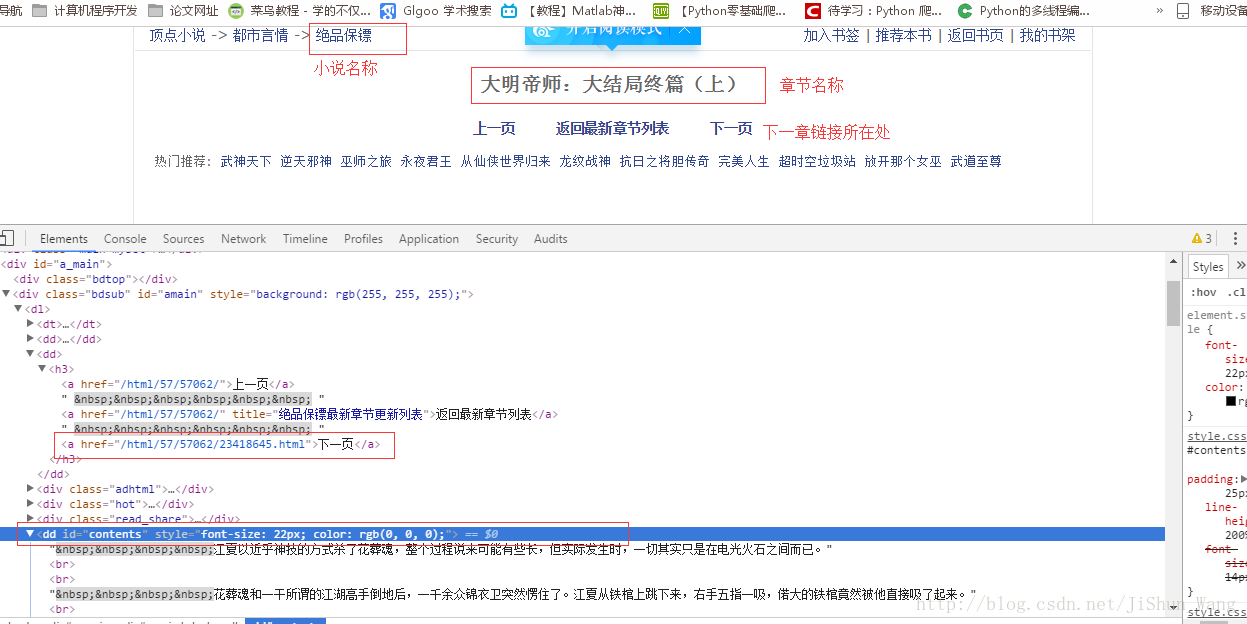 发现下一章的链接也能在这找到。所以我们就可以不用在小说目录页爬完所有章节链接然后再爬内容了,实际采取的方式是爬内容后爬下一章链接。其他细节问题,相信大家看代码就能够明白。"""代码功能:给定顶点网站一部小说的第一章链接,自动下载全部小说内容,由于爬取速度较快目前还不能实现完全无人值守。可能由于网站无响应,爬虫死掉,需要重新运行(将上次断开的链接再次放入程序即可)。"""import requestsimport timeimport numpy as npfrom bs4 import BeautifulSoup as bsURL = 'https://www.x23us.com'#获取网页内容def get_html(url):html = requests.get(url)html.encoding = 'gbk'soup = bs(html.text, 'lxml')return soupdef get_init_href(url):html = get_html(url)return url + html.find('table').find('tr').find('td').find('a')['href']def get_info(html):chapter_name = html.find('h1').get_text() #获取章节contents_raw = html.find('dd',{'id':'contents'})contents = contents_raw.get_text().replace(' ','\n ') #获取适合阅读的文本格式try:next_page_url = html.find('h3').find_all('a')[2]['href'] #获取下一页链接except:next_page_url = 0return chapter_name, contents, next_page_urldef main():url_read = 'https://www.x23us.com/html/25/25484/'#如果断了就修改这的链接。url_au = get_html(url_read)author_and_time = url_au.find('div', {'class': 'read_share'}).previous_sibling.text.replace('\xa0\xa0', ' ')url = get_init_href(url_read)html = get_html(url)text_title = html.find('dt').find_all('a')[-1].get_text()4000#获取书名#获取作者信息,更新时间f = open('F:\\python file\\顶点小说\\'+ text_title+'.txt', 'w', encoding='utf-8')f.write(author_and_time + '\n')chapter_name, contents, next_page_url = get_info(html)# next_page_url = '/html/0/338/155002.html'while next_page_url:print(time.ctime() + ';' + next_page_url + ';' + '正在打印' + chapter_name)f.write(chapter_name + '\n')f.write(contents)html = get_html(URL + next_page_url)f.write('\n')chapter_name, contents, next_page_url = get_info(html)time.sleep(np.random.rand()*3)f.close()if __name__ == '__main__':main()
发现下一章的链接也能在这找到。所以我们就可以不用在小说目录页爬完所有章节链接然后再爬内容了,实际采取的方式是爬内容后爬下一章链接。其他细节问题,相信大家看代码就能够明白。"""代码功能:给定顶点网站一部小说的第一章链接,自动下载全部小说内容,由于爬取速度较快目前还不能实现完全无人值守。可能由于网站无响应,爬虫死掉,需要重新运行(将上次断开的链接再次放入程序即可)。"""import requestsimport timeimport numpy as npfrom bs4 import BeautifulSoup as bsURL = 'https://www.x23us.com'#获取网页内容def get_html(url):html = requests.get(url)html.encoding = 'gbk'soup = bs(html.text, 'lxml')return soupdef get_init_href(url):html = get_html(url)return url + html.find('table').find('tr').find('td').find('a')['href']def get_info(html):chapter_name = html.find('h1').get_text() #获取章节contents_raw = html.find('dd',{'id':'contents'})contents = contents_raw.get_text().replace(' ','\n ') #获取适合阅读的文本格式try:next_page_url = html.find('h3').find_all('a')[2]['href'] #获取下一页链接except:next_page_url = 0return chapter_name, contents, next_page_urldef main():url_read = 'https://www.x23us.com/html/25/25484/'#如果断了就修改这的链接。url_au = get_html(url_read)author_and_time = url_au.find('div', {'class': 'read_share'}).previous_sibling.text.replace('\xa0\xa0', ' ')url = get_init_href(url_read)html = get_html(url)text_title = html.find('dt').find_all('a')[-1].get_text()4000#获取书名#获取作者信息,更新时间f = open('F:\\python file\\顶点小说\\'+ text_title+'.txt', 'w', encoding='utf-8')f.write(author_and_time + '\n')chapter_name, contents, next_page_url = get_info(html)# next_page_url = '/html/0/338/155002.html'while next_page_url:print(time.ctime() + ';' + next_page_url + ';' + '正在打印' + chapter_name)f.write(chapter_name + '\n')f.write(contents)html = get_html(URL + next_page_url)f.write('\n')chapter_name, contents, next_page_url = get_info(html)time.sleep(np.random.rand()*3)f.close()if __name__ == '__main__':main()3.改进程序
程序行不行,效率高不高,拿出来跑跑就可知晓。经过本人多次测试,发现程序爬取速度很慢,一会就断开,这可能是由于被网站后台的反爬虫机制屏蔽导致的。所以,试着在请求头加入header参数,修改了get_html(url)函数具体看代码:#获取网页内容def get_html(url):header = {'Accept': 'text/html, application/xhtml+xml, image/jxr, */*','Accept-Encoding':'gzip, deflate,br','Accept-Language':'zh-CN,zh;q=0.8','cookie':'targetEncodingwww23uscom=2; Hm_lvt_534ede4b11a35873e104d2b5040935e0=1514605870,1514622659,1514625352; Hm_lpvt_534ede4b11a35873e104d2b5040935e0=1514637350','Connection':'Keep-alive','Cache-Control':'max-age=0','Host':'www.x23us.com','User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257 Safari/9537.53'}html = requests.get(url,headers = header)html.encoding = 'gbk'soup = bs(html.text, 'lxml')return soup完整代码为:"""代码功能:给定顶点网站一部小说的第一章链接,自动下载全部小说内容,由于爬取速度较快目前还不能实现完全无人值守。可能由于网站无响应,爬虫死掉,需要重新运行(将上次短的链接喂进程序即可)。"""import requestsimport timeimport numpy as npfrom bs4 import BeautifulSoup as bsURL = 'https://www.x23us.com'#获取网页内容def get_html(url): header = {'Accept': 'text/html, application/xhtml+xml, image/jxr, */*', 'Accept-Encoding':'gzip, deflate,br', 'Accept-Language':'zh-CN,zh;q=0.8', 'cookie':'targetEncodingwww23uscom=2; Hm_lvt_534ede4b11a35873e104d2b5040935e0=1514605870,1514622659,1514625352; Hm_lpvt_534ede4b11a35873e104d2b5040935e0=1514637350', 'Connection':'Keep-alive', 'Cache-Control':'max-age=0', 'Host':'www.x23us.com', 'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257 Safari/9537.53'} html = requests.get(url,headers = header) html.encoding = 'gbk' soup = bs(html.text, 'lxml') return soupdef get_info(html):chapter_name = html.find('h1').get_text() #获取章节contents_raw = html.find('dd',{'id':'contents'})contents = contents_raw.get_text().replace(' ','\n ') #获取适合阅读的文本格式try:next_page_url = html.find('h3').find_all('a')[2]['href'] #获取下一页链接except:next_page_url = 0return chapter_name, contents, next_page_urldef main(): url = 'https://www.x23us.com/html/58/58089/27086498.html'#从本地读取 html = get_html(url) text_title = html.find('dt').find_all('a')[-1].get_text() #获取书名 f = open('F:\\python file\\顶点小说\\'+ text_title+'77.txt', 'w', encoding='utf-8') chapter_name, contents, next_page_url = get_info(html) while next_page_url:print(time.ctime() + ';' + next_page_url + ';' + '正在打印' + chapter_name)f.write(chapter_name + '\n')f.write(contents)html = get_html(URL + next_page_url)f.write('\n')chapter_name, contents, next_page_url = get_info(html)time.sleep(np.random.rand()*1) f.close()if __name__ == '__main__':main()其实,我们还可以将header中的User-Agent进行随机切换,这样不容易被网站后台屏蔽。思路是生成一个随机数,在user_Agent列表中选择一个。4.最终版本
功能新增:动态变换请求头,处理网站章节重复的bug等。"""代码功能:给定顶点网站一部小说的第一章链接,自动下载全部小说内容,由于爬取速度较快目前还不能实现完全无人值守。可能由于网站无响应,爬虫死掉,需要重新运行(将上次短的链接喂进程序即可)。"""import requestsimport timeimport randomimport numpy as npfrom bs4 import BeautifulSoup as bsURL = 'https://www.x23us.com'user_agent_list = ["Mozilla/5.0 (Linux; U; Android 5.1; zh-cn; m1 metal Build/LMY47I) AppleWebKit/537.36 (KHTML, like Gecko)Version/4.0 Chrome/37.0.0.0 MQQBrowser/7.6 Mobile Safari/537.36","Mozilla/5.0 (Linux; Android 6.0; MP1512 Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/35.0.1916.138 Mobile Safari/537.36 T7/7.4 baiduboxapp/8.4 (Baidu; P1 6.0)","Mozilla/5.0 (Linux; Android 6.0.1; vivo X9Plus Build/MMB29M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/48.0.2564.116 Mobile Safari/537.36 baiduboxapp/8.6.5 (Baidu; P1 6.0.1)","Mozilla/5.0 (iPhone 6s; CPU iPhone OS 10_3_1 like Mac OS X) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.0 MQQBrowser/7.6.0 Mobile/14E304 Safari/8536.25 MttCustomUA/2 QBWebViewType/1 WKType/1","Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1","Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.2; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; InfoPath.2)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0 Zune 3.0)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; MS-RTC LM 8)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; MS-RTC LM 8)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET CLR 4.0.20402; MS-RTC LM 8)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET CLR 1.1.4322; InfoPath.2)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Tablet PC 2.0)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET CLR 3.0.04506; Media Center PC 5.0; SLCC1)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Tablet PC 2.0; .NET CLR 3.0.04506; Media Center PC 5.0; SLCC1)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; FDM; Tablet PC 2.0; .NET CLR 4.0.20506; OfficeLiveConnector.1.4; OfficeLivePatch.1.3)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET CLR 3.0.04506; Media Center PC 5.0; SLCC1; Tablet PC 2.0)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET CLR 1.1.4322; InfoPath.2)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.3029; Media Center PC 6.0; Tablet PC 2.0)','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; Media Center PC 3.0; .NET CLR 1.0.3705; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.1)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; FDM; .NET CLR 1.1.4322)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; .NET CLR 1.1.4322; InfoPath.1; .NET CLR 2.0.50727)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; .NET CLR 1.1.4322; InfoPath.1)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; .NET CLR 1.1.4322; Alexa Toolbar; .NET CLR 2.0.50727)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; .NET CLR 1.1.4322; Alexa Toolbar)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.40607)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; .NET CLR 1.1.4322)','Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.1; .NET CLR 1.0.3705; Media Center PC 3.1; Alexa Toolbar; .NET CLR 1.1.4322; .NET CLR 2.0.50727)','Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; en-US)','Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; el-GR)','Mozilla/5.0 (MSIE 7.0; Macintosh; U; SunOS; X11; gu; SV1; InfoPath.2; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)','Mozilla/5.0 (compatible; MSIE 7.0; Windows NT 6.0; WOW64; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; c .NET CLR 3.0.04506; .NET CLR 3.5.30707; InfoPath.1; el-GR)','Mozilla/5.0 (compatible; MSIE 7.0; Windows NT 6.0; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; c .NET CLR 3.0.04506; .NET CLR 3.5.30707; InfoPath.1; el-GR)','Mozilla/5.0 (compatible; MSIE 7.0; Windows NT 6.0; fr-FR)','Mozilla/5.0 (compatible; MSIE 7.0; Windows NT 6.0; en-US)','Mozilla/5.0 (compatible; MSIE 7.0; Windows NT 5.2; WOW64; .NET CLR 2.0.50727)','Mozilla/4.79 [en] (compatible; MSIE 7.0; Windows NT 5.0; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 1.1.4322; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)','Mozilla/4.0 (Windows; MSIE 7.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727)','Mozilla/4.0 (Mozilla/4.0; MSIE 7.0; Windows NT 5.1; FDM; SV1; .NET CLR 3.0.04506.30)','Mozilla/4.0 (Mozilla/4.0; MSIE 7.0; Windows NT 5.1; FDM; SV1)','Mozilla/4.0 (compatible;MSIE 7.0;Windows NT 6.0)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0;)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; YPC 3.2.0; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; InfoPath.2; .NET CLR 3.5.30729; .NET CLR 3.0.30618)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; YPC 3.2.0; SLCC1; .NET CLR 2.0.50727; .NET CLR 3.0.04506)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; WOW64; SLCC1; Media Center PC 5.0; .NET CLR 2.0.50727)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; WOW64; SLCC1; .NET CLR 3.0.04506)','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; WOW64; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; InfoPath.2; .NET CLR 3.5.30729; .NET CLR 3.0.30618; .NET CLR 1.1.4322)',]# 获取网页内容def get_html(url,head="Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"):header_list = {'Accept': 'text/html, application/xhtml+xml, image/jxr, */*','Accept - Encoding': 'gzip, deflate,br','Accept-Language': 'zh-CN,zh;q=0.8','cookie': 'targetEncodingwww23uscom=2; Hm_lvt_534ede4b11a35873e104d2b5040935e0=1514605870,1514622659,1514625352; Hm_lpvt_534ede4b11a35873e104d2b5040935e0=1514637350','Connection': 'close','Host': 'www.x23us.com','User-Agent': head,}page = requests.get(url, headers=header_list)# print('-------------------------------\n')# print(header_list['User-Agent'])# print('-------------------------------\n')page.encoding = 'gbk'soup = bs(page.text, 'lxml')retua107rn soup# 获取初始链接def get_init_href(url):html = get_html(url)return url + html.find('table').find('tr').find('td').find('a')['href']def get_info(html):chapter_name = html.find('h1').get_text() # 获取章节名称contents_raw = html.find('dd', {'id': 'contents'})contents = contents_raw.get_text().replace(' ', '\n ').replace('顶点小说 X23US.COM更新最快', '') # 获取适合阅读的文本格式next_page_url = html.find('h3').find_all('a')[2]['href'] # 获取下一页链接return chapter_name, contents, next_page_urldef main():flag_url = 'https://www.x23us.com'chapter_list = set()url_list = [# 'https://www.x23us.com/html/67/67758/28836772.html',# 'https://www.x23us.com/html/68/68695/29468246.html',#魔妍天下'https://www.x23us.com/html/68/68967/',#从末世到古代'https://www.x23us.com/html/26/26365/'#护花状元在现代# 'https://www.x23us.com/html/23/23299/15399662.html']for url in url_list:# url = 'https://www.x23us.com/html/68/68814/29514271.html'#从本地读取# url = 'https://www.x23us.com/html/62/62401/25254525.html'html = get_html(url)text_title = html.find('dt').find_all('a')[-1].get_text().replace('简介','') # 获取书名,用于文件命名。f = open('F:\\python program\\顶点小说\\' + text_title + '1.txt', 'w', encoding='utf-8')try: # 如果给的不是小说第一章链接,则自动取出第一章链接作为初始爬虫链接chapter_name, contents, next_page_url = get_info(html)except:url = get_init_href(url)html = get_html(url)chapter_name, contents, next_page_url = get_info(html)while next_page_url:user_agent_index = random.randint(1, 10000) % len(user_agent_list) # 随机生成user_agent头信息。head = user_agent_list[user_agent_index]if chapter_name not in chapter_list: # 判断所爬章节是否已爬取,如果已经爬取则进行下一章节的爬取。print(time.ctime() + ';正在打印:' + text_title + '_____' + chapter_name)f.write('\n' + chapter_name + '\n')f.write(contents + '\n')chapter_list.add(chapter_name)try: # 判断是否爬取完毕,如果出现定位不到视为爬取结束。不排除其他情况造成的程序断开。html = get_html(URL + next_page_url, head)chapter_name, contents, next_page_url = get_info(html)except:if flag_url == next_page_url:breakprint("过滤掉一个异常网页")time.sleep(np.random.rand() * 3)f.close()if __name__ == '__main__':main()三、总结
这个程序还有很多优化的空间,目前来看还能正常运行,我已经爬了不少小说哦。实际上,爬虫过程会遇到很多客观因素,使得我们的爬虫脚本难以运行,这个时候我们需要进行优化甚至使用其他技术。目前来说,更新的案例都是静态网页的爬取,等把这几个案例更新完毕,就写动态网页爬取的案例。希望大家持续关注,多多交流。
相关文章推荐
- python3.6爬虫案例:爬取某网站PPT。
- python3.6爬虫案例:爬取朝秀帮图片
- python3.6爬虫案例:爬取百度歌单。
- python用字符串操作20行代码简单爬虫入门+案例(爬取一章《三体》小说)
- python 爬虫(正则表达式案例)
- Python 3.6 实现简单的爬虫
- Python爬虫模拟真实登录案例系列之十二
- 福利: 安卓上运行Python爬虫
- 【备忘】2017年最新Python网络爬虫实战案例视频教程下载 共5章 34课
- 【Python3.6爬虫学习记录】(四)爬取百度贴吧某帖子内容及图片
- Python爬虫(四):爬取136书屋小说,并保存至本地文本文件中,单进程多进程对比效率(以三生三世十里桃花为例)
- [python3.6]爬虫实战之爬取淘女郎图片
- Python网络爬虫实战案例之:7000本电子书下载(2)
- python 爬虫,抓取小说
- python2-.urlencode和贴吧小爬虫案例_recv
- 从零开始写Python爬虫 --- 1.7 爬虫实践: 排行榜小说批量下载
- Python爬虫实战之使用Scrapy爬起点网的完本小说
- python 案例:使用BeautifuSoup4的爬虫
- python用BeautifulSoup库简单爬虫入门+案例(爬取妹子图)
- python3.6爬虫需要安装的模块