采用Hibench进行大数据平台(CDH)基准性能测试
2018-03-07 15:27
323 查看
参考博客地址:http://blog.csdn.net/wenwenxiong/article/details/77628670
http://www.cnblogs.com/hellowcf/p/6912746.html
最近的项目要给客户部署一套大数据平台(CDH),因此要出一个关于平台本身的性能测试。对测试流程不太了解,相比于项目功能测试,这种平台本身测试感觉有点困难。查找资料了解到一个Hibench工具。这里结合其他博客资料自己做一个总结记录。
1、HiBench介绍
hibench作为一个测试hadoop的基准测试框架,提供了对于hive:(aggregation,scan,join),排序(sort,TeraSort),大数据基本算法(wordcount,pagerank,nutchindex),机器学习算法(kmeans,bayes),集群调度(sleep),吞吐(dfsio),以及新加入5.0版本的流测试,是一个测试大数据平台非常好用的工具
它支持的框架有:hadoopbench、sparkbench、stormbench、flinkbench、gearpumpbench。
hibench包含几个hadoop的负载
micro benchmarks
Sort:使用hadoop randomtextwriter生成数据,并对数据进行排序。
Wordcount:统计输入数据中每个单词的出现次数,输入数据使用hadoop randomtextwriter生成。
TeraSort:输入数据由hadoop teragen产生,通过key值进行排序。
hdfs benchmarks
增强行的dfsio:通过产生大量同时执行读写请求的任务测试hadoop机群的hdfs吞吐量
web search bench marks
Nutch indexing:大规模收索引擎,这个是负载测试nutch(apache的一个开源搜索引擎)的搜索子系统,使用自动生成的web数据,web数据中的连接和单词符合zipfian分布(一个单词出现的次数与它在频率表的排名成反比)
Pagerank:这个负载包含在一种在hadoop上的pagerank的算法实现,使用自动生成的web数据,web数据中的链接符合zipfian分布。(对于任意一个term其频度(frequency)的排名(rank)和frequency的乘积大致是一个常数)
machine learning benchmarks
Mahout bayesian classification(bayes):大规模机器学习,这个负载测试mahout(apache开源机器学习库)中的naive bayesian 训练器,输入的数据是自动生成的文档,文档中的单词符合zipfian分布。
Mahout k-means clustering(kmeans):测试mahout中的k-means聚类算法,输入的数据集由基于平均分布和高斯分布的genkmeansdataset产生。
data analytics benchmarks
Hive query benchmarks(hivebench):包含执行的典型olap查询的hive查询(aggregation和join),使用自动生成的web数据,web数据的链接符合zipfian分布。
2、下载Hibench
Github地址:https://github.com/intel-hadoop/HiBench
注意事项:1、Python 2.x(>=2.6) is required.
2、bc is required to generate the HiBench report.(如没有bc工具,执行yum install bc)
3、Supported Hadoop version: Apache Hadoop 2.x, CDH5.x, HDP
4、Build HiBench according to build HiBench.
5、Start HDFS, Yarn in the cluster.
3、编译Hibench
首先执行节点要安装maven,如没有,需要先安装这里我只对Hibench的hadoopbench和sparkbench框架进行了编译,也可以对某个需要测试模块进行编译:可以参考Github文档:https://github.com/intel-hadoop/HiBench/blob/master/docs/build-hibench.md
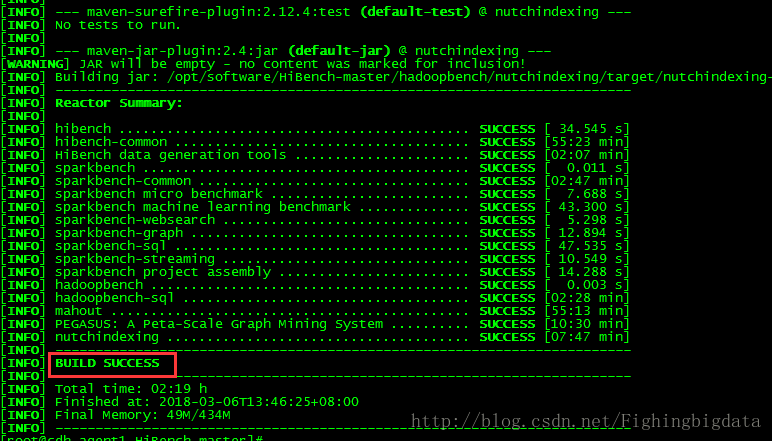
这里我还遇到了一个问题,当我执行HiBench-master/bin/build_all.sh,对全部框架进行编译时,报了如下错误:Downloading: https://repository.apache.org/content/repositories/releases/org/scalanlp/breeze_2.11/0.11.2/breeze_2.11-0.11.2.jar Downloaded: https://repository.apache.org/content/repositories/releases/org/apache/spark/spark-catalyst_2.11/2.0.0/spark-catalyst_2.11-2.0.0.jar (6610 KB at 36.5 KB/sec)
Downloading: https://oss.sonatype.org/content/groups/scala-tools/org/scalanlp/breeze_2.11/0.11.2/breeze_2.11-0.11.2.jar [INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] hibench ............................................ SUCCESS [ 22.978 s]
[INFO] hibench-common ..................................... SUCCESS [25:34 min]
[INFO] HiBench data generation tools ...................... SUCCESS [13:22 min]
[INFO] sparkbench ......................................... SUCCESS [ 0.010 s]
[INFO] sparkbench-common .................................. SUCCESS [34:39 min]
[INFO] sparkbench micro benchmark ......................... SUCCESS [ 24.707 s]
[INFO] sparkbench machine learning benchmark .............. FAILURE [45:05 min]
[INFO] sparkbench-websearch ............................... SKIPPED
[INFO] sparkbench-graph ................................... SKIPPED
[INFO] sparkbench-sql ..................................... SKIPPED
[INFO] sparkbench-streaming ............................... SKIPPED
[INFO] sparkbench project assembly ........................ SKIPPED
[INFO] flinkbench ......................................... SKIPPED
[INFO] flinkbench-streaming ............................... SKIPPED
[INFO] gearpumpbench ...................................... SKIPPED
[INFO] gearpumpbench-streaming ............................ SKIPPED
[INFO] hadoopbench ........................................ SKIPPED
[INFO] hadoopbench-sql .................................... SKIPPED
[INFO] mahout ............................................. SKIPPED
[INFO] PEGASUS: A Peta-Scale Graph Mining System .......... SKIPPED
[INFO] nutchindexing ...................................... SKIPPED
[INFO] stormbench ........................................
4000
. SKIPPED
[INFO] stormbench-streaming ............................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:59 h
[INFO] Finished at: 2018-03-06T17:30:35+08:00
[INFO] Final Memory: 39M/367M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project sparkbench-ml: Could not resolve dependencies for project com.intel.hibench.sparkbench:sparkbench-ml:jar:7.1-SNAPSHOT: Could not transfer artifact org.scalanlp:breeze_2.11:jar:0.11.2 from/to central (https://repo1.maven.org/maven2): GET request of: org/scalanlp/breeze_2.11/0.11.2/breeze_2.11-0.11.2.jar from central failed: Premature end of Content-Length delimited message body (expected: 13448966; received: 11968982 -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException [ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :sparkbench-ml
由于storm GP框架模块我的大数据平台没有使用,也就没有继续跟踪这个错误,执行执行上面的编译命令了。
4、修改配置
进入conf目录:cp hadoop.conf.template hadoop.conf修改conf/hadoop.conf文件:[root@cdh-agent1 conf]# vi hadoop.conf
# Hadoop home
hibench.hadoop.home /opt/cloudera/parcels/CDH/lib/hadoop
# The path of hadoop executable
hibench.hadoop.executable ${hibench.hadoop.home}/bin/hadoop
# Hadoop configraution directory
hibench.hadoop.configure.dir ${hibench.hadoop.home}/etc/hadoop
# The root HDFS path to store HiBench data 这里就是生成测试数据存放的hdfs负目录,注意要有写权限
hibench.hdfs.master hdfs://10.x.x.x:8020/user/hibench
# Hadoop release provider. Supported value: apache, cdh5, hdp
hibench.hadoop.release cdh5这里以wordcount为例,conf/benchmarks.lst 测试项目
conf/frameworks.lst 配置语言,这两个文件可以不作修改即可。
在conf/hibench.conf文件中配置了一些测试的相关参数,比如MR并行度,报告路径,名称等。
其中hibench.scale.profile为对应的生成的数据量大小,他的值对应于conf/workloads/micro/wordcount.conf中设置的数值。[root@cdh-agent1 conf]# cat hibench.conf
# Data scale profile. Available value is tiny, small, large, huge, gigantic and bigdata.
# The definition of these profiles can be found in the workload's conf file i.e. conf/workloads/micro/wordcount.conf
hibench.scale.profile huge
# Mapper number in hadoop, partition number in Spark
hibench.default.map.parallelism 8
# Reducer nubmer in hadoop, shuffle partition number in Spark
hibench.default.shuffle.parallelism 8
#======================================================
# Report files
#======================================================
# default report formats
hibench.report.formats "%-12s %-10s %-8s %-20s %-20s %-20s %-20s\n"
# default report dir path
hibench.report.dir ${hibench.home}/report
# default report file name
hibench.report.name hibench.report
# input/output format settings. Available formats: Text, Sequence.
sparkbench.inputformat Sequence
sparkbench.outputformat Sequence
# hibench config folder
hibench.configure.dir ${hibench.home}/conf进入conf/workloads/micro/,wordcount.conf文件配置的是生成的数据量大小[root@cdh-agent1 micro]# more wordcount.conf
#datagen
hibench.wordcount.tiny.datasize 32000
hibench.wordcount.small.datasize 320000000
hibench.wordcount.large.datasize 3200000000
hibench.wordcount.huge.datasize 32000000000
hibench.wordcount.gigantic.datasize 320000000000
hibench.wordcount.bigdata.datasize 1600000000000
hibench.workload.datasize ${hibench.wordcount.${hibench.scale.profile}.datasize}
# export for shell script
hibench.workload.input ${hibench.hdfs.data.dir}/Wordcount/Input
hibench.workload.output ${hibench.hdfs.data.dir}/Wordcount/Output5、执行测试脚本
在bin/run_all.sh 该脚本为测试所有的测试基准模块(将运行所有在conf/benchmarks.lst和conf/frameworks.lst中的workloads);
这里还是以wordcount为例,
①生成测试数据 bin/workloads/micro/wordcount/prepare/prepare.sh
②运行wordcount测试例子 bin/workloads/micro/wordcount/hadoop/run.sh
③生成的测试数据在conf/hadoop.conf中hibench.hdfs.master项配置,我的是在/user/hibench/HiBench目录下
6、查看测试报告
测试报告位置:report/hibench.report[root@cdh-agent1 report]# cat hibench.report
Type Date Time Input_data_size Duration(s) Throughput(bytes/s) Throughput/node
HadoopWordcount 2018-03-07 09:53:15 35891 43.457 825 825
HadoopWordcount 2018-03-07 10:21:22 3284906140 283.518 11586234 11586234
HadoopSort 2018-03-07 10:41:19 328492770 49.502 6635949 6635949
HadoopJoin 2018-03-07 14:08:00 1919260193 264.432 7258048 7258048 7、补充
在bin/workloads目录下:对应着不同的大数据测试点,比如sql、ml、graph、streaming等[root@cdh-agent1 bin]# cd workloads/
[root@cdh-agent1 workloads]# ll
总用量 24
drwxr-xr-x 3 root root 4096 3月 6 14:45 graph
drwxr-xr-x 7 root root 4096 3月 6 14:45 micro
drwxr-xr-x 13 root root 4096 3月 6 14:45 ml
drwxr-xr-x 5 root root 4096 3月 6 14:45 sql
drwxr-xr-x 6 root root 4096 3月 6 14:46 streaming
drwxr-xr-x 4 root root 4096 3月 6 14:46 websearch进入这些目录后:有对应不同的测试小项目,根据大数据平台需要,对其进行相应的测试。[root@cdh-agent1 workloads]# cd micro/
[root@cdh-agent1 micro]# ll
总用量 20
drwxr-xr-x 4 root root 4096 3月 6 14:45 dfsioe
drwxr-xr-x 5 root root 4096 3月 6 14:45 sleep
drwxr-xr-x 5 root root 4096 3月 6 14:45 sort
drwxr-xr-x 5 root root 4096 3月 6 14:45 terasort
drwxr-xr-x 5 root root 4096 3月 6 14:45 wordcount这里的测试结果包括只有文件描述,不知道是否可以生成相应的图表类报告,更方便直观查看集群性能,如果有其他同行了解,可以留言交流,谢谢!
http://www.cnblogs.com/hellowcf/p/6912746.html
最近的项目要给客户部署一套大数据平台(CDH),因此要出一个关于平台本身的性能测试。对测试流程不太了解,相比于项目功能测试,这种平台本身测试感觉有点困难。查找资料了解到一个Hibench工具。这里结合其他博客资料自己做一个总结记录。
1、HiBench介绍
hibench作为一个测试hadoop的基准测试框架,提供了对于hive:(aggregation,scan,join),排序(sort,TeraSort),大数据基本算法(wordcount,pagerank,nutchindex),机器学习算法(kmeans,bayes),集群调度(sleep),吞吐(dfsio),以及新加入5.0版本的流测试,是一个测试大数据平台非常好用的工具
它支持的框架有:hadoopbench、sparkbench、stormbench、flinkbench、gearpumpbench。
hibench包含几个hadoop的负载
micro benchmarks
Sort:使用hadoop randomtextwriter生成数据,并对数据进行排序。
Wordcount:统计输入数据中每个单词的出现次数,输入数据使用hadoop randomtextwriter生成。
TeraSort:输入数据由hadoop teragen产生,通过key值进行排序。
hdfs benchmarks
增强行的dfsio:通过产生大量同时执行读写请求的任务测试hadoop机群的hdfs吞吐量
web search bench marks
Nutch indexing:大规模收索引擎,这个是负载测试nutch(apache的一个开源搜索引擎)的搜索子系统,使用自动生成的web数据,web数据中的连接和单词符合zipfian分布(一个单词出现的次数与它在频率表的排名成反比)
Pagerank:这个负载包含在一种在hadoop上的pagerank的算法实现,使用自动生成的web数据,web数据中的链接符合zipfian分布。(对于任意一个term其频度(frequency)的排名(rank)和frequency的乘积大致是一个常数)
machine learning benchmarks
Mahout bayesian classification(bayes):大规模机器学习,这个负载测试mahout(apache开源机器学习库)中的naive bayesian 训练器,输入的数据是自动生成的文档,文档中的单词符合zipfian分布。
Mahout k-means clustering(kmeans):测试mahout中的k-means聚类算法,输入的数据集由基于平均分布和高斯分布的genkmeansdataset产生。
data analytics benchmarks
Hive query benchmarks(hivebench):包含执行的典型olap查询的hive查询(aggregation和join),使用自动生成的web数据,web数据的链接符合zipfian分布。
2、下载Hibench
Github地址:https://github.com/intel-hadoop/HiBench
注意事项:1、Python 2.x(>=2.6) is required.
2、bc is required to generate the HiBench report.(如没有bc工具,执行yum install bc)
3、Supported Hadoop version: Apache Hadoop 2.x, CDH5.x, HDP
4、Build HiBench according to build HiBench.
5、Start HDFS, Yarn in the cluster.
3、编译Hibench
首先执行节点要安装maven,如没有,需要先安装这里我只对Hibench的hadoopbench和sparkbench框架进行了编译,也可以对某个需要测试模块进行编译:可以参考Github文档:https://github.com/intel-hadoop/HiBench/blob/master/docs/build-hibench.md
mvn -Phadoopbench -Psparkbench -Dspark=1.6 -Dscala=2.10 clean package
这里我还遇到了一个问题,当我执行HiBench-master/bin/build_all.sh,对全部框架进行编译时,报了如下错误:Downloading: https://repository.apache.org/content/repositories/releases/org/scalanlp/breeze_2.11/0.11.2/breeze_2.11-0.11.2.jar Downloaded: https://repository.apache.org/content/repositories/releases/org/apache/spark/spark-catalyst_2.11/2.0.0/spark-catalyst_2.11-2.0.0.jar (6610 KB at 36.5 KB/sec)
Downloading: https://oss.sonatype.org/content/groups/scala-tools/org/scalanlp/breeze_2.11/0.11.2/breeze_2.11-0.11.2.jar [INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] hibench ............................................ SUCCESS [ 22.978 s]
[INFO] hibench-common ..................................... SUCCESS [25:34 min]
[INFO] HiBench data generation tools ...................... SUCCESS [13:22 min]
[INFO] sparkbench ......................................... SUCCESS [ 0.010 s]
[INFO] sparkbench-common .................................. SUCCESS [34:39 min]
[INFO] sparkbench micro benchmark ......................... SUCCESS [ 24.707 s]
[INFO] sparkbench machine learning benchmark .............. FAILURE [45:05 min]
[INFO] sparkbench-websearch ............................... SKIPPED
[INFO] sparkbench-graph ................................... SKIPPED
[INFO] sparkbench-sql ..................................... SKIPPED
[INFO] sparkbench-streaming ............................... SKIPPED
[INFO] sparkbench project assembly ........................ SKIPPED
[INFO] flinkbench ......................................... SKIPPED
[INFO] flinkbench-streaming ............................... SKIPPED
[INFO] gearpumpbench ...................................... SKIPPED
[INFO] gearpumpbench-streaming ............................ SKIPPED
[INFO] hadoopbench ........................................ SKIPPED
[INFO] hadoopbench-sql .................................... SKIPPED
[INFO] mahout ............................................. SKIPPED
[INFO] PEGASUS: A Peta-Scale Graph Mining System .......... SKIPPED
[INFO] nutchindexing ...................................... SKIPPED
[INFO] stormbench ........................................
4000
. SKIPPED
[INFO] stormbench-streaming ............................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:59 h
[INFO] Finished at: 2018-03-06T17:30:35+08:00
[INFO] Final Memory: 39M/367M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project sparkbench-ml: Could not resolve dependencies for project com.intel.hibench.sparkbench:sparkbench-ml:jar:7.1-SNAPSHOT: Could not transfer artifact org.scalanlp:breeze_2.11:jar:0.11.2 from/to central (https://repo1.maven.org/maven2): GET request of: org/scalanlp/breeze_2.11/0.11.2/breeze_2.11-0.11.2.jar from central failed: Premature end of Content-Length delimited message body (expected: 13448966; received: 11968982 -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException [ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :sparkbench-ml
由于storm GP框架模块我的大数据平台没有使用,也就没有继续跟踪这个错误,执行执行上面的编译命令了。
4、修改配置
进入conf目录:cp hadoop.conf.template hadoop.conf修改conf/hadoop.conf文件:[root@cdh-agent1 conf]# vi hadoop.conf
# Hadoop home
hibench.hadoop.home /opt/cloudera/parcels/CDH/lib/hadoop
# The path of hadoop executable
hibench.hadoop.executable ${hibench.hadoop.home}/bin/hadoop
# Hadoop configraution directory
hibench.hadoop.configure.dir ${hibench.hadoop.home}/etc/hadoop
# The root HDFS path to store HiBench data 这里就是生成测试数据存放的hdfs负目录,注意要有写权限
hibench.hdfs.master hdfs://10.x.x.x:8020/user/hibench
# Hadoop release provider. Supported value: apache, cdh5, hdp
hibench.hadoop.release cdh5这里以wordcount为例,conf/benchmarks.lst 测试项目
conf/frameworks.lst 配置语言,这两个文件可以不作修改即可。
在conf/hibench.conf文件中配置了一些测试的相关参数,比如MR并行度,报告路径,名称等。
其中hibench.scale.profile为对应的生成的数据量大小,他的值对应于conf/workloads/micro/wordcount.conf中设置的数值。[root@cdh-agent1 conf]# cat hibench.conf
# Data scale profile. Available value is tiny, small, large, huge, gigantic and bigdata.
# The definition of these profiles can be found in the workload's conf file i.e. conf/workloads/micro/wordcount.conf
hibench.scale.profile huge
# Mapper number in hadoop, partition number in Spark
hibench.default.map.parallelism 8
# Reducer nubmer in hadoop, shuffle partition number in Spark
hibench.default.shuffle.parallelism 8
#======================================================
# Report files
#======================================================
# default report formats
hibench.report.formats "%-12s %-10s %-8s %-20s %-20s %-20s %-20s\n"
# default report dir path
hibench.report.dir ${hibench.home}/report
# default report file name
hibench.report.name hibench.report
# input/output format settings. Available formats: Text, Sequence.
sparkbench.inputformat Sequence
sparkbench.outputformat Sequence
# hibench config folder
hibench.configure.dir ${hibench.home}/conf进入conf/workloads/micro/,wordcount.conf文件配置的是生成的数据量大小[root@cdh-agent1 micro]# more wordcount.conf
#datagen
hibench.wordcount.tiny.datasize 32000
hibench.wordcount.small.datasize 320000000
hibench.wordcount.large.datasize 3200000000
hibench.wordcount.huge.datasize 32000000000
hibench.wordcount.gigantic.datasize 320000000000
hibench.wordcount.bigdata.datasize 1600000000000
hibench.workload.datasize ${hibench.wordcount.${hibench.scale.profile}.datasize}
# export for shell script
hibench.workload.input ${hibench.hdfs.data.dir}/Wordcount/Input
hibench.workload.output ${hibench.hdfs.data.dir}/Wordcount/Output5、执行测试脚本
在bin/run_all.sh 该脚本为测试所有的测试基准模块(将运行所有在conf/benchmarks.lst和conf/frameworks.lst中的workloads);
这里还是以wordcount为例,
①生成测试数据 bin/workloads/micro/wordcount/prepare/prepare.sh
②运行wordcount测试例子 bin/workloads/micro/wordcount/hadoop/run.sh
③生成的测试数据在conf/hadoop.conf中hibench.hdfs.master项配置,我的是在/user/hibench/HiBench目录下
6、查看测试报告
测试报告位置:report/hibench.report[root@cdh-agent1 report]# cat hibench.report
Type Date Time Input_data_size Duration(s) Throughput(bytes/s) Throughput/node
HadoopWordcount 2018-03-07 09:53:15 35891 43.457 825 825
HadoopWordcount 2018-03-07 10:21:22 3284906140 283.518 11586234 11586234
HadoopSort 2018-03-07 10:41:19 328492770 49.502 6635949 6635949
HadoopJoin 2018-03-07 14:08:00 1919260193 264.432 7258048 7258048 7、补充
在bin/workloads目录下:对应着不同的大数据测试点,比如sql、ml、graph、streaming等[root@cdh-agent1 bin]# cd workloads/
[root@cdh-agent1 workloads]# ll
总用量 24
drwxr-xr-x 3 root root 4096 3月 6 14:45 graph
drwxr-xr-x 7 root root 4096 3月 6 14:45 micro
drwxr-xr-x 13 root root 4096 3月 6 14:45 ml
drwxr-xr-x 5 root root 4096 3月 6 14:45 sql
drwxr-xr-x 6 root root 4096 3月 6 14:46 streaming
drwxr-xr-x 4 root root 4096 3月 6 14:46 websearch进入这些目录后:有对应不同的测试小项目,根据大数据平台需要,对其进行相应的测试。[root@cdh-agent1 workloads]# cd micro/
[root@cdh-agent1 micro]# ll
总用量 20
drwxr-xr-x 4 root root 4096 3月 6 14:45 dfsioe
drwxr-xr-x 5 root root 4096 3月 6 14:45 sleep
drwxr-xr-x 5 root root 4096 3月 6 14:45 sort
drwxr-xr-x 5 root root 4096 3月 6 14:45 terasort
drwxr-xr-x 5 root root 4096 3月 6 14:45 wordcount这里的测试结果包括只有文件描述,不知道是否可以生成相应的图表类报告,更方便直观查看集群性能,如果有其他同行了解,可以留言交流,谢谢!

相关文章推荐
- 使用历史压力测试数据对系统平台升级改造进行系统性能规划
- 《使用云计算和大数据进行性能测试》
- 采用badboy和Jmeter进行性能测试
- 《使用云计算和大数据进行性能测试》
- 编写一个使用数组类模板Array对数组进行排序、求最大值和求元素和的程序,并采用相关数据进行测试。
- Android操作系统移植运行UnixBench进行基准性能测试
- 6.对数组进行排序、求最大值和求元素和的函数采用静态成员函数的方式封装成数组算法类模板ArrayAlg,并采用相关数据进行测试。
- 对数组进行排序、求最大值和求元素和的算法都编写为函数模板,采用相关数据进行测试。
- 大数据测试学习笔记之基准测试HiBench
- 采用YCSB对Hbase进行性能测试
- 编写一个使用数组类模板Array对数组进行排序、求最大值和求元素和的程序,并采用相关数据进行测试。
- phoenixframe自动化平台使用多批次数据进行接口测试的示例
- 【技术员的工具箱】四步十分钟生成一千万条数据进行性能测试
- 干货分享:SparkBench--Spark平台的基准性能测试
- 网络游戏之性能测试规划(二)——如何建立有效的基准数据及环境(拟稿)
- 采用badboy和Jmeter进行性能测试
- 对数组进行排序、求最大值和求元素和的算法都编写为函数模板,采用相关数据进行测试
- 对数组进行排序、求最大值和求元素和的算法都编写为函数模板,采用相关数据进行测试。
- 【软件性能测试-LoadRunner实战技能 4】== 监控指标数据分析
- YDB与spark SQL在百亿级数据上的性能对比测试