吴恩达深度学习第一课第二周
2018-03-05 22:49
274 查看
第二周 神经网络基础
打卡(1)
2.1 二分类
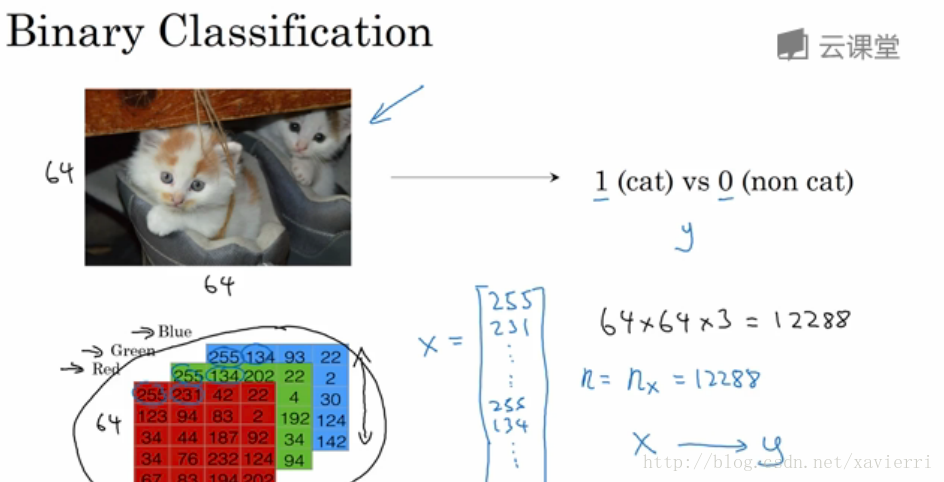
在二分分类问题中 目标是训练处一个分类器,它以图片(本例中)的特征向量X作为输入,来预测输出的结果标签y是1还是0,也就是预测图片中是否有猫。课程中会用到的数学符号:
(x,y)(x,y):表示一个单独的样本;x∈Rnxx∈Rnx:表示x是nxnx维的特征向量;
y∈y∈{0, 1} :标签y值为0或1;
训练集有m个训练样本构成:(x(1),y(1))(x(1),y(1))表示样本一的输入和输出;(x(2),y(2))(x(2),y(2))表示样本二的输入和输出…(x(m),y(m))(x(m),y(m)),这些样本整个一起就表示训练集,m表示训练样本的个数。m=mtrain(训练集),m=mtest(测试集)m=mtrain(训练集),m=mtest(测试集);
神经网络中构建的输入矩阵XX中,通常行表示样本数; 列表示特征维度。

2.2 logistic回归

(向量ww一般默认为列向量,转置为行向量)
* sigmoid函数的函数值∈∈{0,1},且当自变量趋近负无穷大时,函数值趋近为0; 当自变量趋近为正无穷大是,函数值趋近为1.
* 神经网络中,特征参数向量ww和截距bb通常看做独立的参数,不像红色公式中那样表达会更好(红色公式在本课程中不会使用)
2.3 logistic回归损失函数

logistic的损失函数是:−(ylogŷ +(1−y)log(1−ŷ ))−(ylogy^+(1−y)log(1−y^)) (logistic的损失函数之所以不用12(ŷ −y)212(y^−y)2是因为这个损失函数在使用梯度下降法时可能会产生非凸优化问题)。
* 损失函数适用于单个训练样本;而成本函数是基于参数的总成本,在训练logistic模型时,我们要找到合适的参数ww和bb,就是找到让的成本函数JJ尽可能小的ww和bb。
打卡(2)
2.4 梯度下降法

通过梯度下降法求解使得成本函数最小的参数向量ww和截距bb。

* 编写代码时ww的对J(w,b)J(w,b)的偏微分用dwdw表示,bb的偏微分用dbdb表示
2.5 导数
(略)2.6 更多的导数例子
(略)2.7 流程图

* 流程图是用蓝色箭头画出来的,从左到右的计算
* 流程图的导数是用红色箭头画出来的,从右到左
2.8 流程图的导数计算(反向传播)

2.9 logistic回归中的梯度下降

* "dz"=dlda∗dadz"dz"=dlda∗dadz,
其中,
a=σ(z)=11+e−za=σ(z)=11+e−z
dadz=e−z(1+e−z)2=1(1+e−z)(1−11+e−z)=a(1−a)dadz=e−z(1+e−z)2=1(1+e−z)(1−11+e−z)=a(1−a)
"dz"=a−ya(1−a)∗a(1−a)=a−y"dz"=a−ya(1−a)∗a(1−a)=a−y
打卡(3)
2.10 m个样本的梯度下降


2.11 向量化
Z=wTx+bZ=wTx+b,其中,w,xw,x都是列向量;
代码表示为:
z=np.dot(w,x)
import numpy as np a=np,array([1,2,3,4]) print(a) >>>[1 2 3 4]
import time
a= np.random.rand(1000000)
b= np.random.rand(1000000)
tic=time.time()
tic=np.dot(a,b)
toc=time.time()
print("vectorized version:"+str(1000*(toc-tic))+"ms")向量化计算,比循环遍历计算速度快很多。
SIMD:并行计算(在GPU和CPU都行)
2.12 向量化的更多例子
Python中实现将V=[v1,...,vn]TV=[v1,...,vn]T,转换成
U=[ev1,...,evn]TU=[ev1,...,evn]T,可以用向量化方法(避免循环遍历)。
import numpy as np u=np.exp(v) np.log(v) np.abd(v) np.maxnum(v,0) v**2 #v中的每个元素平方 1/v #v中的每个元素的导数
2.13 向量化logistic回归

2.14 向量化logitici回归的梯度计算


2.15 python中的广播
(略)2.16 关于Python/numpy向量说明
编写神经网络程序是,最好不要用1维数组,用矩阵a=np.random.randn(5) a.shape >>>>(5,) #这不属于矩阵
创建向量时,把向量定义为列向量易于运算
a=np.random.randn(5,1) a.shape >>>>(5,1) #列向量 assert(a.shape==(5,1)) 声明矩阵的维度
2.17 Jupter/Ipython笔记本的快速指南
(略)2.18 logistic损失函数的解释
损失函数:
成本函数:


相关文章推荐
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Logistic Regression with a Neural Network mindset
- 吴恩达Coursera深度学习课程 DeepLearning第一课第二周编程作业
- Coursera 深度学习 deep learning.ai 吴恩达 神经网络和深度学习 第一课 第二周 编程作业 Python Basics with Numpy
- 吴恩达深度学习课程第一课第二周课程作业
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Neural Network Basics Quiz, 10 questions
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第二周课后习题 Python Basics with numpy (optional)
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第四周课后习题 Deep Neural Network - Application v3
- Emojify - v2 吴恩达老师深度学习第五课第二周编程作业2
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第三周课后习题 Shallow Neural Networks Quiz, 10 questions
- Coursera deep learning 吴恩达 神经网络和深度学习 第二周 编程作业 Logistic Regression with a Neural Network mindset
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第四周课后习题 Building your Deep Neural Network - Step by Step v5
- 【中文】【吴恩达课后编程作业】Course 1 - 神经网络和深度学习 - 第二周作业
- 吴恩达深度学习第一课第四周(深层神经网络)
- Operations on word vectors-v2 吴恩达老师深度学习课程第五课第二周编程作业1
- 吴恩达深度学习卷积神经网络第二周作业1
- 吴恩达-深度学习-神经网络和深度学习-第二周
- 吴恩达深度学习第一课第四周课后作业2参考
- 吴恩达深度学习卷积神经网络第二周作业2
- 吴恩达深度学习第一课第一周
- coursera 吴恩达 -- 第一课 神经网络和深度学习 :第三周课后习题 Planar data classification with a hidden layer