python Spider Man(爬虫侠)二,之百度翻译小程序
2018-03-05 22:04
302 查看
from urllib import request,parse
import json
def fanyi(msg):
data = {
'kw':content
}
data = parse.urlencode(data)#把字典改成kw=content 这种
basr_url = 'http://fanyi.baidu.com/sug'
headers = {
"Content-Length": len(data), # 动态计算data长度 根据请求头的需要
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"
}
req= request.Request(url=basr_url,data=bytes(data,encoding='utf-8'),headers=headers)
resp = request.urlopen(req).read()
html =resp.decode('utf-8')
json_Data = json.loads(html)
print(json_Data)for itm in json_Data['data']: print(itm['k'],itm['v'])
if __name__ == '__main__':
content = input('请输入您要翻译的内容:')
fanyi(content)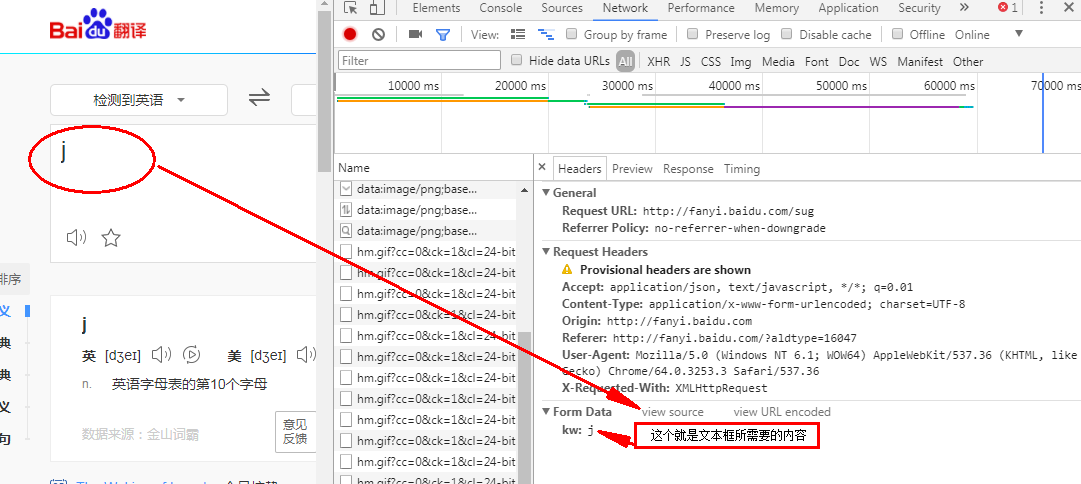

相关文章推荐
- Python3--批量爬取数据之调用百度api进行翻译
- python开发翻译程序
- 用Python 爬虫写翻译,查词程序
- 翻译软件(用百度的API实现)Python
- [Python设计模式] 第17章 程序中的翻译官——适配器模式
- python Spider Man(爬虫侠)三,之cookie进行人人网页面爬取
- python3爬虫攻略(5):翻译程序打包及代码优化
- Python爬虫之从简单的翻译程序说起
- 用python实现百度翻译的示例代码
- python第三个小程序,终于学到爬虫了~~~,利用有道,爬出个在线翻译小程序~~~~~
- Python3.5.1 百度翻译代码
- python--利用有道网址编写一个翻译句子的程序
- [Python]通过调用百度翻译API实现的翻译小程序
- Caffe for Python 官方教程(翻译) ----我的第一个caffe程序
- 百度通用翻译技术(二)----程序demo
- 实践项目五:python调用百度API实现自动检测翻译
- Python 通过 百度 rest 进行 语音翻译成中文文字。
- python3爬虫攻略(4):简单的翻译程序
- python与百度翻译实现简单词典
- 【翻译】七个习惯提高Python程序的性能